

- •Matrix computations on systems equipped with GPUs
- •Introduction
- •The evolution of hardware for High Performance Computing
- •The programmability issue on novel graphics architectures
- •About this document. Motivation and structure
- •Motivation and goals
- •Structure of the document
- •Description of the systems used in the experimental study
- •Performance metrics
- •Hardware description
- •Software description
- •The FLAME algorithmic notation
- •The architecture of modern graphics processors
- •The graphics pipeline
- •Programmable pipeline stages
- •The Nvidia G80 as an example of the CUDA architecture
- •The architecture of modern graphics processors
- •General architecture overview. Nvidia Tesla
- •Memory subsystem
- •The GPU as a part of a hybrid system
- •Arithmetic precision. Accuracy and performance
- •Present and future of GPU architectures
- •Conclusions and implications on GPU computing
- •BLAS on single-GPU architectures
- •BLAS: Basic Linear Algebra Subprograms
- •BLAS levels
- •Naming conventions
- •Storage schemes
- •BLAS on Graphics Processors: NVIDIA CUBLAS
- •Evaluation of the performance of NVIDIA CUBLAS
- •Improvements in the performance of Level-3 NVIDIA CUBLAS
- •gemm-based programming for the Level-3 BLAS
- •Systematic development and evaluation of algorithmic variants
- •Experimental results
- •Impact of the block size
- •Performance results for rectangular matrices
- •Performance results for double precision data
- •Padding
- •Conclusions
- •LAPACK-level routines on single-GPU architectures
- •LAPACK: Linear Algebra PACKage
- •LAPACK and BLAS
- •Naming conventions
- •Storage schemes and arguments
- •LAPACK routines and organization
- •Cholesky factorization
- •Scalar algorithm for the Cholesky factorization
- •Blocked algorithm for the Cholesky factorization
- •Computing the Cholesky factorization on the GPU
- •Basic implementations. Unblocked and blocked versions
- •Padding
- •Hybrid implementation
- •LU factorization
- •Scalar algorithm for the LU factorization
- •Blocked algorithm for the LU factorization
- •LU factorization with partial pivoting
- •Computing the LU factorization with partial pivoting on the GPU
- •Basic implementations. Unblocked and blocked versions
- •Padding and hybrid algorithm
- •Reduction to tridiagonal form on the graphics processor
- •The symmetric eigenvalue problem
- •Reduction to tridiagonal form. The LAPACK approach
- •Reduction to tridiagonal form. The SBR approach
- •Experimental Results
- •Conclusions
- •Matrix computations on multi-GPU systems
- •Linear algebra computation on multi-GPU systems
- •Programming model and runtime. Performance considerations
- •Programming model
- •Transfer management and spatial assignation
- •Experimental results
- •Impact of the block size
- •Number of data transfers
- •Performance and scalability
- •Impact of data distribution
- •Conclusions
- •Matrix computations on clusters of GPUs
- •Parallel computing memory architectures
- •Shared memory architectures
- •Distributed memory and hybrid architectures
- •Accelerated hybrid architectures
- •Parallel programming models. Message-passing and MPI
- •ScaLAPACK
- •PLAPACK
- •Elemental
- •Description of the PLAPACK infrastructure
- •Layered approach of PLAPACK
- •Usage of the PLAPACK infrastructure. Practical cases
- •Porting PLAPACK to clusters of GPUs
- •Experimental results
- •Conclusions
- •Conclusions
- •Conclusions and main contributions
- •Contributions for systems with one GPU
- •Contributions for clusters of GPUs
- •Related publications
- •Publications directly related with the thesis topics
- •Publications indirectly related with the thesis topics
- •Other publications
- •Open research lines
- •FLAME algorithms for the BLAS-3 routines
CHAPTER 5. MATRIX COMPUTATIONS ON MULTI-GPU SYSTEMS
SYRK on 4 GPUs on TESLA2 |
SYRK implementations on TESLA2 |
|
1000 |
Runtime Version 4 |
|
|
|
1000 |
|
Runtime Version 3 |
|
|
|
||
|
|
|
|
|
|
|
|
|
Runtime Version 2 |
|
|
|
|
|
|
Runtime Version 1 |
|
|
|
|
|
800 |
|
|
|
|
800 |
GFLOPS |
600 |
|
|
|
GFLOPS |
600 |
400 |
|
|
|
400 |
||
|
|
|
|
|
||
|
200 |
|
|
|
|
200 |
|
0 |
|
|
|
|
0 |
|
0 |
5000 |
10000 |
15000 |
20000 |
|
|
Algorithm-by-blocks on 4 GPUs |
|
|
|
|
Best blocked algorithm on 1 GPU |
|
|
|
|
NVIDIA CUBLAS on 1 GPU |
|
|
|
0 |
5000 |
10000 |
15000 |
20000 |
Matrix size |
Matrix size |
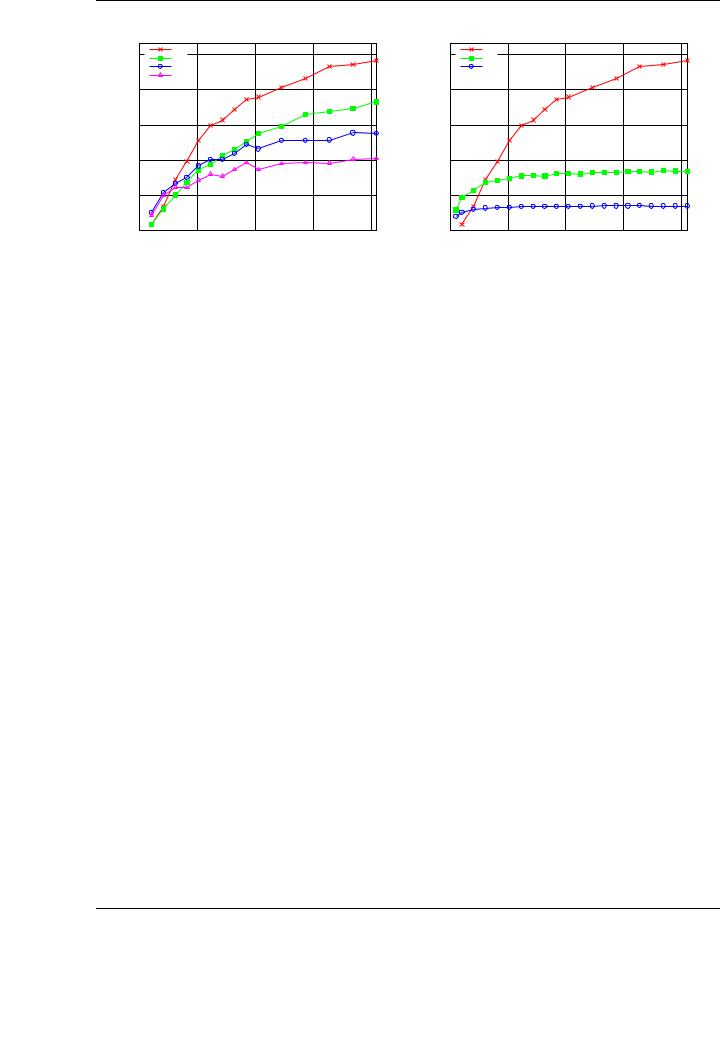
Figure 5.16: Performance (left) and comparison with mono-GPU implementations (right) of the SYRK implementation using 4 GPUs on TESLA2.
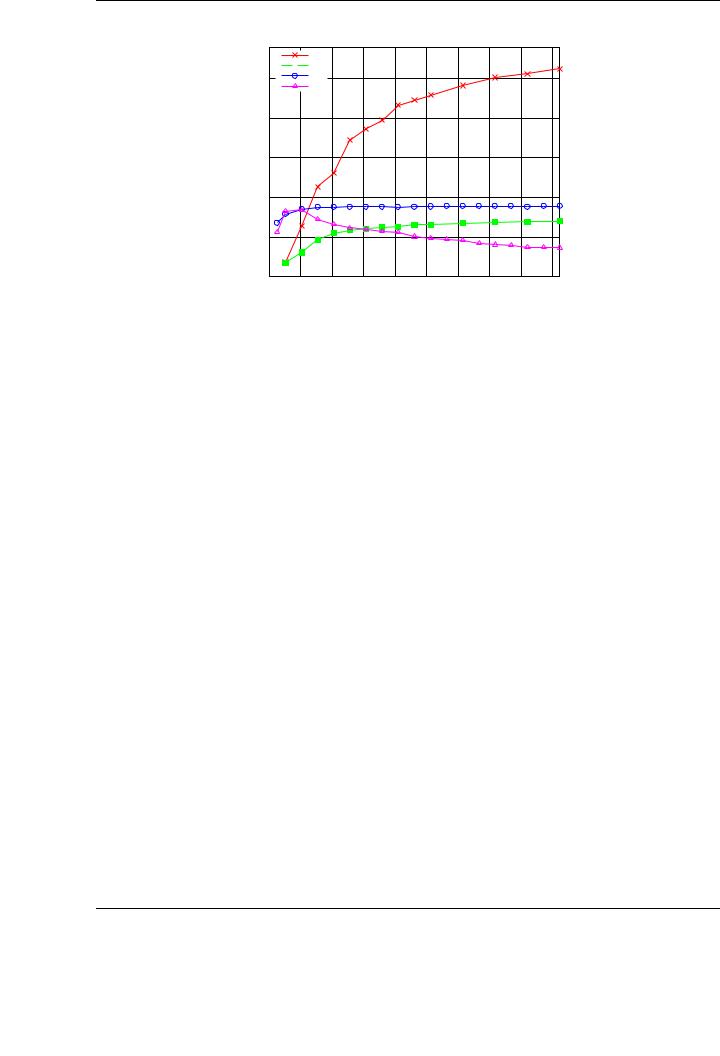
which could be gained from it are very similar to those already obtained for the Cholesky factorization and other BLAS routines. Instead, we perform a comparison of the algorithm-by-blocks on four GPUs of TESLA2, the same algorithm on only one GPU, our tuned blocked implementation on one GPU, and the NVIDIA CUBLAS implementation.
Figure 5.17 compares the best performance attained using the run-time system on the multiGPU setup (with four GPUs) with the three mono-GPU implementations. Note that we attain more than 1 TFLOP of peak performance using four GPUs in the same system for the largest tested matrices. In particular, the performance rate for n = 20,480 is 1.1 TFLOP.
Compared with the single-GPU implementations, we attain 376 GFLOPS in our best blocked algorithm implementation (see Chapter 3 for more details), 295 GFLOPS in a mono-GPU implementation using the developed runtime, and 119 GFLOPS using the NVIDIA CUBLAS implementation.
5.6.Conclusions
The emergence of a new hardware architecture usually involves extensive e orts from the software point of view in order to exploit its full potential. Multi-GPU systems are not an exception, and several works have advocated for low-level ad-hoc implementations to fully exploit the huge performance available in this type of architectures.
Following the rationale of the rest of this thesis, our approach and main contribution is essentially di erent. We advocate for a high-level approach, which abstracts the library developer from the particularities of the underlying architecture, and still considers performance as the main goal of our implementations.
To accomplish this, our first contribution is a reformulation of multi-GPUs, viewing them as a multi-core architecture, and considering each GPU in the system as a single core. With this analogy, many well-known concepts and techniques successfully applied in the past for sharedand distributed-memory programming can be also applied to modern multi-GPU architectures.
However, there are specific characteristics of this kind of architectures that pose challenging difficulties for the implementation of e cient run-time systems; specifically, we refer to data transfers and separate memory spaces. In response to this problem, a second contribution of the chapter is
160
5.6. CONCLUSIONS
GEMM implementations on TESLA2
GFLOPS
|
|
Algorithm-by-blocks on 4 |
GPUs |
1000 |
|
Algorithm-by-blocks on 1 |
GPU |
|
|||
|
|||
|
Best blocked algorithm on 1 GPU |
||
|
|
NVIDIA CUBLAS on 1 GPU |
|
800 |
|
|
|
600
400
200 |
|
|
|
|
|
|
|
|
|
0 |
|
|
|
|
|
|
|
|
|
0 |
2000 |
4000 |
6000 |
8000 |
10000 |
12000 |
14000 |
16000 |
18000 |
Matrix size
Figure 5.17: Performance comparison with mono-GPU implementations of the GEMM implementation using 4 GPUs on TESLA2.
a run-time system that is not only responsible of exploiting task parallelism, scheduling tasks to execution units or tracking data dependencies, but also transparently and e ciently handling data transfers between GPUs.
We have introduced techniques to reduce the amount of data transfers and thus increase data locality as well. We have also validated the e ciency of the runtime by evaluating many well-known dense linear algebra operations. The scalability and peak performance of the implementations is remarkable. Although the programmability of the solution is di cult to measure, the FLAME programming model allows a straightforward transition between existing sequential codes and parallel codes exploiting task parallelism.
Another remarkable contribution of the work is the fact that the major part of the concepts and techniques presented are not exclusive of a given runtime system or even a specific architecture. From this point of view, similar techniques have been applied by the author of the thesis to port the SMPSs runtime to platforms with multiple GPUs in a transparent way for the programmer [16]. This runtime (GPUSs) has been successfully tested with other type of hardware accelerators (ClearSpeed boards [50]) with similar performance results, is a clear demonstration of the portability of the proposed solution.
161

CHAPTER 5. MATRIX COMPUTATIONS ON MULTI-GPU SYSTEMS
162
Part IV
Matrix computations on clusters of GPUs
163