

6.3. Невзвешенное объединение результатов количественного опре- деления
Наиболее простым способом объединения n' оценок для значений М при n' коичественных определениях, является вычисление среднего значения и оценка стандартного отклонения по формуле
s2, =— — (6.3.-1)
м n'(n' -1)
а доверительный интервал
M ± tSM (6.3.-2)
где t имеет (n'-1) степеней свободы. Число n' оценок значений М обычно мало, а значение t, соответсвенно, довольно велико.
6.4. Пример определения взешенной средней активности с доверительн1м интервалом
В таблице 6.4.-1 приведено шесть независимых оценок активности одного и того же препарата, а также их доверительные интервалы и число степеней свободы для их дисперсий ошибки. Условия 1,2 и 3, приведенные в Разделе 6.2., выполнены. Натуральный логарифм активностей и веса рассчитаны, как описано в Разделе 6.2.
Оценки
активностей и доверительные интервалы
шесит независимых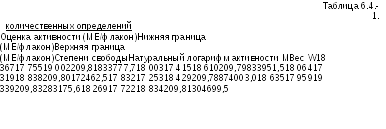
Взвешенную среднюю активность вычисляют по формуле 6.2.3.-2, в результате получают значение 9,8085.
По формуле 6.2.3.-2 рассчитывают стандартное отклонение, равное 0,00673, а по формуле 6.2.3.-3 вычисляют 95% доверительный интервал 9,7951 - 9,8218, где t имеет 120 степеней свободы.
Взяв антилогарифм, получают значение активности, равное 18187 МЕ/флакон при 95% доверительном интервале от 17946 до 18431 МЕ/флакон.
7. Дополнение
Невозможно дать исчерпывающий обзор статистических методов, используемых при проведении фармакопейных исследований. Тем не менее методы, изложенные в данной статье, удовлетворяют требованиям большинства фармакопейных целей. В данном разделе сделана попытка представить более абстрактный обзор альтернативных или наиболее общих методов статистического анализа. Заинтересованные лица могут также обратиться к специальной литературе по этой теме. В случае использования более специализированных методов статистического анализа, следует обратиться за помощью к квалифицированным специалистам.
7.1. Общие линейные модели
Методы, изложенные в данной статье, могут быть описаны в рамках общих линейных моделей (или обобщенных линейных моделей для того, чтобы включить методы пробит и логит-анализа). Принцип основан на построении линейной матрицы структуры Х (или матрицы планирования), в которой каждая строка представляет результаты наблюдения, а каждый столбец - один из линейных факторов (препарат, блок, столбец, дозу). Например, в случае схемы латинского квадрата, рассмотренной в Разделе 5.1.2, такая матрица состояла бы из 36 строк и 13 столбцов. По одному столбцу на каждый из препаратов, один столбец для доз, пять столбцов на каждый из блоков, за исключением первого, и пять столбцов для каждой строки, за исключением первой. Все столбцы , за исключением одного для доз, заполняют 0 или 1 в зависимости от того, связано данное наблюдение с данным фактором или нет. Вектор Y заполняют результатами наблюдений (преобразованными). Искомые параметры вычисляют по формуле (XtX)'1XtY, после чего оценка активности m может быть легко получена как от
ношение соответствующих параметров. Доверительные интервалы рассчитываются на основе теоремы Филлера (Fieller):
gv12 ^ ts
m
- 12
±
V12^ v22
Г
v11
v22
( „2
b
V11 - 2mvi2 + m2V22 - g
(1 - g)
22
t s vu22
mL,mu
где :
g 2 b2
а v11; v22 - множители дисперсии знаменателя и числителя, соответственно; v12 - множитель ковариации. Эти множители можно непосредственно вычислить из матрицы (XtX)-1, или косвенным методом, приняв во внимание, что Var(a1-a2)=Var(a1)+Var(a2)-2Cov(a1,a2), а Cov(a1-a2,b)=Cov(a1,b)-Cov(a2,b).
Полный дисперсионный анализ с полным разделением компонентов более сложен, поскольку он предполагает пересмотр матрицы X, к которой при этом дополняются столбцы для ослабления предположений о параллельности и линейности, после чего может быть проверена гипотеза о линейности. В случае количественных определений, зависящих от альтернативных эффектов, факторы линейности (точки пересечения с осью ординат as, aT и т.д. общий угловой коэффициент b) находят путем максимизации суммы по группам препаратов nl^(a/+bx)+(n-r)ln(1^(a,+bx)), где x - натуральный логарифм дозы (/п(доза)), Ф - определяет форму распределения, / e{S,T,...}.
НЕОДНОРОДНОСТЬ ДИСПЕРСИИ
Проблема неоднородности дисперсии не всегда может быть решена путем простого преобразования результатов. В этом случае один из возможных способов решения данной проблемы состоит в применении метода взвешенной линейной регрессии. Чтобы получить объективную оценку, веса результатов наблюдений берутся как величины обратно пропорциональные дисперсии ошибок. Так как истинное значение дисперсии ошибок не всегда известно, веса могут подбираться с использованием линейной итеративной процедуры. Однако при расчете доверительных интервалов при этом возникают дополнительные проблемы.
ВЫБРОСЫ И УСТОЙЧИВОСТЬ МЕТОДОВ В РАБОТЕ (РОБАСТНОСТЬ)
Недостатком метода наименьших квадратов, описанного в данном приложении, является его довольно высокая чувствительность к резко отклоняющимся от среднего данным. Очевидный выброс может целиком исказить результаты вычислений. Эту проблему часто решают путем исключения выбросов из набора данных. Такой подход может привести к субъективному исключению данных - не всегда корректному и безопасному. Довольно сложно дать общие рекомендации, касающиеся решения относительно того является ли конкретный результат наблюдения выбросом или нет, и с этим связано появление и развитие ряда робастных (устойчивых в работе) методов анализа. Эти методы менее чувствительны к выбросам, за счет того, что результатам, которые в большей мере отличаются от прогнозируемого значения, придается меньший вес. В данном случае возникает ряд новых проблем, связанных с расчетом доверительных интервалов, а так же с определением подходящей функции для минимизации ошибок.