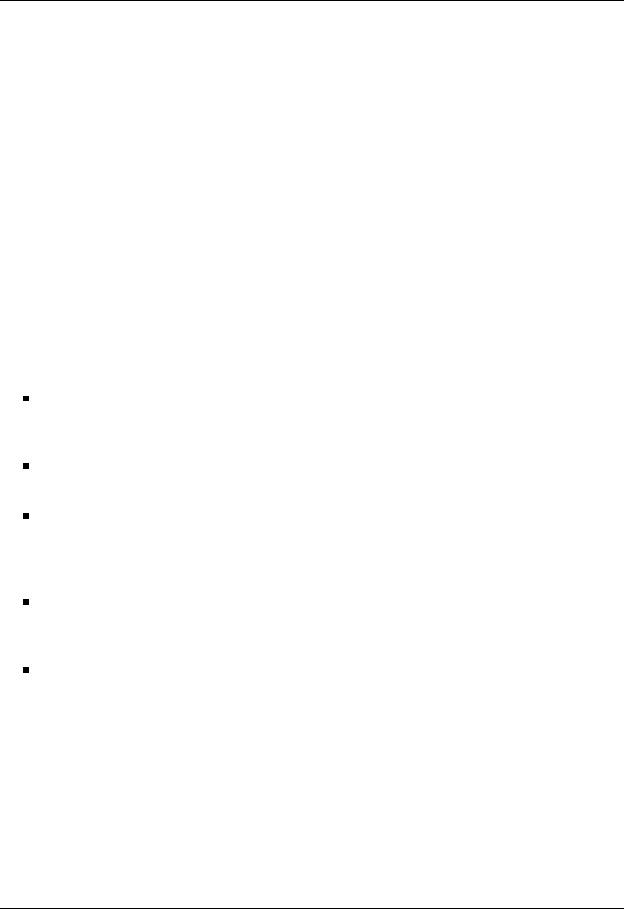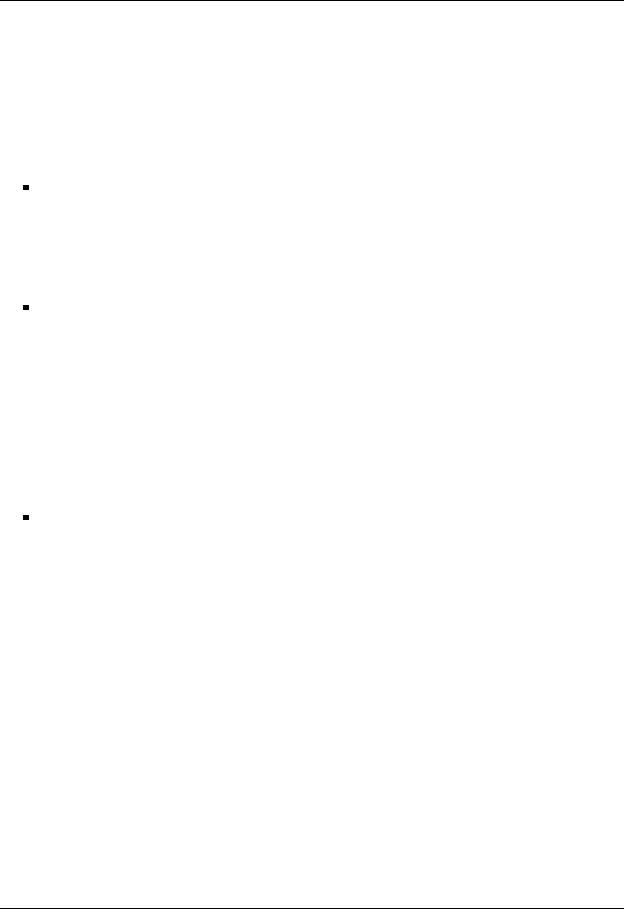5.4. EXPERIMENTAL RESULTS
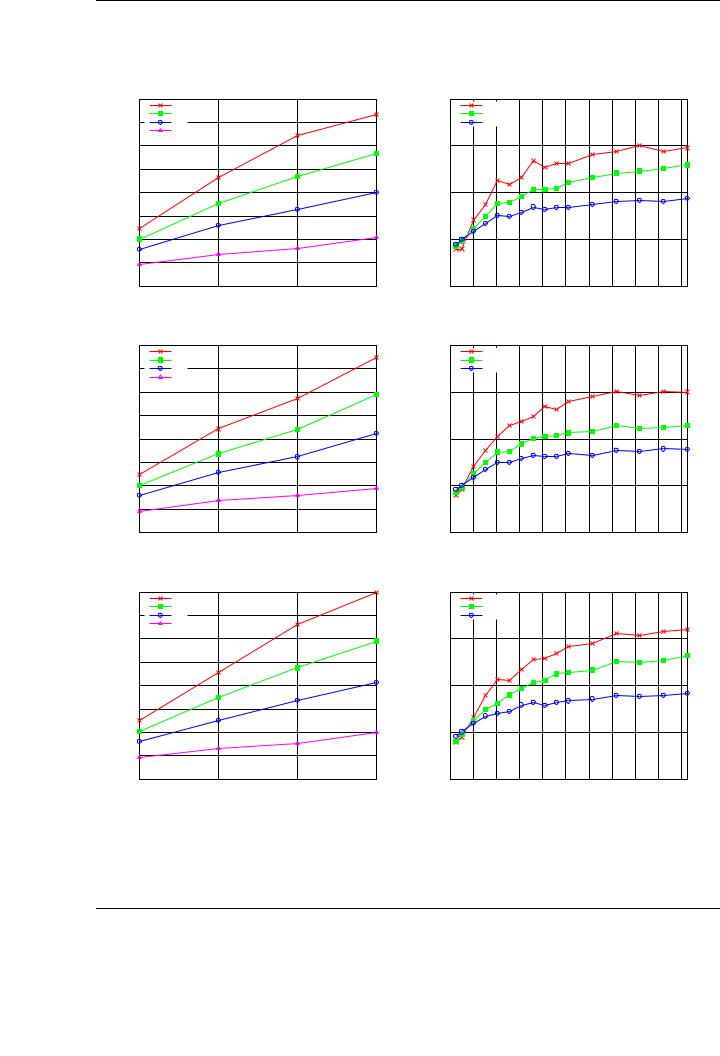
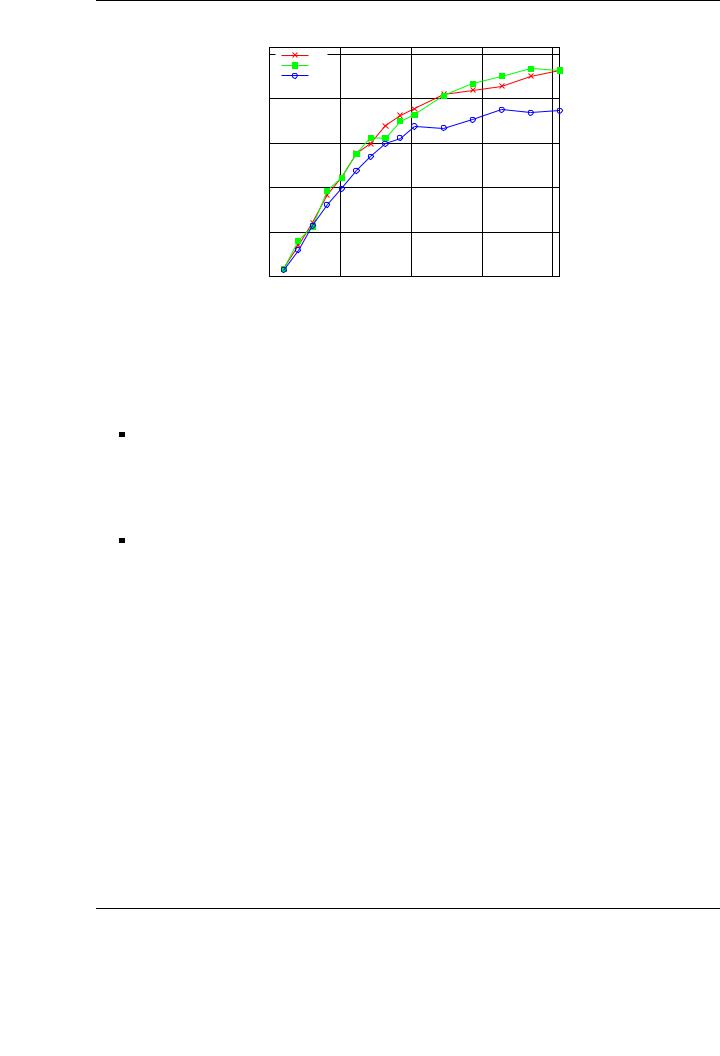
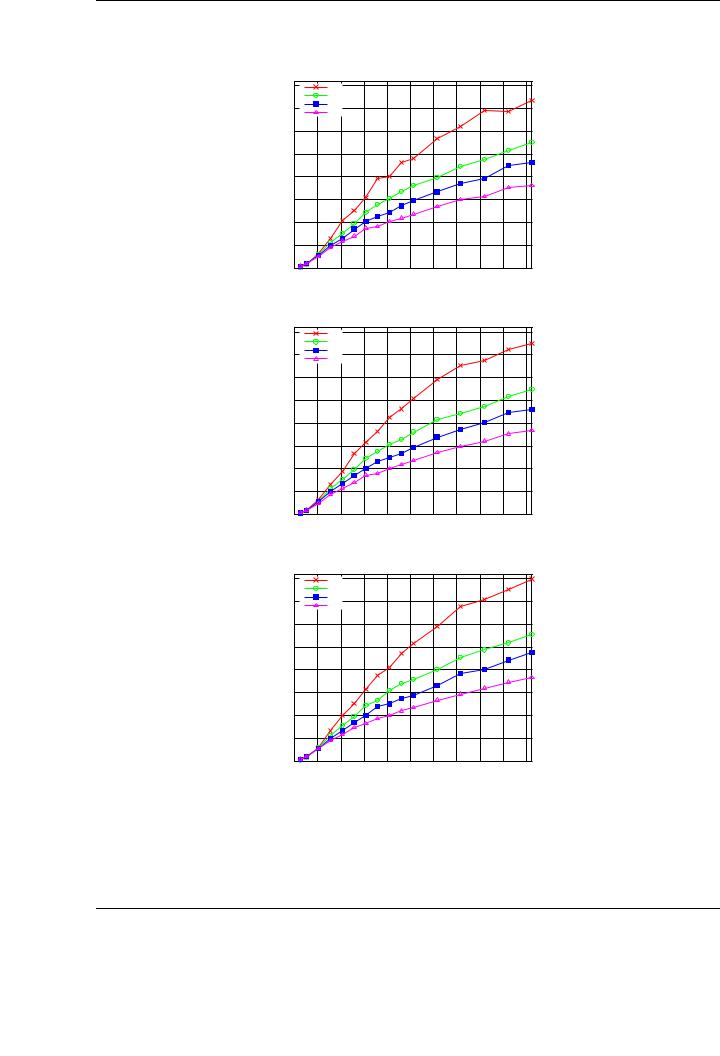
Figure 5.9 shows the performance attained for the Cholesky factorization of a matrix of increasing size on the four versions of the runtime, with 2-D data distribution for versions 2-4. The plots show the performance of the algorithmic variants (Variant 1 in the top plot, Variant 2 in the middle plot and Variant 3 in the bottom plot).
A careful observation of the performance results o ers an idea of the impact of the reduction of data transfers while improving data transfer management. As an starting point, consider in the following discussion the results attained for Variant 1 of the algorithm. Peak performance for the basic implementation (Version 1 of the runtime), in which data is transferred to GPU memory prior to the execution of the task and retrieved back after its conclusion, is 357 GFLOPS. The usage of data a nity and the storage of own blocks in the corresponding GPU (Version 2 of the runtime) boosts this performance up to 467 GFLOPS. With the introduction of the software cache mechanism with a write-through coherence policy between main memory an GPU memory (Version 3 of the runtime) performance is increased to 544 GFLOPS. Finally, the use of a combination of software cache and a write-back policy is translated into the best raw performance, attaining a peak of 705 GFLOPS. Note that this performance is not still fully stabilized, and could be further increased for larger matrices, provided there was enough memory space in the aggregated GPU memory space.
Similar qualitative results and improvements are shown for algorithmic variants 2 and 3 (middle and bottom plots, respectively). The speedup ratios are similar to those achieved for the first variant using di erent runtime versions. Considering raw performance, variant 3 attains a peak performance of 798 GFLOPS, whereas variants 1 and 2 achieve 735 GFLOPS and 751 GFLOPS, respectively. As was the case in the evaluation of single-GPU implementations, these results demonstrate the benefits of providing a whole family of algorithmic variants for multi-GPU systems in order to find the optimal one for a given operation.
To analyze the scalability of the proposed software solution, in Figure 5.10 we evaluate the scalability (left-hand side plots) and reports the speed-up (right-hand side plots) of the di erent algorithmic variants of the algorithm-by-blocks.
As an illustrative example, consider the top plot, which corresponds to the algorithmic variant 1. No bottlenecks are revealed in the scalability of this variant: the performance of the system steadily improves as the number of GPUs is increased, and larger problem sizes report higher execution rates. The speed-ups are calculated comparing the performance attained by the algorithms-by-blocks using 2–4 GPUs with that of executing same algorithm on a single graphics processor. For the largest problem dimension, the results show speed-ups of 1.9×, 2.5×, and 2.9× using respectively 2, 3, and 4 GPUs for variant 1; 1.7×, 2.2×, and 3× for variant 2; and 1.8×, 2.6×, and 3.2× for variant 3. Note that the PCI-Express bus becomes a bottleneck as the number of GPUs increases. This justifies the necessity of a proper data transfer policy as those implemented in our runtime.
5.4.4.Impact of data distribution
Data layout is an additional factor that can a ect the performance attained for a given operation using any of the tuned variants of the developed runtime. The performance di erences are mostly explained by a higher data locality when using runtime versions that make use of software caches.
Figure 5.11 shows the performance of the proposed algorithmic variants for the Cholesky factorization using the four GPUs of TESLA2, and version 4 of the runtime. The experimental conditions are the same as those set in previous experiments. In this experiment, we report the performance results attained for three di erent data distributions: cyclic 2-dimensional (top plot), column-wise distribution (middle plot) and row-wise distribution (bottom plot).
151
CHAPTER 5. MATRIX COMPUTATIONS ON MULTI-GPU SYSTEMS
Cholesky factorization on TESLA2. 2-D distribution. Variant 1
|
800 |
|
Runtime Version 4 |
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|||
|
|
|
Runtime Version 3 |
|
|
|
|
|
|
||
|
700 |
|
Runtime Version 2 |
|
|
|
|
|
|
||
|
|
Runtime Version 1 |
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|||
|
600 |
|
|
|
|
|
|
|
|
|
|
GFLOPS |
500 |
|
|
|
|
|
|
|
|
|
|
400 |
|
|
|
|
|
|
|
|
|
|
|
300 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
200 |
|
|
|
|
|
|
|
|
|
|
|
100 |
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
0 |
2000 |
4000 |
6000 |
8000 |
10000 |
12000 |
14000 |
16000 |
18000 |
20000 |
Matrix size
Cholesky factorization on TESLA2. 2-D distribution. Variant 2
|
800 |
|
Runtime Version 4 |
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|||
|
|
|
Runtime Version 3 |
|
|
|
|
|
|
||
|
700 |
|
Runtime Version 2 |
|
|
|
|
|
|
||
|
|
Runtime Version 1 |
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|||
|
600 |
|
|
|
|
|
|
|
|
|
|
GFLOPS |
500 |
|
|
|
|
|
|
|
|
|
|
400 |
|
|
|
|
|
|
|
|
|
|
|
300 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
200 |
|
|
|
|
|
|
|
|
|
|
|
100 |
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
0 |
2000 |
4000 |
6000 |
8000 |
10000 |
12000 |
14000 |
16000 |
18000 |
20000 |
Matrix size
Cholesky factorization on TESLA2. 2-D distribution. Variant 3
|
800 |
|
Runtime Version 4 |
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|||
|
|
|
Runtime Version 3 |
|
|
|
|
|
|
||
|
700 |
|
Runtime Version 2 |
|
|
|
|
|
|
||
|
|
Runtime Version 1 |
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|||
|
600 |
|
|
|
|
|
|
|
|
|
|
GFLOPS |
500 |
|
|
|
|
|
|
|
|
|
|
400 |
|
|
|
|
|
|
|
|
|
|
|
300 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
200 |
|
|
|
|
|
|
|
|
|
|
|
100 |
|
|
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
|
|
0 |
2000 |
4000 |
6000 |
8000 |
10000 |
12000 |
14000 |
16000 |
18000 |
20000 |
Matrix size
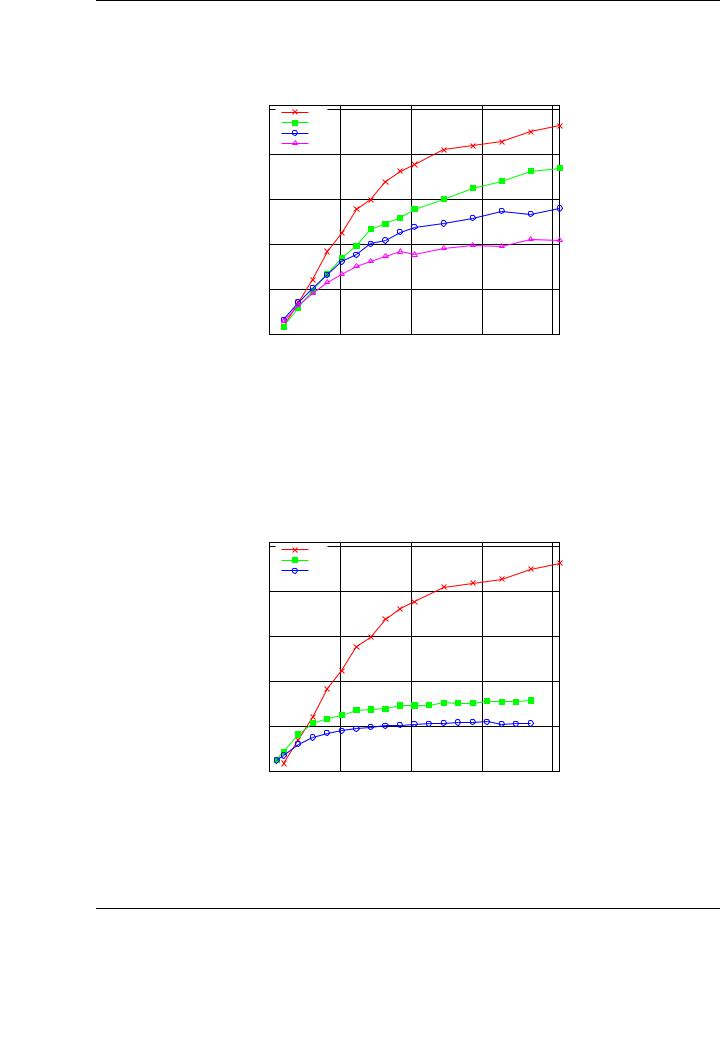
Figure 5.9: Performance comparison of di erent algorithmic variants of the Cholesky factorization using 4 GPUs on TESLA2, using a 2-D distribution. Top: algorithmic variant 1. Middle: algorithmic variant 2. Bottom: algorithmic variant 3.
152