

3.4. EXPERIMENTAL RESULTS
|
|
TRSM and SYR2K performance on PECO |
TRSM and SYR2K speedup vs NVIDIA CUBLAS on PECO |
||||||||||||
|
500 |
CUBLAS TRSM, m = 32 |
|
|
|
|
14 |
NEW TRSM, m = 32 |
|
|
|
||||
|
|
|
|
|
|
13 |
|
|
|
||||||
|
|
NEW TRSM, m = 32 |
|
|
|
|
NEW SYR2K, k = 32 |
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
||||||
|
|
CUBLAS SYR2K, k = 32 |
|
|
|
|
12 |
|
|
|
|
|
|
||
|
400 |
NEW SYR2K, k = 32 |
|
|
|
|
11 |
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
GFLOPS |
300 |
|
|
|
|
|
|
Speedup |
9 |
|
|
|
|
|
|
|
|
|
|
|
|
8 |
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
7 |
|
|
|
|
|
|
||
200 |
|
|
|
|
|
|
6 |
|
|
|
|
|
|
||
|
|
|
|
|
|
5 |
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
4 |
|
|
|
|
|
|
|
100 |
|
|
|
|
|
|
|
3 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
0 |
3000 |
6000 |
9000 |
12000 |
15000 |
18000 |
|
0 |
3000 |
6000 |
9000 |
12000 |
15000 |
18000 |
|
|
|
Second dimension (n) |
|
|
|
|
|
Second dimension (n) |
|
|
||||
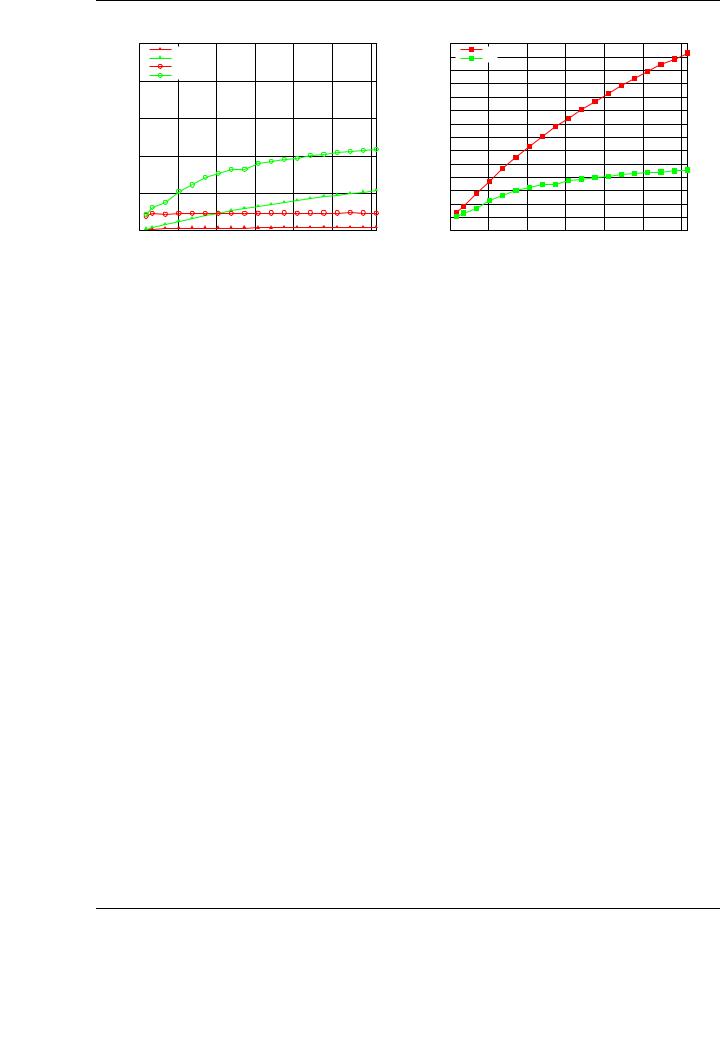
Figure 3.17: Performance of the tuned TRSM and SYR2K implementation on rectangular matrices (left) and speedup compared with NVIDIA CUBLAS (right).
This tuned case of the GEMM implementation has a direct application to routines such as the TRSM. The performance of the tuned TRSM implementations for the matrix-panel and panel-matrix variants performs particularly poor for large matrices, exactly as happened with the GEMM case exposed above. In fact, the behavior of TRSM when solving linear systems of the form X = XAT is dictated by the similar performance behavior of the GEMM when B is transposed, as this operation is the base of the blocked algorithms; see Figure A.4. Thus, the improvement of the performance of the general matrix-matrix multiplication shown in Figure 3.16 can be directly applied to the TRSM algorithms.
The performance and speedups attained by the blocked TRSM based on the optimized GEMM are shown in Figure 3.16. Note how, while the three basic algorithmic variants for the new TRSM implementation attain relatively poor performance results (even worse than the implementation from NVIDIA CUBLAS for large matrices), the reutilization of the tuned implementation of the GEMM routine provides a way to boost the performance of the original implementation from NVIDIA CUBLAS, attaining a speedup 1.5× for the largest problem dimension.
3.4.3.Performance results for rectangular matrices
BLAS-3 operations involving rectangular matrices are common in blocked implementation of many linear-algebra routines [144]. Figure 3.17 reports the performance results for two di erent BLAS-3 routines (TRSM and SYR2K) considering that their corresponding general operands are rectangular. The specific case for both routines is the same as the one illustrated throughout the rest of the evaluation. In the case of TRSM, the performance for the panel-matrix variant is shown; while in the case of SYR2K, the panel-panel variant is reported. These variants o ered the highest performance results compared with the rest of the algorithmic variants. The tested routines operate with rectangular matrices with 32 columns (parameter n in TRSM, k in SYR2K); thus, the x axis in the figure indicates the number of rows of the result (matrix X for TRSM, C for SYR2K).
The performance and speedups attained for our new implementations compared with those in NVIDIA CUBLAS inherit the improvements observed in the evaluation of the routines for square matrices. For TRSM, the improvement is even higher that that for that case: our implementation attains 107 GFLOPS for the largest matrices (n = 18,432), while NVIDIA CUBLAS attains only 8 GFLOPS. The highest speedup in this case is almost 13× compared with the NVIDIA CUBLAS im-
69
CHAPTER 3. BLAS ON SINGLE-GPU ARCHITECTURES
TRSM and SYR2K performance on PECO |
TRSM and SYR2K speedup vs NVIDIA CUBLAS on PECO |
|
120 |
CUBLAS TRSM |
|
|
|
|
|
|
|
|
|
|
|
|
|
NEW TRSM |
|
|
|
4 |
|
|
CUBLAS SYR2K |
|
|
|
|
|
100 |
|
|
|
|
|
|
NEW SYR2K |
|
|
|
|
|
|
80 |
|
|
|
|
3 |
GFLOPS |
60 |
|
|
|
Speedup |
|
|
|
|
|
2 |
||
|
|
|
|
|
||
|
40 |
|
|
|
|
|
|
|
|
|
|
|
1 |
|
20 |
|
|
|
|
|
|
0 |
|
|
|
|
0 |
|
0 |
3000 |
6000 |
9000 |
12000 |
|
|
NEW TRSM |
|
|
|
|
NEW SYR2K |
|
|
|
0 |
3000 |
6000 |
9000 |
12000 |
Matrix size |
Matrix size |
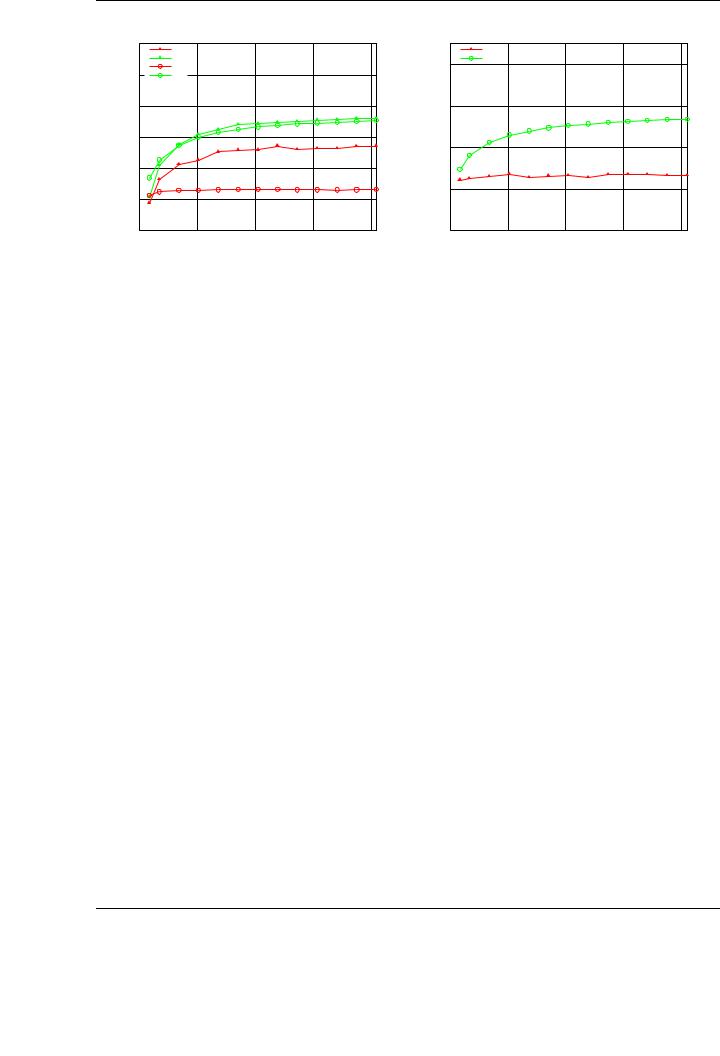
Figure 3.18: Performance of the tuned TRSM and SYR2K implementation on double precision matrices (left) and speedup compared with NVIDIA CUBLAS (right).
plementation. In the case of SYR2K, although the raw performance achieved by our implementation is higher (220 GFLOPS), the speedup obtained compared with the corresponding implementation in NVIDIA CUBLAS is 4.5×. In any case, these speedups are much higher than those attained for square matrices in previous experiments and demonstrate that the new implementations are also competitive compared with NVIDIA CUBLAS when the operands are rectangular.
3.4.4.Performance results for double precision data
The techniques presented to improve the performance employed in BLAS-3 routines in NVIDIA CUBLAS are independent from the arithmetic precision of the operations, provided the GEMM performance in NVIDIA CUBLAS delivers high performance in both simple and double precision. Similar qualitative results have been observed for all the operations, with our new implementations delivering remarkably better performances than those in NVIDIA CUBLAS.
Figure 3.18 compares the double-precision implementation of TRSM and SYR2K in NVIDIA CUBLAS and our new routines developed in this thesis. Only the optimal variants are presented, as the qualitative di erences between di erent algorithmic variants are similar to those observed for single precision. The results correspond to square matrices.
As in the single-precision evaluations, the tuned implementations outperform those in NVIDIA CUBLAS for double precision for all the reported routines and cases. The accelerations are similar to those observed for single precision (see Figures 3.15 and 3.16), achieving a speedup 1.3× for TRSM and 2.7× for SYR2K.
Note, however, how the raw performance delivered by this particular GPU model when the operations are performed using double precision is not so competitive with those obtained for single precision. In fact, the 310 GFLOPS attained for the tuned single-precision TRSM implementation (see Figure 3.16) are reduced to only 73 GFLOPS for double-precision data.
The GEMM implementation was illustrative of the di culties of the GPU to attain performances near its theoretical peak on single-precision arithmetic. In the results reported in Figure 3.2, an e ciency of only 40% was attained for this operation. As the number of double-precision units per GPU is quite reduced, the impact of the memory wall that was responsible of the poor e ciency in single-precision implementations is reduced, and thus the e ciency of the algorithms is dramatically
70
3.4. EXPERIMENTAL RESULTS
NVIDIA CUBLAS GEMM performance on PECO
|
500 |
|
CUBLAS GEMM |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
CUBLAS GEMM WITH PADDING |
|
|
|
|||
|
400 |
|
|
|
|
|
|
|
|
GFLOPS |
300 |
|
|
|
|
|
|
|
|
200 |
|
|
|
|
|
|
|
|
|
|
100 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
512 |
1024 |
1536 |
2048 |
2560 |
3072 |
3584 |
4096 |
|
|
|
Matrix size (m = n = k) |
|
|
||||
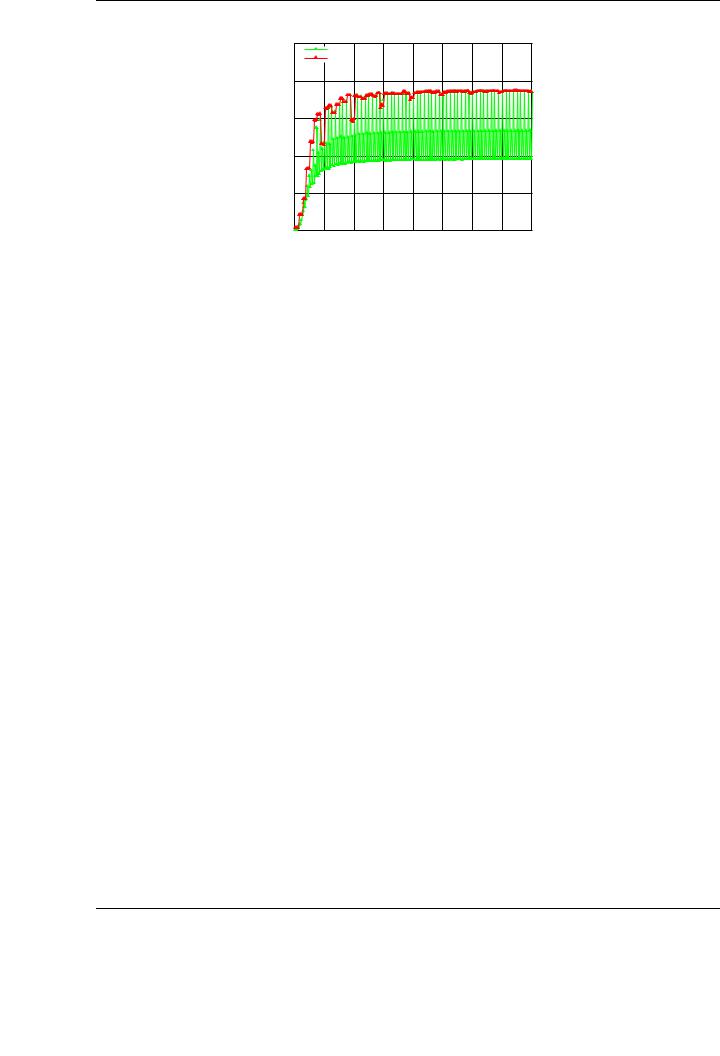
Figure 3.19: Detailed performance of the GEMM routine of NVIDIA CUBLAS.
increased. In the results reported in Figure 3.18, the attained performance represents a 93% of the peak performance of the architecture in double precision.
3.4.5.Padding
There is an additional factor with a relevant impact on the final performance of the NVIDIA CUBLAS implementation: the exact size of the operands. A fine-grained study of the performance of the GEMM implementation in NVIDIA CUBLAS reveals an irregular performance of the routine depending on the size of the input matrices. Figure 3.19 reports the performance of the GEMM implementation in NVIDIA CUBLAS for the operation C := C + AB for small matrix dimensions, from m = n = k = 8 to m = n = k = 4096 in steps of 8. Comparing this evaluation with that performed in Figure 3.3, yields several rapid observations: First, better performance results are attained for matrix dimensions which are integer multiple of 32; optimal results are achieved for matrix dimensions that are an integer multiple of 64. Second, there exists a dramatic decrement in the performance of the GEMM routine for matrices that do not meet this restriction in their dimensions. This behavior is present in each implementation of the BLAS-3 routines in NVIDIA CUBLAS, not only for GEMM.
This irregular behavior is caused by two factors intimately related to the architectural details of the graphics processors with CUDA architecture. First, the warp size (or minimum scheduling unit) of modern GPUs (32 threads in the tested unit) is a critical factor. Depending on the size of the matrices to be multiplied, some threads for each warp may remain idle, and thus penalize the global performance of the implementation. Second, there exist some memory access restrictions (data coalescing) to attain the peak bandwidth between the graphics processor and GPU memory, reducing the number of memory transactions. This type of restrictions and optimizations are also related with the specific size of the data structures to be transferred to/from the graphics processor.
To avoid the sources of irregular behavior of the GEMM implementation (and equally to other BLAS-3 routines), NVIDIA suggests some common optimization practices [2]. However, as NVIDIA CUBLAS is a closed-source library, it is di cult or even impossible to apply those techniques to the existing NVIDIA CUBLAS codes. However, it is possible to avoid the irregular performance of the GEMM and other BLAS routines by applying a simple technique. Our proposal for GEMM is to pad with zeros the input matrices, transforming their dimensions into the next multiple of 64. With this transformation, we introduce a small overhead in the computation of the kernel, negligible for
71