

- •Matrix computations on systems equipped with GPUs
- •Introduction
- •The evolution of hardware for High Performance Computing
- •The programmability issue on novel graphics architectures
- •About this document. Motivation and structure
- •Motivation and goals
- •Structure of the document
- •Description of the systems used in the experimental study
- •Performance metrics
- •Hardware description
- •Software description
- •The FLAME algorithmic notation
- •The architecture of modern graphics processors
- •The graphics pipeline
- •Programmable pipeline stages
- •The Nvidia G80 as an example of the CUDA architecture
- •The architecture of modern graphics processors
- •General architecture overview. Nvidia Tesla
- •Memory subsystem
- •The GPU as a part of a hybrid system
- •Arithmetic precision. Accuracy and performance
- •Present and future of GPU architectures
- •Conclusions and implications on GPU computing
- •BLAS on single-GPU architectures
- •BLAS: Basic Linear Algebra Subprograms
- •BLAS levels
- •Naming conventions
- •Storage schemes
- •BLAS on Graphics Processors: NVIDIA CUBLAS
- •Evaluation of the performance of NVIDIA CUBLAS
- •Improvements in the performance of Level-3 NVIDIA CUBLAS
- •gemm-based programming for the Level-3 BLAS
- •Systematic development and evaluation of algorithmic variants
- •Experimental results
- •Impact of the block size
- •Performance results for rectangular matrices
- •Performance results for double precision data
- •Padding
- •Conclusions
- •LAPACK-level routines on single-GPU architectures
- •LAPACK: Linear Algebra PACKage
- •LAPACK and BLAS
- •Naming conventions
- •Storage schemes and arguments
- •LAPACK routines and organization
- •Cholesky factorization
- •Scalar algorithm for the Cholesky factorization
- •Blocked algorithm for the Cholesky factorization
- •Computing the Cholesky factorization on the GPU
- •Basic implementations. Unblocked and blocked versions
- •Padding
- •Hybrid implementation
- •LU factorization
- •Scalar algorithm for the LU factorization
- •Blocked algorithm for the LU factorization
- •LU factorization with partial pivoting
- •Computing the LU factorization with partial pivoting on the GPU
- •Basic implementations. Unblocked and blocked versions
- •Padding and hybrid algorithm
- •Reduction to tridiagonal form on the graphics processor
- •The symmetric eigenvalue problem
- •Reduction to tridiagonal form. The LAPACK approach
- •Reduction to tridiagonal form. The SBR approach
- •Experimental Results
- •Conclusions
- •Matrix computations on multi-GPU systems
- •Linear algebra computation on multi-GPU systems
- •Programming model and runtime. Performance considerations
- •Programming model
- •Transfer management and spatial assignation
- •Experimental results
- •Impact of the block size
- •Number of data transfers
- •Performance and scalability
- •Impact of data distribution
- •Conclusions
- •Matrix computations on clusters of GPUs
- •Parallel computing memory architectures
- •Shared memory architectures
- •Distributed memory and hybrid architectures
- •Accelerated hybrid architectures
- •Parallel programming models. Message-passing and MPI
- •ScaLAPACK
- •PLAPACK
- •Elemental
- •Description of the PLAPACK infrastructure
- •Layered approach of PLAPACK
- •Usage of the PLAPACK infrastructure. Practical cases
- •Porting PLAPACK to clusters of GPUs
- •Experimental results
- •Conclusions
- •Conclusions
- •Conclusions and main contributions
- •Contributions for systems with one GPU
- •Contributions for clusters of GPUs
- •Related publications
- •Publications directly related with the thesis topics
- •Publications indirectly related with the thesis topics
- •Other publications
- •Open research lines
- •FLAME algorithms for the BLAS-3 routines
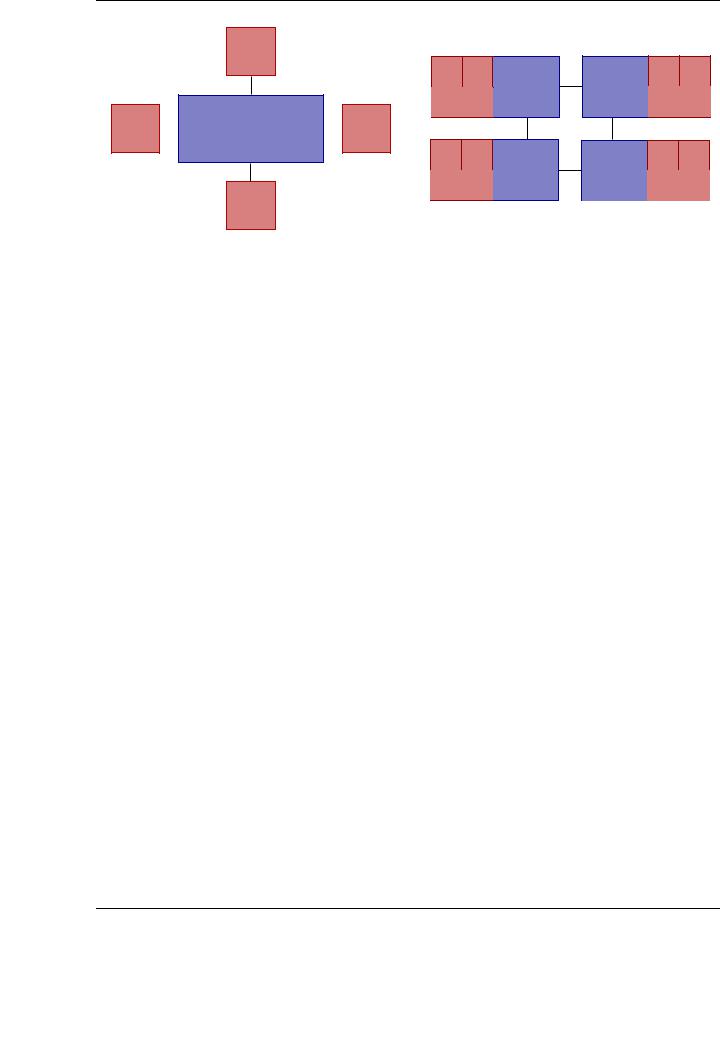
CHAPTER 6. MATRIX COMPUTATIONS ON CLUSTERS OF GPUS
CPU |
|
CPU CPU |
CPU CPU |
Memory |
Memory |
CPU CPU |
CPU CPU |
CPU |
|
Memory |
|
CPU |
|
|
CPU CPU |
CPU CPU |
Memory |
Memory |
CPU CPU |
CPU CPU |
CPU |
|
(a) UMA architecture |
(b) NUMA architecture |
Figure 6.1: Shared-memory architectures. UMA (a) and NUMA (b) implementations
All experiments presented through the chapter were carried out using up to 32 nodes of a cluster of GPUs (LONGHORN) with a fast Infiniband interconnection. The specific hardware and software details of the experimental setup were presented in Section 1.3.2.
6.1.Parallel computing memory architectures
The development of clusters of GPUs (distributed-memory architectures with one or more GPUs attached to each node in the cluster) is the natural result of the evolution of HPC architectures through the years. The reason underlying this change is the continuous grow in the performance requirements of scientific and engineering applications. In this section we review the basic features of shared-memory, distributed-memory, hybrid shared-distributed memory and accelerated architectures.
6.1.1.Shared memory architectures
In general, shared-memory architectures are characterized by the ability of the processors in the system to access to a common global memory space. This fact implies that, although processors can work independently on the same shared resources, when a memory location is changed by a processor this modification is visible to all other processors.
Considering the relation between the specific core that performs a memory transaction and the access time imposed by the architecture to accomplish it, shared-memory architectures can be divided into two main groups. In UMA (Unified Memory Access) architectures, the access time to memory is constant independently from the processor that requests the memory access, provided there are no contentions. In these architectures, cache coherency is maintained in hardware. This architecture is widely represented by SMP processors. On the other hand, NUMA (Non-Unified Memory Access) architectures are usually built as sets of SMP processors communicated via a fast interconnect. In these systems a processor of an SMP can directly access memory physically located in other SMPs. This implies that not all processors experience the same access time to a given memory address. If cache coherence is maintained, the architecture is usually referred as cc-NUMA (Cache Coherent NUMA). Figure 6.1 shows an schematic diagram of the UMA and NUMA implementations of typical shared-memory architectures.
166

6.1. PARALLEL COMPUTING MEMORY ARCHITECTURES
The main advantages of this type of architecture are their programmability and performance. First, the existence of a global address space provides a user-friendly programming view. Second, data sharing and communication between tasks is fast due to the proximity of memory to CPUs.
On the other hand, the disadvantages come from scalability and data coherency. Its primary drawback is the lack of scalability between memory and CPUs: the number of processing units that can be added to a shared-memory architecture without losing performance due to limited memory bandwidth is fixed and small. Moreover, the addition of more processors can rapidly increase tra c on the shared memory-CPU interconnection, and for cache coherent systems, this implies a fast increase in tra c associated with cache/memory management. In addition, it is the programmer’s responsibility to build the synchronization constructs that ensure a correct access pattern to global shared memory.
As a final problem of the shared-memory architecture, the cost of designing and building sharedmemory machines with increasing number of processors becomes a real problem as the limit of the memory bandwidth is reached by the processing power of the increasing number of computing units. Thus, distributed-memory machines or hybrid distributed-shared machines appear as the natural solution to the problem.
6.1.2.Distributed memory and hybrid architectures
Like shared-memory systems, distributed-memory architectures can present a number of di erent configurations and variations, even though all share some basic features. A distributed-memory architecture presents a set of processors, each one with a local memory, interconnected through a network. Memory addresses in one processor are private and do not map to other processors. There is no common global address space for all processors. In this sense, as all processors operate independently and the modifications in private data by one of them do not a ect the rest, there is no cache coherence concept in distributed-memory architectures.
Explicit communications are required if a processor needs data that are private to other processor. The programmer is in charge of defining which data and when that data needs to be transferred. Analogously, process synchronization is responsibility of the programmer. Although fast interconnection networks are commonly used, there is no limitation in the type of network that can be used in these architectures.
The reasons for the arise and success of distributed-memory architectures are directly related to the main advantages of this type of architectures, namely:
Memory: In shared-memory architectures, memory does not scale with the number of processors, and becomes a dramatic bottleneck as this number reaches a given limit. In distributedmemory architectures, memory is scalable with number of processors.
No cache coherence protocols: In distributed-memory architectures, each processor can e - ciently access its own private memory without interferences and without the overhead associated to the use of cache-coherence protocols.
Cost: Distributed-memory architectures can use commodity technology for processors and networking. Shared-memory computers are usually an expensive solution for HPC.
On the other hand, distributed-memory architectures present a number of disadvantages. First, in this model the programmer is responsible for many of the aspects associated with data communication and synchronization between di erent processes. In addition, the adaptation of existing codes with complex data structures can become a problem from the programmability point of
167
CHAPTER 6. MATRIX COMPUTATIONS ON CLUSTERS OF GPUS
Memory |
CPU |
|
Memory |
CPU |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Memory |
CPU |
Memory |
CPU |
(a) Distributed-memory architecture
Video
Memory GPU
|
CPU CPU |
CPU CPU |
Memory |
|
Memory |
|
CPU CPU |
CPU CPU |
|
CPU CPU |
CPU CPU |
Memory |
|
Memory |
|
CPU CPU |
CPU CPU |
|
(b) Hybrid architecture |
|
GPU |
Video |
|
Memory |
|
|
|
|
|
CPU CPU
Memory
CPU CPU
CPU CPU
Memory
CPU CPU
CPU CPU
Memory
CPU CPU
CPU CPU
Memory
CPU CPU
|
|
|
|
|
Video |
GPU |
|
GPU |
Video |
Memory |
|
Memory |
||
|
|
|
||
|
|
|
|
|
(c) Accelerated hybrid architecture
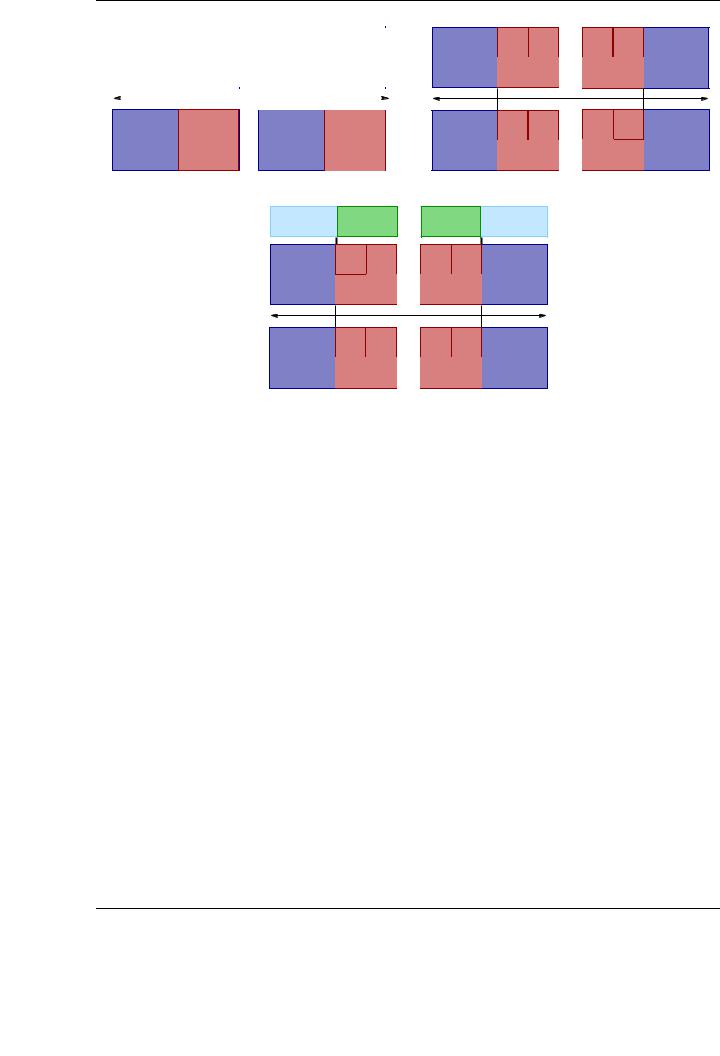
Figure 6.2: Distributed-memory architectures. Classic (a), hybrid (b) and accelerated hybrid (c) implementations
view. A non-uniform memory access (NUMA) prevails as the cost of the communication between two processors is not uniform and must be taken into account on the software side.
As a variation of purely distributed-memory machines, in practicehybrid distributed-shared memory architectures are currently the most common alternative in the HPC arena. Each component in the architecture is typically a cache-coherent SMP architecture. As processors in each node can address own memory as local, other processors can address that machine’s memory as global. An interconnection network is still needed for the communications between SMPs. Current trends indicate that this type of architecture is likely to prevail and even increase its numbers in the near future. The advantages and drawbacks of this type of architecture are directly inherited from those of purely shared and distributed-memory architectures. Figure 6.2 shows an schematic diagram of common distributed-memory and hybrid architectures.
6.1.3.Accelerated hybrid architectures
The complexity inherent to hybrid distributed-shared memory architectures has been increased with the introduction of new processing elements in each computing node. These accelerated hybrid distributed-shared memory architectures have been recently introduced in response to the higher necessity of computing power from modern HPC applications.
The appearance of accelerated hybrid distributed-memory architectures, with mixed CPU-GPU capabilities per node, is a natural step in response to:
168