

- •Matrix computations on systems equipped with GPUs
- •Introduction
- •The evolution of hardware for High Performance Computing
- •The programmability issue on novel graphics architectures
- •About this document. Motivation and structure
- •Motivation and goals
- •Structure of the document
- •Description of the systems used in the experimental study
- •Performance metrics
- •Hardware description
- •Software description
- •The FLAME algorithmic notation
- •The architecture of modern graphics processors
- •The graphics pipeline
- •Programmable pipeline stages
- •The Nvidia G80 as an example of the CUDA architecture
- •The architecture of modern graphics processors
- •General architecture overview. Nvidia Tesla
- •Memory subsystem
- •The GPU as a part of a hybrid system
- •Arithmetic precision. Accuracy and performance
- •Present and future of GPU architectures
- •Conclusions and implications on GPU computing
- •BLAS on single-GPU architectures
- •BLAS: Basic Linear Algebra Subprograms
- •BLAS levels
- •Naming conventions
- •Storage schemes
- •BLAS on Graphics Processors: NVIDIA CUBLAS
- •Evaluation of the performance of NVIDIA CUBLAS
- •Improvements in the performance of Level-3 NVIDIA CUBLAS
- •gemm-based programming for the Level-3 BLAS
- •Systematic development and evaluation of algorithmic variants
- •Experimental results
- •Impact of the block size
- •Performance results for rectangular matrices
- •Performance results for double precision data
- •Padding
- •Conclusions
- •LAPACK-level routines on single-GPU architectures
- •LAPACK: Linear Algebra PACKage
- •LAPACK and BLAS
- •Naming conventions
- •Storage schemes and arguments
- •LAPACK routines and organization
- •Cholesky factorization
- •Scalar algorithm for the Cholesky factorization
- •Blocked algorithm for the Cholesky factorization
- •Computing the Cholesky factorization on the GPU
- •Basic implementations. Unblocked and blocked versions
- •Padding
- •Hybrid implementation
- •LU factorization
- •Scalar algorithm for the LU factorization
- •Blocked algorithm for the LU factorization
- •LU factorization with partial pivoting
- •Computing the LU factorization with partial pivoting on the GPU
- •Basic implementations. Unblocked and blocked versions
- •Padding and hybrid algorithm
- •Reduction to tridiagonal form on the graphics processor
- •The symmetric eigenvalue problem
- •Reduction to tridiagonal form. The LAPACK approach
- •Reduction to tridiagonal form. The SBR approach
- •Experimental Results
- •Conclusions
- •Matrix computations on multi-GPU systems
- •Linear algebra computation on multi-GPU systems
- •Programming model and runtime. Performance considerations
- •Programming model
- •Transfer management and spatial assignation
- •Experimental results
- •Impact of the block size
- •Number of data transfers
- •Performance and scalability
- •Impact of data distribution
- •Conclusions
- •Matrix computations on clusters of GPUs
- •Parallel computing memory architectures
- •Shared memory architectures
- •Distributed memory and hybrid architectures
- •Accelerated hybrid architectures
- •Parallel programming models. Message-passing and MPI
- •ScaLAPACK
- •PLAPACK
- •Elemental
- •Description of the PLAPACK infrastructure
- •Layered approach of PLAPACK
- •Usage of the PLAPACK infrastructure. Practical cases
- •Porting PLAPACK to clusters of GPUs
- •Experimental results
- •Conclusions
- •Conclusions
- •Conclusions and main contributions
- •Contributions for systems with one GPU
- •Contributions for clusters of GPUs
- •Related publications
- •Publications directly related with the thesis topics
- •Publications indirectly related with the thesis topics
- •Other publications
- •Open research lines
- •FLAME algorithms for the BLAS-3 routines

CHAPTER 6. MATRIX COMPUTATIONS ON CLUSTERS OF GPUS
consider the necessary changes in the Cholesky factorization routine shown in Figure 6.11. An hypothetical driver would include the appropriate adapted codes to allocate, manage and free objects bound to the GPU memory space.
6.6.Experimental results
The goal of the experiments in this section is twofold. First, to report the raw performance that can be attained with the accelerated version of the PLAPACK library for two common linear algebra operations: the matrix-matrix multiplication and the Cholesky factorization. Second, to illustrate the scalability of the proposed solution by executing the tests on a moderate number of GPUs.
LONGHORN is a hybrid CPU/GPU cluster designed for remote visualization and data analysis. The system consists of 256 dual-socket nodes, with a total of 2,048 compute cores (Intel Xeon Nehalem QuadCore), 512 GPUs (128 NVIDIA Quadro Plex S4s, each containing 4 NVIDIA FX5800), 13.5 TBytes of distributed memory and a 210 TBytes global file system. The detailed specifications of the cluster were illustrated in Table 1.2.
In our experiments we only employ 16 compute nodes from LONGHORN. The results for 1, 2, 4, 8 and 16 GPUs make use of one of the GPUs in each node, with one MPI process per computing node. The results on 32 GPUs (there are two GPUs per node) were obtained using two MPI processes per node. This setup also illustrates the ability of the accelerated version of PLAPACK to deal with systems equipped with more than one accelerator per node (e.g., in a configuration with nodes connected to NVIDIA Tesla S1070 servers as the TESLA2 machine evaluated in Chapter 5). Here, only those results that are obtained for optimal values of the distribution and algorithmic block sizes are shown.
The matrix-matrix multiplication is frequently abused as a showcase of the highest attainable performance of a given target architecture. Following this trend, we have developed an implementation of this operation based on the PLAPACK PLA Gemm routine. The performance results for the matrix-matrix multiplication are shown in Figure 6.12. The highest performance achieved with the adapted version of the matrix multiplication routine is slightly over 8 TFLOPS when using 32 GPUs for matrices of dimension 61,440 × 61,440.
A similar experiment has been carried out for the Cholesky factorization. In our implementation of the PLAPACK routine PLA Chol, the factorization of the diagonal blocks is computed in the CPU using the general-purpose cores while all remaining operations are performed on the GPUs. This hybrid strategy has been successfully applied in previous chapters and studies [22, 23, 142]. Figure 6.13 reports the performance of the Cholesky routine on LONGHORN, which delivers 4.4 TFLOPS for matrices of dimension 102,400 × 102,400.
A quick comparison between the top performance of the matrix-matrix multiplication using the accelerated version of PLAPACK (8 TFLOPS) and the (theoretical) peak performance of the CPUs of the entire system (41.40 TFLOPS in single-precision arithmetic) reveals the advantages of exploiting the capabilities of the GPUs: using only 6% of the graphics processors available in the cluster (32 out of 512 GPUs) it is possible to attain 20% of the peak performance of the machine considering exclusively the available CPUs.
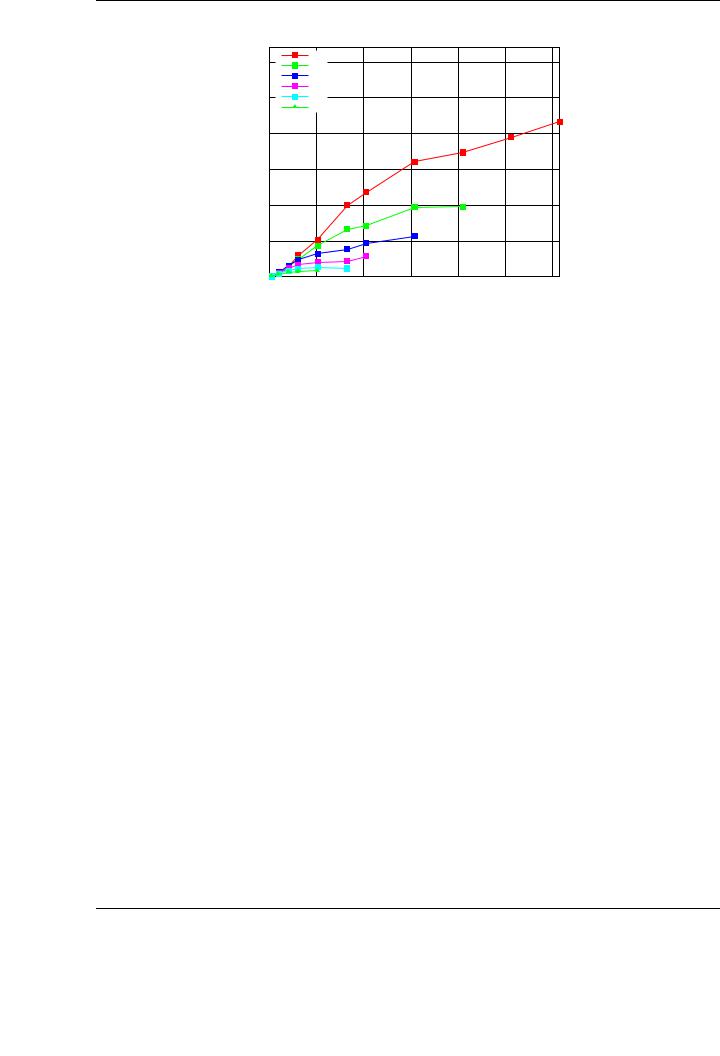
Figure 6.14 illustrates the scalability of the device-centric implementation matrix-matrix multiplication routine. Compared with the performance of the “serial” tuned implementation of the matrix-matrix product routine in NVIDIA CUBLAS, our routine achieves a 22× speedup on 32 GPUs, which demonstrates the scalability of the solution. Two main reasons account for the performance
194
6.6. EXPERIMENTAL RESULTS
Matrix-matrix multiplication on LONGHORN
|
9000 |
32 Quadro FX5800 |
|
|
|
|
|
|
|
|
|
|
|
||
|
8000 |
16 Quadro FX5800 |
|
|
|
|
|
|
8 Quadro FX5800 |
|
|
|
|
||
|
|
|
|
|
|
||
|
|
4 Quadro FX5800 |
|
|
|
|
|
|
7000 |
2 Quadro FX5800 |
|
|
|
|
|
|
|
1 Quadro FX5800 |
|
|
|
|
|
|
6000 |
|
|
|
|
|
|
GFLOPS |
5000 |
|
|
|
|
|
|
4000 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3000 |
|
|
|
|
|
|
|
2000 |
|
|
|
|
|
|
|
1000 |
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
0 |
10000 |
20000 |
30000 |
40000 |
50000 |
60000 |
|
|
|
Matrix size (m = n = k) |
|
|
||
Figure 6.12: Performance of the device-centric implementation of GEMM on 32 GPUs of
LONGHORN.
Cholesky factorization on LONGHORN
|
9000 |
32 Quadro FX5800 |
|
|
|
|
|
|
|
|
|
|
|
||
|
8000 |
16 Quadro FX5800 |
|
|
|
|
|
|
8 Quadro FX5800 |
|
|
|
|
||
|
|
|
|
|
|
||
|
|
4 Quadro FX5800 |
|
|
|
|
|
|
7000 |
2 Quadro FX5800 |
|
|
|
|
|
|
|
1 Quadro FX5800 |
|
|
|
|
|
|
6000 |
|
|
|
|
|
|
GFLOPS |
5000 |
|
|
|
|
|
|
4000 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3000 |
|
|
|
|
|
|
|
2000 |
|
|
|
|
|
|
|
1000 |
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
0 |
10000 |
20000 |
30000 |
40000 |
50000 |
60000 |
Matrix size
Figure 6.13: Performance of the device-centric implementation of the Cholesky factorization on 32
GPUs of LONGHORN.
195
CHAPTER 6. MATRIX COMPUTATIONS ON CLUSTERS OF GPUS
Matrix-matrix multiplication on LONGHORN
|
30 |
32 Quadro FX5800 |
|
|
|
|
|
|
16 Quadro FX5800 |
|
|
|
|
||
|
|
|
|
|
|
||
|
|
8 Quadro FX5800 |
|
|
|
|
|
|
25 |
4 Quadro FX5800 |
|
|
|
|
|
|
2 Quadro FX5800 |
|
|
|
|
||
|
|
1 Quadro FX5800 |
|
|
|
|
|
|
20 |
|
|
|
|
|
|
Speedup |
15 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
|
5 |
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
0 |
10000 |
20000 |
30000 |
40000 |
50000 |
60000 |
|
|
|
Matrix size (m = n = k) |
|
|
||
Figure 6.14: Speed-up of the device-centric GEMM implementation on LONGHORN.
penalty: the Infiniband network and the PCIExpress bus (mainly when 32 GPUs/16 nodes are employed as the bus is shared by two GPUs per node).
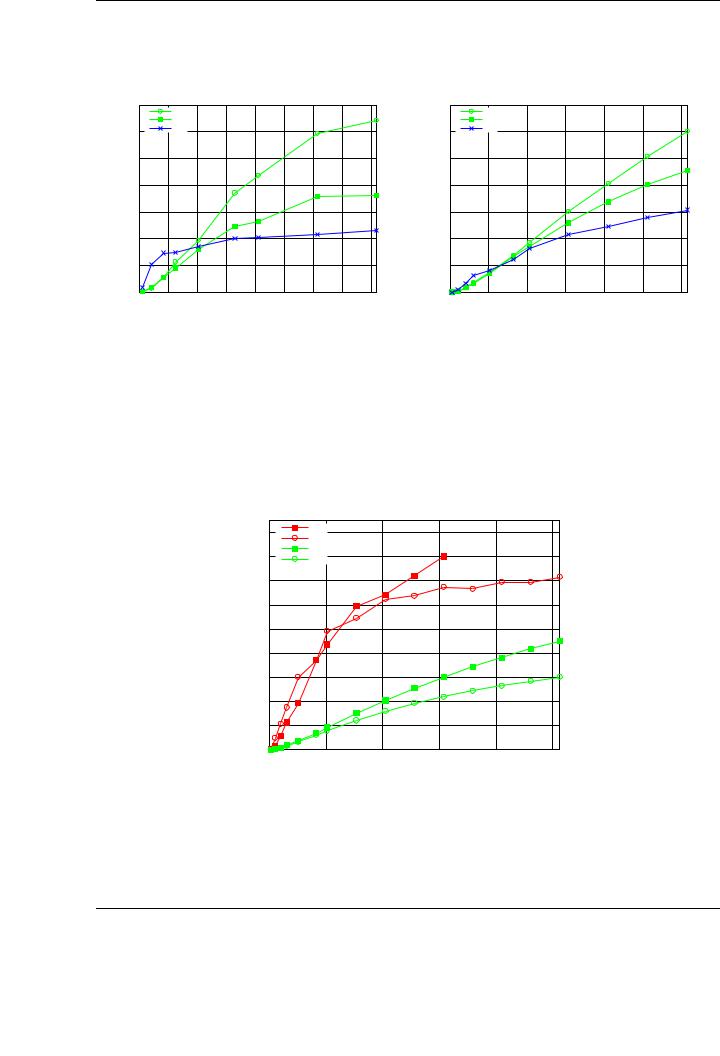
The plots in Figure 6.15 evaluate the performance of the original PLAPACK implementation and the GPU-accelerated version of the library for the matrix-matrix multiplication (left-side plot) and the Cholesky implementation (right-side plot). Results are shown only on 16 nodes of LONGHORN. Thus, the plots report the performance of the PLAPACK implementation using 128 Intel Nehalem cores (8 cores per node) versus those of the accelerated library using 16 and 32 GPUs (that is, one or two GPUs per each node). For the matrix-matrix multiplication, the highest performance for PLAPACK is 2.3 TFLOPS, while the accelerated version of the library attains 3.6 TFLOPS for 16 GPUs and 6.4 TFLOPS for 32 GPUs. The speedups obtained by the accelerated routines are 1.6× and 2.8×, respectively. For the Cholesky implementation, the PLAPACK routine attains a peak performance of 1.6 TFLOPS, compared with the 2.6 and 4.5 TFLOPS achieved by the accelerated versions of the routines on 16 and 32 GPUs, respectively. In this case, the corresponding speedups are 1.7× and 2.8×, respectively.
Note how the performance of the CPU-based version of PLAPACK is higher for matrices of small dimension. This fact is usual in GPGPU algorithms, and has already been observed in other works [22, 142] and in previous chapters. In response to this, hybrid algorithms combining CPU and GPU execution are proposed in those works. In the PLAPACK library, the implementation of hybrid algorithms would require a deep modification of internals of the library. Other approaches for multi-GPU computing computations can be integrated in the library to optimally exploit the heterogeneous resources in each node of the cluster. Independent studies, such as StarPU [13] or studies from the author of this thesis, such as the runtime proposed in Chapter 5 or GPUSs [16] can be integrated into the library to automatically deal with the heterogeneous nature of each node (multiple GPUs and general-purpose multi-core processors).
The benefits of using an approach in which data are kept in the GPU memory during the whole computation are captured in Figure 6.16. The results report the performance of the host-centric approach, in which data is stored in the main memory of each node and transferred to the GPU when it is strictly necessary, and the device-centric approach, in which data is stored (most of the time) in the GPU memory. The advantages of the second approach, in terms of higher performance,
196
6.6. EXPERIMENTAL RESULTS
Matrix-matrix multiplication on LONGHORN |
Cholesky factorization on LONGHORN |
|
7000 |
32 Quadro FX5800 |
|
3500 |
|
|
|
|
|
||
|
|
16 Quadro FX5800 |
|
|
|
|
6000 |
128 Intel Xeon Nehalem Cores |
|
3000 |
|
|
5000 |
|
|
|
2500 |
GFLOPS |
4000 |
|
|
GFLOPS |
2000 |
3000 |
|
|
1500 |
||
|
|
|
|
||
|
2000 |
|
|
|
1000 |
|
1000 |
|
|
|
500 |
|
0 |
|
|
|
0 |
|
0 |
5000 |
10000 15000 20000 25000 30000 35000 40000 |
|
|
|
|
|
Matrix size (m = n = k) |
|
|
|
32 Quadro FX5800 |
|
|
|
||
|
16 Quadro FX5800 |
|
|
|
||
|
128 Intel Xeon Nehalem Cores |
|
|
|||
0 |
10000 |
20000 |
30000 |
40000 |
50000 |
60000 |
Matrix size
Figure 6.15: Performance of the device-centric implementation of GEMM (left) and the Cholesky factorization (right) compared with that of PLAPACK on 128 cores of LONGHORN.
Device-centrc vs. Host-centric implementations on LONGHORN (32 GPUs)
|
9000 |
Device-centric GEMM |
|
|
|
|
|
Host-centric GEMM |
|
|
|
||
|
|
|
|
|
||
|
8000 |
Device-centric Cholesky |
|
|
|
|
|
Host-centric Cholesky |
|
|
|
||
|
7000 |
|
|
|
|
|
|
6000 |
|
|
|
|
|
GFLOPS |
5000 |
|
|
|
|
|
4000 |
|
|
|
|
|
|
|
3000 |
|
|
|
|
|
|
2000 |
|
|
|
|
|
|
1000 |
|
|
|
|
|
|
0 |
|
|
|
|
|
|
0 |
20000 |
40000 |
60000 |
80000 |
100000 |
|
|
|
Matrix size (m = n = k) |
|
|
|
Figure 6.16: Cholesky factorization and GEMM on 16 nodes of LONGHORN, using the host-centric and device-centric storage approach for the accelerated implementation.
197