

3.2.2.1 Схема полной рандомизации
Если вся совокупность экспериментальных объектов представляется достаточно однородной и нет никаких оснований полагать, что разброс результатов будет меньшим внутри определенным образом сформированных подгрупп, распределение объектов в разные группы выполняется случайным образом.
Если объекты в подгруппах единиц, таких как положение в пространстве или дата исследования распределены более однородно, чем вся совокупность в целом, точность количественного определения может быть повышена путем введения в план исследований одного или нескольких ограничений. Тщательно продуманное распределение объектов с использованием этих ограничений позволяет исключить незначимые источники вариации.
3.2.2.2 Схема рандомизированных блоков
В основе этой схемы лежит возможность выделить идентифицируемый источник вариации (например, различная чувствительность у нескольких приплодов экспериментальных животных или различие между чашками Петри в случае микробиологического определения активности методом диффузии). В соответствии с данной схемой каждое исследование должно быть повторено одинаковое число раз в каждом из блоков (приплод или чашка Петри). Данная схема применима только тогда, когда блок достаточно большой для осуществления всех исследований. Пример использования такой схемы приведен в Разделе 5.1.3. Также допускается использовать схемы рандомизированных блоков с повторениями. В пределах каждого блока исследования должны распределяться случайным образом.
В Разделе 8.5. приведен алгоритм, при помощи которого можно получить случайное распределение.
Схема латинского квадрата
Данная схема применяется, когда на результат воздействует два различных источника вариации, каждый из которых может характеризоваться k различными уровнями или позициями. Например, в случае количественного определения антибиотиков с использованием пластин, исследования могут быть организованы на большой пластине в виде матрицы kxk; причем каждое исследование встречается по одному разу в каждом столбце и в каждой строке. Схема применяется в случае, когда число строк, столбцов и число исследований одинаково. Результаты записываются в виде квадрата, называемого латинским. Вариации, обусловленные различием в результатах между k строками и k столбцами, могут быть сгруппированы, что позволит уменьшить погрешность. Пример использования схемы латинского квадрата приведен в Разделе 5.1.2. В Разделе 8.6. дан алгоритм для построения латинских квадратов.
Перекрестная схема
Данную схему полезно применять, когда эксперимент может быть разделен на блоки, но к каждому блоку возможно применить только два исследования. Например, таким блоком может быть один экспериментальный объект, который может быть протестирован дважды. Данная схема предназначена для повышения точности путем исключения различий результатов между объектами за счет их взаимной компенсации при двух экспериментах с общим уровнем эффекта. Если исследуются две дозы испытуемого и стандартного препаратов, такую схему называют двойной перекрестной схемой.
Эксперимент разбивают на две стадии, разделенные достаточным промежутком времени. Объекты подразделяют на четыре группы, и на первой стадии эксперимента в каждой группе выполняется одно из четырех исследований. Объекты, которые на первой стадии получали один препарат, на второй стадии получают второй препарат. Единицы, которые на первой стадии получали меньшие дозы, на второй стадии получают большие. Распределение доз приведено в Таблице 3.2.2.-I. Пример использования схемы показан в Разделе 5.1.5.
 В
данном разделе приведены формулы,
которые необходимы при выполнении
дисперсионного анализа. В Разделе 5.1.
рассмотрены конкретные примеры,
позволяющие понять назначение этих
формул. Если необходимо, можно также
обратиться к терминам и определениям
(Раздел 9).
В
данном разделе приведены формулы,
которые необходимы при выполнении
дисперсионного анализа. В Разделе 5.1.
рассмотрены конкретные примеры,
позволяющие понять назначение этих
формул. Если необходимо, можно также
обратиться к терминам и определениям
(Раздел 9).
Приведенные формулы пригодны для симметричных количественных определений, в которых один или более испытуемых препаратов (Т, U и др.) сравниваются со стандартным препаратом (S). Следует подчеркнуть, что формулы могут быть использованы только в том случае, если дозы отличаются одна от другой в одинаковое число раз, если каждый из препаратов исследуется одинаковое число раз и если каждое исследование повторяется одинаковое число раз. Если эти условия не выполняются, данные формулы не должны применяться для анализа.
За исключением некоторых уточнений остаточной ошибки, основной статистический анализ данных количественного определения одинаков для схем полной рандомизации, рандомизированных блоков и латинских квадратов. Формулы для перекрестной схемы исследования сильно отличаются и приведены в примере 5.1.5.
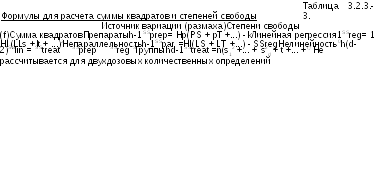
Исходя из рассмотренных в разделе 3.1. пунктов и преобразовав, если это необходимо, эффекты, для каждой группы и для каждой дозы препарата следует вычислить среднее значение, как описано в Таблице 3.2.3.-I. Также следует вычислить линейные контрасты, связанные с наклоном прямых «/п(доза-эффект)». В таблице 3.2.3.-II. Приведены три дополнительные формулы, которые необходимы для проведения анализа.
Суммарная вариация результатов, вызванная различными препаратами, подразделяется далее, как описано в Таблице 3.2.3.-3; сумму квадратов при этом рассчитывают с использованием данных из Таблиц 3.2.3.-1. и 3.2.3.-2. Сумма квадратов, обусловленная нелинейностью, может быть рассчитана только в том случае, если при количественном определении использовались, по крайней мере, по три дозы каждого из препаратов.
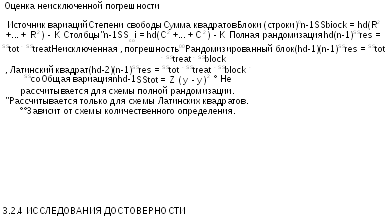
Неисключенная погрешность количественного определения рассчитывается путем вычитания вариации, обусловленной схемой рандомизации эксперимента, из общей вариации для эффекта (Таблица 3.2.3.-4). В этой таблице y - среднее значение
всех результатов, полученных при количественном определении. Следует заметить, что для латинского квадрата число повторных результатов (n) равно числу строк, столбцов и видов воздействий (dh).
Дисперсионный анализ завершают следующим образом. Находят дисперсию (средний квадрат отклонения) путем деления каждой суммы квадратов на соответствующее число степеней свободы. Далее оценивают статистическую значимость отношения дисперсии для каждой переменной к неисключенной (остаточной) погрешности
Таблица
3.2.3.-2.
 (s2)
( так называемое
F-отношение).
Для чего можно использовать Таблицу
8.1 или соответствующую подпрограмму
компьютерного программного обеспечения.
(s2)
( так называемое
F-отношение).
Для чего можно использовать Таблицу
8.1 или соответствующую подпрограмму
компьютерного программного обеспечения.
Дополнительные формулы для дисперсионного анализа
и = n
и
12n
d3 - d
K
n(Ps + Pt + ...)2 hd
 Результаты
количественного определения считаются
«статистически значимыми», если
выполняются следующие условия:
Результаты
количественного определения считаются
«статистически значимыми», если
выполняются следующие условия:
проведенные вычисления свидетельствуют о значимости линейной регрессии, т. е. рассчитанная вероятность меньше 0,05. Если это условие не выполняется, вычислить доверительный интервал с вероятностью 95% не представляется возможным;
проведенные вычисления свидетельствуют, что непараллельность незначима, т. е. рассчитанная вероятность >0,05. Это означает, что условие 5А (Раздел 3.1) выполняется.
Проведенные вычисления свидетельствуют, что нелинейность незначима, т.е. рассчитанная вероятность >0,05. Это означает, что условие 4А (Раздел 3.1) выполняется.
Существенное отклонение от параллельности при многократных количественных определениях может быть обусловлено тем, что угловой коэффициент зависимости «^доза-эффект)» для одного из препаратов, включенных в исследование, отличается от аналогичного значения для других препаратов. В этом случае допускается не признавать несостоятельность всего анализа, а исключить результаты, имеющие отношение к этому препарату, и повторить статистический анализ заново.
После того, как установлена статистическая значимость, могут быть рассчитаны оценки активности препаратов и границы доверительных интервалов при помощи приведенных в следующем разделе методов.
3.2.5 ОЦЕНКА АКТИВНОСТИ И ГРАНИЦ ДОВЕРИТЕЛЬНЫХ ИНТЕРВАЛОВ
Если обозначить через I натуральный логарифм отношения между ближайшими значениями доз любого из препаратов, то общий для всех прямых угловой коэффициент (b) в случае количественного определения, которое включает d доз для каждого препарата, вычисляется по формуле:
b
=
Hl
{Ls
+
Lt
+
-)
(3.2.5.-1) Inh
Логарифм отношения активности испытуемого препарата, например Т, вычисляют по формуле:
MT
=
Pt
-
Ps
(3.2.5.-2)
T
db
Рассчитанная активность представляет собой оценку «истинной активности» каждого из испытуемых препаратов. Границы доверительного интервала могут быть рассчитаны, как антилогарифм выражения:
CMT ±,1 (C - 1)(CMT2 + 2V) (3.2.5.-3)
где:
C =
reg
SSreg - S't'
v = ssreg
b2 dn
Значение t может быть найдено из Таблицы 8.2. при р=0,05 и числе степеней свободы, равному числу степеней свободы неисключенной (остаточной) погрешности. Оценка активности (RT) и соответствующий доверительный интервал вычисляют путем умножения результатов на величину AT после антилогарифмирования. Если выяснится, что активности исходных растворов, приготовленных исходя из предполагаемой и принятой активностей, не равны между собой, следует ввести поправочный коэффициент (см. примеры 5.1.2 и 5.1.3).
3.2.6 ПРОПУЩЕННЫЕ РЕЗУЛЬТАТЫ
В случае сбалансированного количественного определения существует вероятность случайной потери одного или нескольких результатов, абсолютно не связанных с процедурой количественного определения, например, вследствие смерти животного. Если будет доказано, что смерть животного никоим образом не связана с составом введенного препарата, возможность выполнения точных расчетов остается, но формулы значительно усложняются и могут быть представлены только в рамках общих линейных моделей (см. Раздел 7.1). Тем не менее, существует приблизительный метод в котором простота сбалансированного плана сохраняется путем замены потерянного результата рассчитанным значением. Потерю информации, которая при этом имеет место, сохраняют следующим образом: число степеней свободы для общей суммы квадратов и для неисключенной (остаточной) погрешности уменьшают на число потерянных результатов, а для вычисления отсутствующих значений используют одну из приведенных ниже формул. Следует иметь ввиду, что этот метод является приблизительным, и предпочтения следует отдавать точным расчетам.
Если потеряно более одного результата, могут быть использованы эти же формулы. В этом случае для всех потерянных значений, кроме одного, проводят грубые оценки. Для этого значения вычисляют при помощи соответствующей формулы с учетом всех данных, включая сделанные предположения. Эти рассчитанные значения
включают в общий массив данных и аналогичным образом проводят вычисление значений для первой из грубых оценок. После вычисления всех потерянных значений повторяют весь цикл сначала, используя более точные приближения или рассчитанные значения для каждого результата, для которого применялась формула. Такой цикл вычислений повторяют до тех пор, пока два последовательных цикла не дадут те же самые значения. Обычно сходимость достигается очень быстро.
При условии, что число замененных результатов невелико по отношению к общему числу данных в эксперименте (например, меньше 5%), приближения, предполагаемые при этих заменах и уменьшение степеней свободы на число потерянных данных, замененных таким образом, обычно являются удовлетворительными. Полученные результаты следует интерпретировать с большой осторожностью, особенно если имеются пропущенные результаты в одном исследовании или блоке. В случае неясностей, либо непредвиденных ситуациях следует проконсультироваться со специалистом по биостатистике. Категорически недопустима замена пропущенных результатов в случае испытаний без повторений.
Схема полной рандомизации
В данном случае пропущенное значение может быть заменено средним арифметическим всех других результатов в пределах одной группы.
Схема рандомизированных блоков
Потерянный результат заменяют величиной у', рассчитанной по формуле:
У = nB'+kT-G' (3.2.6.-1) У (n - 1)(k -1) v '
где B' - сумма результатов для блока, содержащего потерянное значение, T' - соответствующее общее количество препаратов, G' - сумма всех результатов, полученных при количественном определении.
Схема латинских квадратов
Пропущенное значение у' рассчитывают по формуле:
k(B+C- 2G (3.2.6.-2) У (k - 1)(k - 2) V '
где:
B' и C' - суммы результатов, соответственно, в строках и столбцах, содержащих потерянные данные. В данном случае k=n.
Перекрестная схема
Если при использовании перекрестной схемы результат был случайно потерян, следует обратиться к пособию по статистике (например, к руководству D.J.Finney, см. Раздел 10), поскольку применение той или иной формулы зависит от конкретной комбинации исследований.