

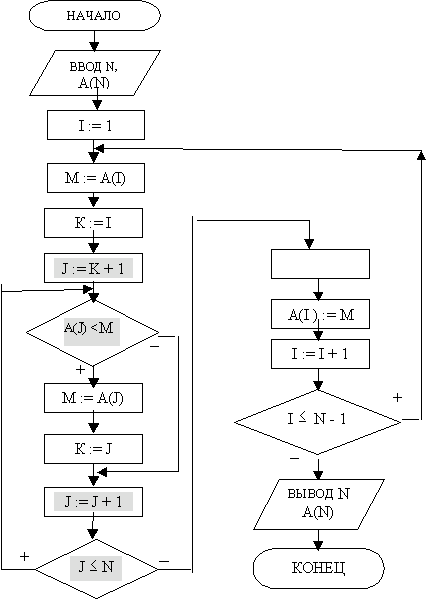
8,9 Алгоритм сортировки массива методом выбора (словесное описание, блок-схема, трассировка).
Этот метод основывается на алгоритме поиска минимального элемента. В массиве А(1..n) отыскивается минимальный элемент, который ставится на первое место. Для того, чтобы не потерять элемент , стоящий на первом месте , этот элемент устанавливается на место минимального . Затем в усеченной последовательности, исключая первый элемент, отыскивается минимальный элемент и ставится на второе место и так далее n-1 раз пока не встанет на свое место предпоследний n-1 элемент массива А, сдвинув максимальный элемент в самый конец.
Рассмотрим алгоритмическое решение задачи на примере сортировки некоторого массива значений по возрастанию. В соответствии с вышеописанным методом нам необходимо несколько раз выполнять операции поиска минимального элемента и его перестановку с другим элементом, то есть потребуется несколько раз просматривать элементы массива с этой целью. Количество просмотров элементов массива согласно описанию модифицированного метода простого выбора равно n-1, где n- количество элементов массива. Таким образом, можно сделать вывод, что проектируемый алгоритм сортировки будет содержать цикл, в котором будет выполняться поиск минимального элемента и его перестановка с другим элементом. Обозначим через i - счетчик (номер) просмотров элементов массива и изобразим обобщенный алгоритм сортировки на рис.
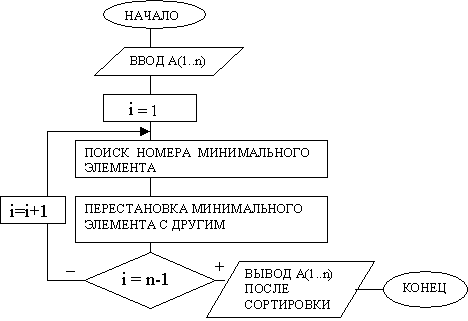
Отметим, что для перестановки элементов местами необходимо знать их порядковые номера, алгоритм перестановки элементов массива был рассмотрен ранее (см. рис. 23). Алгоритмы ввода исходного массива и вывода этого же массива после сортировки изображены на рисунках 16 и 24 соответственно. Алгоритм поиска в массиве минимального элемента и его номера будет аналогичен рассмотренному в примере 10 алгоритму поиска максимального элемента, который представлен на рис.18. Однако, в этом алгоритме будут внесены изменения. Для того, чтобы определить какие изменения следует внести рассмотрим выполнение сортировки данным методом с акцентом на поиск минимального элемента на конкретном примере. Пусть исходный массив содержит 5 элементов (2,8,1,3,7). Количество просмотров согласно модифицированному методу простого выбора будет равно 4. Покажем в таблице 7, как будет изменяться исходный массив на каждом просмотре.
Таблица 7. Пример сортировки
i |
Исходный массив |
Минимальный элемент |
Переставляемый элемент |
Массив после перестановки |
|||
Номер |
Значение |
Номер |
Значение |
||||
1 |
(2,8,1,3,7) |
3 |
1 |
1 |
2 |
(1,8,2,3,7) |
|
2 |
1,(8,2,3,7) |
3 |
2 |
2 |
8 |
1,(2,8,3,7) |
|
3 |
1,2,(8,3,7) |
4 |
3 |
3 |
8 |
1,2,(3,8,7) |
|
4 |
1,2,3,(8,7) |
5 |
7 |
4 |
8 |
1,2,3,7,8 |
|
Из данных, приведенных в таблице 7, следует, что поиск минимального значения в массиве на каждом просмотре осуществляется в сокращенном массиве, который сначала начинается с первого элемента, а на последнем просмотре массив, в котором ищется минимальный элемент начинается уже с четвертого (или n-1) элемента. При этом можно заметить, что номер первого элемента массива для каждого поиска и перестановки совпадает с номером просмотра i.
Введем следующие обозначения :
К- номер минимального элемента,
J - номер элемента массива,
М и А(К)- одно и тоже значение минимального элемента массива,
i - номер переставляемого с минимальным элемента,
А(i)- значение переставляемого элемента.
Тогда циклический алгоритм сортировки модифицированным методом простого выбора будет выглядеть следующим образом (рис)
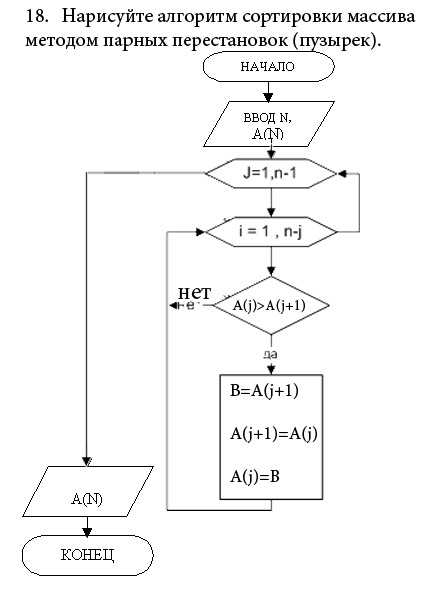
10. Алгоритм сортировки массива методом парных перестановок (пузырек) (словесное описание, блок-схема, трассировка).
11. Алгоритм сортировки массива методом парных перестановок (камушек) (словесное описание, блок-схема, трассировка).

12. Алгоритм бинарного поиска (словесное описание, блок-схема, трассировка).
Метод бинарного поиска применяется в массиве, элементы которого упорядочены по некоторому критерию (упорядоченный массив)

13. Структуры данных. Классификация, действия со структурами данных.
Структуры данных – совокупность элементов и связей между ними.
Действия:
1. Создание структуры данных
2. Уничтожение структуры данных
3. Доступ к элементам структур
4. Изменение элементов структур
Существует общая классификация структур данных.
Понятие "ФИЗИЧЕСКАЯ структура данных" отражает способ физического представления данных в памяти машины и называется еще структурой хранения, внутренней структурой или структурой памяти.
Рассмотрение структуры данных без учета ее представления в машинной памяти называется абстрактной или ЛОГИЧЕСКОЙ структурой. В общем случае между логической и соответствующей ей физической структурами существует различие, степень которого зависит от самой структуры и особенностей той среды, в которой она должна быть отражена. Вследствие этого различия существуют процедуры, осуществляющие отображение логической структуры в физическую и, наоборот, физической структуры в логическую. Эти процедуры обеспечивают, кроме того, доступ к физическим структурам и выполнение над ними различных операций, причем каждая операция рассматривается применительно к логической или физической структуре данных.
Различаются ПРОСТЫЕ (базовые, примитивные) структуры (типы) данных и ИНТЕГРИРОВАННЫЕ (структурированные, композитные, сложные). Простыми называются такие структуры данных, которые не могут быть расчленены на составные части, большие, чем биты. С точки зрения физической структуры важным является то обстоятельство, что в данной машинной архитектуре, в данной системе программирования мы всегда можем заранее сказать, каков будет размер данного простого типа и какова структура его размещения в памяти. С логической точки зрения простые данные являются неделимыми единицами. Интегрированными называются такие структуры данных, составными частями которых являются другие структуры данных - простые или в свою очередь интегрированные. Интегрированные структуры данных конструируются программистом с использованием средств интеграции данных, предоставляемых языками программирования.
В зависимости от отсутствия или наличия явно заданных связей между элементами данных следует различать НЕСВЯЗНЫЕ структуры (векторы, массивы, строки, стеки, очереди) и СВЯЗНЫЕ структуры (связные списки).
Весьма важный признак структуры данных - ее изменчивость - изменение числа элементов и (или) связей между элементами структуры. В определении изменчивости структуры не отражен факт изменения значений элементов данных, поскольку в этом случае все структуры данных имели бы свойство изменчивости. По признаку изменчивости различают структуры СТАТИЧЕСКИЕ, ПОЛУСТАТИЧЕСКИЕ, ДИНАМИЧЕСКИЕ. Классификация структур данных по признаку изменчивости приведена на рис. 1.1. Базовые структуры данных, статические, полустатические и динамические характерны для оперативной памяти и часто называются оперативными структурами. Файловые структуры соответствуют структурам данных для внешней памяти.
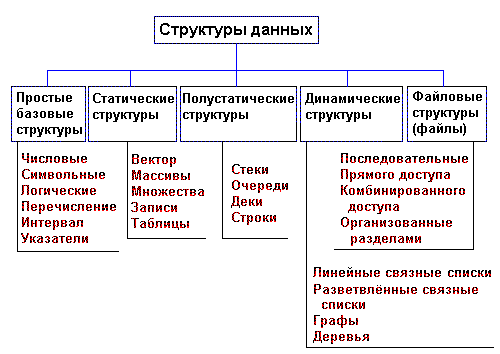
Рис. 1.1. Классификация структур данных
Важный признак структуры данных - характер упорядоченности ее элементов. По этому признаку структуры можно делить на ЛИНЕЙНЫЕ И НЕЛИНЕЙНЫЕ структуры.
В зависимости от характера взаимного расположения элементов в памяти линейные структуры можно разделить на структуры с ПОСЛЕДОВАТЕЛЬНЫМ распределением элементов в памяти (векторы, строки, массивы, стеки, очереди) и структуры с ПРОИЗВОЛЬНЫМ СВЯЗНЫМ распределением элементов в памяти ( односвязные, двусвязные списки). Пример нелинейных структур - многосвязные списки, деревья, графы.
14. Типы данных. Определение, классификация, примеры.
Классификация типов данных.
Существует несколько способов, по которым можно сгруппировать или разделить типы данных.
1. По способу объявления
Все типы данных делятся на предопределенные (встроенные) и на пользовательские (объявляемые). Встроенные типы данных - типы данных, о которых компилятор знает изначально. Пользователю не нужно объявлять эти типы данных, и он нигде не встретит действующего объявления этих типов данных. Пользовательские типы данных - типы данных, создаваемые пользователем на основании встроенных типов данных или путем комбинирования нескольких уже определенных типов данных, пользовательских или встроенных.
Пример: Тип данных Integer (32-ух разрядное знаковое целое) - встроенный. Тип данных DWord (32-ух разрядное беззнаковое целое) - пользовательский, производный от LongWord. Он объявлен программистами Borland в тексте библиотеки VCL.
2. По платформе
Типы данных разделяются на фундаментальные (fundamental) и общие (generic). Фундаментальные типы (их формат и множество значений) не зависят от реализации языка программирования, его версии, операционной системы и процессора. Формат и множество значений общих типов данных специфичны для конкретной платформы и могут варьироваться в зависимости от версии среды программирования, ОС и процессора. Следует стараться использовать общие типы данных, где это возможно, т.к. они предоставляют оптимальную производительность и переносимость программ. Однако зависимость формата от платформы может создать проблемы с совместимостью когда речь идет о хранении (файлы) и обработке данных вне программы (передача данных другим программам или ОС).
Пример: Тип данных Integer в версии Delphi 1 и в Turbo Pascal представлял собой 16-ти разрядное знаковое целое число. Теперь в 32-ух разрядных версиях Delphi этот тип данных является 32-ух разрядным. Вполне возможно, что при переходе на следующее поколение процессоров которые будут оперировать 64-ех битными машинными словами этот тип данных тоже станет 64-ех битным. В противоположность ему Byte всегда является 8-ми битным беззнаковым целым.
3. По характеру данных (см. рис. 1.2)
Простые типы данных. Простые (simple) - типы данных которые могут хранить ограниченное множество упорядоченных значений. Простые типы данных подразделяются в свою очередь на несколько подразделов в зависимости от своей функциональности.
Структурированные типы данных. Экземпляры структурированных типов данных могут содержать в себе одновременно несколько значений одного или даже различных типов. Структуры данных, которые занимают в памяти ПК постоянный объем называют статическими структурами. Динамические структуры могут изменять свою длину в процессе выполнения программы.

Рис. 1.2. Классификация типов данных.
15. Преобразование (приведение) типов данных
Преобразование (приведение) типов
Приведе́ние ти́па (type conversion) — преобразование значения переменной одного типа в значение другого типа. Выделяют явное и неявное приведения типов.
При неявном приведении преобразование происходит автоматически, по правилам, заложенным в данном языке программирования.
Само приведение происходит как во время присваивания значения переменной, так и при операциях сравнения, вычисления выражения. При использовании в выражении несколько различных типов значения одного или нескольких подтипов может быть осуществлено преобразование к более общему типу (супертипу), с большим диапазоном возможных значений.
Следует с осторожностью использовать неявное приведение типа. При переводе числа из вещественного типа в целочисленный, дробная часть откидывается. Обратное приведение из целочисленного типа к вещественному также может привести к понижению точности, что связано с различным представлением вещественных и целочисленных чисел на машинном уровне. К примеру, вещественный тип single стандарта IEEE 754 не может точно представить число 16777217, в то время как 32-битный целочисленный тип может. Это может привести к ситуациям, когда сравнение на равенство одного и того же числа, представленного типами (int и single) будет выдавать ложный результат (числа не равны друг другу).
При явном приведении указывается тип переменной, к которому необходимо преобразовать исходную переменную.
Также в языке могут быть заданы специальные функции для приведения.
О преобразовании числовых типов данных Паскаля
В Паскале почти невозможны неявные (автоматические) преобразования числовых типов данных. Исключение сделано только для типа integer, который разрешается использовать в выражениях типа real. Например, если переменные описаны следующим образом:
Var X : integer; Y: real;
то оператор
Y:= X+2;
будет синтаксически правильным, хотя справа от знака присваивания стоит целочисленное выражение, а слева – вещественная переменная, компилятор сделает преобразование числовых типов данных автоматически. Обратное же преобразование автоматически типа real в тип integer в Паскале невозможно. Вспомним, какое количество байт выделяется под переменные типа integer и real: под целочисленный тип данных integer выделяется 2 байта памяти, а под real – 6 байта. Для преобразования real в integer имеются две встроенные функции: round(x) округляет вещественное x до ближайшего целого, trunc(x) усекает вещественное число путем отбрасывания дробной части.
При явном преобразовании типов используются вызовы специальных функций преобразования, аргументы которых принадлежат одному типу, а значение - другому. Таковыми являются функции ORD, TRUNC, ROUND, CHR.
Приведение типов в С и С++
Рассмотрим вот такой код на С:
double d; // вещественный тип
long l; // целый тип
int i; // целый тип
if (d > i) d = i;
if (i > l) l = i;
if (d == l) d *= 2;
Каждый раз при выполнении операции сравнения или присваивания переменные разных типов будут приведены к единому типу.
Правило неявного приведения типа в С довольно простое: типы приводятся от меньших типов к большим. Т.е. если в выражении участвует одна переменная вещественного типа double и несколько переменных типов int, short, float, то все переменные будут приведены к типу double.
В приведенном выше примере при первом сравнении переменная i будет неявно приведена к типу double. Во втором сравнении переменная i будет приведена к типу long, в третье сравнении переменная l будет приведена к типу double.
Пример1. Что будет в конце выполнения этого кода?
float f=1.5;
int a=f;
//неявное приведение
f=a;
Ответ: f будет равно 1.
Пример2. Что будет в конце выполнения этого кода?
int A=128;
char B=A;
A=B;
Ответ: A будет равно -128.
Объяснение:
Справочные сведения
Целые числа представляются с помощью дополнительных кодов. Первый бит в данном формате означает знак числа: если бит равен 0, то число положительное, если 1 – отрицательное. Для положительного числа дополнительный код совпадает с прямым кодом числа. Прямой код целого числа может быть получен следующим образом: число переводится в двоичную систему счисления, а затем его двоичную запись слева дополняют таким количеством незначащих нулей, сколько требует тип данных, к которому принадлежит число.
Пример:
Число 37(10) = 100101(2) может быть объявлено величиной типа Int (шестнадцатибитовое со знаком), то его прямым кодом будет 0000000000100101, а если величиной типа LongInt (тридцатидвухбитовое со знаком), то его прямой код будет 00000000000000000000000000100101.
Дополнительный код целого отрицательного числа может быть получен по следующему алгоритму:
1. записать прямой код модуля числа;
2. инвертировать его (заменить единицы нулями, нули — единицами);
3. прибавить к инверсному коду единицу.
Пример:
Число 128 нужно представить в виде char (8-битное, знаковое). Тогда по алгоритму:
Прямой код числа:
№ бита
7
6
5
4
3
2
1
0
Значение бита
1
0
0
0
0
0
0
0
Результат инверсии:
№ бита
7
6
5
4
3
2
1
0
Значение бита
0
1
1
1
1
1
1
1
Результат суммирования с единицой:
№ бита |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
Значение бита |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
При обратном получении числа по его дополнительному коду прежде всего определяется его знак. Если число окажется положительным, то просто переводится его код в десятичную систему счисления. В случае отрицательного числа необходимо выполнить алгоритм, обратный получению доп.кода, т. е.:
вычесть из кода числа 1;
инвертировать код;
перевести в десятичную систему счисления. Полученное число записать со знаком минус.
Почему отрицательные числа представляются в дополнительном коде? Дело в том, что в этом случае операция вычитания двух чисел сводится к сложению с дополнительным кодом вычитаемого, и процессору достаточно уметь лишь складывать числа. В самом деле:
А - В = А + (-В).
Если значение (-В) будет иметь форму дополнительного кода, то в памяти ПК получится правильный результат.
При приведении типов, которые используют большее количество байт для хранения, к типам, которые используют меньше байт для хранения, могут возникать ошибки. Это связано с тем, что в этой ситуации копируется столько битов, сколько можно скопировать, начиная с младшего.
В данном примере переменная типа int кодируется 16 битами. Таким образом, в машинном представлении число 128 в формате int будет выглядеть так:
№ бита |
15 |
14 |
13 |
12 |
11 |
10 |
9 |
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
Значение бита |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
Переменная же типа char кодируется 8 битами, и на строчке “char B=A;” в char-переменную B записывается только 8 младших бит числа A:
№ бита |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
Значение бита |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
8-й бит равен 1, поэтому компилятор считает, что в B хранится отрицательное число, формирует его доп. код, который был рассмотрен в примере выше. На строчке «A=B» в A значение B копируется как отрицательное число.
Лучше пользоваться явным приведением типов.
Операция явного приведения типов в общем виде в С:
(тип) выражение,
т. е. для явного приведения типов некоторой переменной перед ней следует указать в круглых скобках имя нового типа.
Пример 1:
long l;
short s;
s=(short)l;
Пример 2.
Часть первая.
int x = 10; // Объявление переменной x типа int (целое число)
float y; // Объявление переменной y типа float
y=(float)x/3;//Перед делением на 3, значение переменной x приводится к типу float
После этого переменная y будет хранить число 3.333333
Часть вторая
Если написать такую же программу, но не ставить (float) перед x, то
int x = 10;//Объявление переменной x типа int (целое число)
float y;//Объявление переменной y типа float
y=x/3; //x - тип данных целое число, это число делится на 3 и мы получаем, что y=3!
Операция явного приведения типов в общем виде в С++:
Для явного приведения типов в С++ используется функция
static_cast<T>(a).
В круглые скобки (вместо а) ставится переменная или константа, а в угловые (вместо Т) – имя типа к которому нужно привести эту переменную или константу. Например,
long j = 17;
short i = static_cast<short>(j);
y = static_cast<signed short>(65534);// будет присвоено -2
В чем разница между С и С++? При стиле С комплиятор выдаст предупреждение о возможной потере точности. В стиле С++ этого не будет. static_cast<T>(a) - явное преобразование значения a к типу T, возможность которого определяется на этапе компиляции. Явное преобразование подразумевает, что разработчик в курсе возможной потери точности, значащих битов и т.п. Компилятор предупреждение не генерирует. В принципе, это некий аналог записи в стиле С. Корявый синтаксис этих кастов нужен, чтобы в коде он бросался в глаза и были сразу видны приведения. Запись типа int(x) такого эффекта не даёт
16. Типы языков программирования (машинные, ассемблеры, высокого уровня). Алфавит, синтаксис, семантика.
На сегодня существуют сотни языков программирования. Их можно разделить на три основных типа:
Машинные языки
Языки ассемблера
Языки высокого уровня
Рассмотрим краткую предысторию развития языков программирования. Итак, любой компьютер может непосредственно понимать лишь свой собственный машинный язык. Машинный язык - это "природный язык" определенного компьютера. Он определяется при проектировании аппаратных средств этого компьютера. Машинные языки в общем случае содержат строки чисел (в конечном счете сокращенные до единиц и нулей), которые являются командами компьютеру на выполнение большинства элементарных операций в тот или иной момент времени. Машинные языки машинно-зависимы, т.е. каждый машинный язык может быть использован только на компьютере одного определенного типа. Машинные языки тяжелы для человеческого восприятия, как это можно видеть из следующего примера программы на машинном языке, которая складывает сверхурочную зарплату с основной и запоминает результат как общую зарплату:
+1300042774
+1400593419
+1200274027
По мере повышения популярности компьютеров стало очевидно, что программирование на машинных языках просто слишком медленно и утомительно для большинства программистов. Вместо использования строк чисел, которые компьютер мог бы понимать непосредственно, программисты начали использовать похожие на английский язык аббревиатуры для представления элементарных компьютерных операций. Эти аббревиатуры, напоминающие английский язык, сформировали основу языков ассемблера. Для преобразования программ на языке ассемблера в машинный язык со скоростью компьютера были разработаны программы трансляции, называемые ассемблерами. Следующий фрагмент программы на языке ассемблера также складывает сверхурочную зарплату (OVERPAY) с основной (BASEPAY) и запоминает результат как общую зарплату (GROSSPAY), но он более понятен по сравнению со своим машинным аналогом:
LOAD BASEPAY
ADD OVERPAY
STORE GROSSPAY
Хотя такой код более понятен людям, он непонятен компьютеру до тех пор, пока не будет преобразован в компьютерный код (т.е. в машинный язык). Напомню, что преобразование происходит с помощью специальной программы-транслятора, называемой ассемблером.
Использование компьютеров резко возросло с появлением языков ассемблера, но эти языки все еще требовали много команд для полного описания даже простых задач. Для ускорения процесса программирования были разработаны языки высокого уровня, в которых иногда достаточно написать всего один оператор для решения реальной задачи. Программы трансляции, которые преобразуют программы на языках высокого уровня в машинные коды, называются компиляторами. Языки высокого уровня позволяют программисту писать программы, которые выглядят почти так же, как повседневный английский, и используют общепринятую математическую нотацию. Программа расчета зарплаты, написанная на языке высокого уровня, могла бы содержать такой оператор как:
grossPay = basePay + overTimePay;
Очевидно, что языки высокого уровня гораздо удобнее с точки зрения программистов по сравнению с языками ассемблера и машинными кодами.
Основными элементами любого языка программирования являются: алфавит, синтаксис и семантика.
Алфавит - это набор символов, которые можно применять в инструкциях языка программирования. Другие символы допустимы только в особых случаях, например в строковых константах.
Синтаксис - это формальные правила построения отдельных конструкций (команд, операторов) языка из символов алфавита. Задает набор цепочек символов, которые принадлежат языку
Семантика - смысловое содержание тех или иных синтаксических конструкций языка. Это смысловое содержание операторов языка программирования. Семантические правила определяют действия, описываемые различными операторами, и, в итоге, сущность всего алгоритма.
Таким образом, программа составляется с помощью соединения символов алфавита в соответствии с синтаксическими правилами и с учетом правил семантики.
Алфавит и синтаксис языков программирования определяется, исходя из стремления приблизить их к языку человека, но вместе с тем обеспечить возможность перевода записи алгоритма с языка программирования на машинный язык. В отличие от языка человека языкам программирования свойственна строгость синтаксических и семантических правил.
Конструкции современных языков имеют общее содержание (семантику), но различный порядок следования компонент (синтаксис) и разные ключевые слова (лексику). Поскольку содержание создаваемой программы определяется семантикой, постольку различные языки дают программисту одинаковые возможности (при различном внешнем виде программ).
17. Транслятор, компилятор, интерпретатор. Определения, сходства и различия, особенности работы

Цель трансляции — преобразовать текст с одного языка на другой, который понятен адресату текста. В случае программ-трансляторов, адресатом является техническое устройство (процессор) или программа-интерпретатор.
Основная статья: Компилятор
Язык процессоров (машинный код) обычно является низкоуровневым. Существуют платформы, использующие в качестве машинного язык высокого уровня (например, iAPX-432[5]), но они являются исключением из правила в силу сложности и дороговизны. Транслятор, который преобразует программы в машинный язык, принимаемый и исполняемый непосредственно процессором, называется компилятором.[6]
Процесс компиляции как правило состоит из нескольких этапов: лексического, синтаксического и семантического анализов, генерации промежуточного кода, оптимизации и генерации результирующего машинного кода. Помимо этого, программа как правило зависит от сервисов, предоставляемых операционной системой и сторонними библиотеками (например, файловый ввод-вывод или графический интерфейс), и машинный код программы необходимо связать с этими сервисами. Связывание со статическими библиотеками выполняется редактором связей или компоновщиком (который может представлять собой отдельную программу или быть частью компилятора), а с операционной системой и динамическими библиотеками связывание выполняется при начале исполнения программы загрузчиком.
Достоинство компилятора: программа компилируется один раз и при каждом выполнении не требуется дополнительных преобразований. Соответственно, не требуется наличие компилятора на целевой машине, для которой компилируется программа. Недостаток: отдельный этап компиляции замедляет написание и отладку и затрудняет исполнение небольших, несложных или разовых программ.
Основная статья: Ассемблер
В случае, если исходный язык является языком ассемблера (низкоуровневым языком, который является мнемоническим представлением машинных команд процессора), то компилятор такого языка называется ассемблером.
Алгоритм работы простого интерпретатора
прочитать инструкцию;
проанализировать инструкцию и определить соответствующие действия;
выполнить соответствующие действия;
если не достигнуто условие завершения программы, прочитать следующую инструкцию и перейти к пункту 2.
Простой интерпретатор анализирует и тут же выполняет (собственно интерпретация) программу покомандно (или построчно), по мере поступления её исходного кода на вход интерпретатора. Достоинством такого подхода является мгновенная реакция. Недостаток — такой интерпретатор обнаруживает ошибки в тексте программы только при попытке выполнения команды (или строки) с ошибкой.
Интерпретатор компилирующего типа — это система из компилятора, переводящего исходный код программы в промежуточное представление, например, в байт-код или p-код, и собственно интерпретатора, который выполняет полученный промежуточный код (так называемая виртуальная машина). Достоинством таких систем является большее быстродействие выполнения программ (за счёт выноса анализа исходного кода в отдельный, разовый проход, и минимизации этого анализа в интерпретаторе). Недостатки — большее требование к ресурсам и требование на корректность исходного кода. Применяется в таких языках, как Java, Tcl, Perl (используется байт-код[источник не указан 968 дней]), REXX (сохраняется результат парсинга исходного кода[5]), а также в различных СУБД (используется p-код[источник не указан 968 дней]).
В случае разделения интерпретатора компилирующего типа на компоненты получаются компилятор языка и простой интерпретатор с минимизированным анализом исходного кода. Причём исходный код для такого интерпретатора не обязательно должен иметь текстовый формат или быть байт-кодом, который понимает только данный интерпретатор, это может быть машинный код какой-то существующей аппаратной платформы. К примеру, виртуальные машины вроде QEMU, Bochs, VMware включают в себя интерпретаторы машинного кода процессоров семейства x86.
Некоторые интерпретаторы (например, для языков Лисп, Scheme, Python, Бейсик и других) могут работать в режиме диалога или так называемого цикла чтения-вычисления-печати (англ. read-eval-print loop, REPL). В таком режиме интерпретатор считывает законченную конструкцию языка (например, s-expression в языке Лисп), выполняет её, печатает результаты, после чего переходит к ожиданию ввода пользователем следующей конструкции.
Уникальным является язык Forth, который способен работать как в режиме интерпретации, так и компиляции входных данных, позволяя переключаться между этими режимами в произвольный момент, как во время трансляции исходного кода, так и во время работы программ.[6]
Следует также отметить, что режимы интерпретации можно найти не только в программном, но и аппаратном обеспечении. Так, многие микропроцессоры интерпретируют машинный код с помощью встроенных микропрограмм, а процессоры семейства x86, начиная с Pentium (например, на архитектуре Intel P6), во время исполнения машинного кода предварительно транслируют его во внутренний формат (в последовательность микроопераций).
Большинство компиляторов компилирует (в том числе транслирует) программу с некоторого высокоуровневого языка программирования в машинный код, который может быть непосредственно выполнен центральным процессором. Как правило, этот код также ориентирован на исполнение в среде конкретной операционной системы, поскольку использует предоставляемые ею возможности (системные вызовы, библиотеки функций, API). Архитектура или платформа (набор программно-аппаратных средств), для которой производится компиляция, называется целевой машиной или, также, целевой платформой.
Некоторые компиляторы (например, Java) переводят программу не в машинный код, а в программу на некотором специально созданном низкоуровневом интрепретируемом языке. Такой язык — байт-код (в случае с Java Java-байт-код) — также можно считать языком машинных команд, поскольку в качестве его интерпретатора используется виртуальная машина. Байт-код не является машинным кодом какого-либо компьютера, то есть машинным кодом в прямом смысле слова, и может переноситься на различные компьютерные архитектуры без перекомпиляции. Байт-код интерпретируется (исполняется) виртуальной машиной.
Например, для языка Java это JVM (язык виртуальной машины Java), или так называемый байт-код Java (вслед за ним все промежуточные низкоуровневые интрепретируемые языки стали называть байт-кодами). Для языков программирования на платформе .NET Framework (C#, Managed C++, Visual Basic .NET и другие) — это MSIL (Microsoft Intermediate Language).
Программа на байт-коде подлежит интерпретации виртуальной машиной, либо ещё одной компиляции уже в машинный код непосредственно перед исполнением. Последнее называется «Just-In-Time компиляция» (JIT), по названию подобного компилятора для Java. MSIL-код компилируется в код целевой машины также JIT-компилятором, а библиотеки .NET Framework компилируются заранее.
Для каждой целевой машины (IBM, Apple, Sun и т. д.) и каждой операционной системы или семейства операционных систем, работающих на целевой машине, требуется написание своего компилятора. Существуют также так называемые кросс-компиляторы, позволяющие на одной машине и в среде одной ОС генерировать код, предназначенный для выполнения на другой целевой машине и/или в среде другой ОС. Кроме того, компиляторы могут быть оптимизированы под разные типы процессоров из одного семейства (путём поддержки специфичных для этих процессоров машинных команд). Например, код, скомпилированный под процессоры семейства Pentium, может использовать специфичные для этих процессоров наборы инструкций — MMX, SSE, SSE2.
Также существуют компиляторы, переводящие программу с языка высокого уровня на язык ассемблера. (Правда такие компиляторы, вообще-то следовало бы называть трансляторами…) К таким компиляторам относится, например, PureBasic.
Существуют программы, которые решают обратную задачу — перевод программы с низкоуровневого языка на высокоуровневый. Этот процесс называют декомпиляцией, а такие программы — декомпиляторами. (Яркий пример таких программ — дизассемблеры) Но поскольку компиляция — это процесс с потерями, точно восстановить исходный код, скажем, на C++, в общем случае невозможно. Более эффективно декомпилируются программы в байт-кодах — например, существует довольно надёжный декомпилятор для Flash. Разновидностью декомпилирования является дизассемблирование машинного кода в код на языке ассемблера, который всегда выполняется успешно. Связано это с тем, что между кодами машинных команд и командами ассемблера имеется практически взаимно-однозначное соответствие.
Любой компилятор состоит из транслятора и компоновщика. Часто в качестве компоновщика компилятор использует внешний компоновщик, реализованный в виде самостоятельной программы, а сам выполняет лишь трансляцию исходного текста (по этой причине многие ошибочно считают компилятором разновидность транслятора). Компилятор может быть реализован и как своеобразная программа-менеджер, для трансляции программы вызывающая соответствующий транслятор (трансляторы — если разные части программы написаны на разных языках программирования) и затем — для компоновки программы, — вызывающая компоновщик. Ярким примером такого компилятора является имеющаяся во всех UNIX-системах (и Linux-системах в том числе) утилита make (имеются реализации утилиты make и в других системах, в частности в Windows-системах).
Процесс компиляции состоит из следующих фаз:
Лексический анализ. На этой фазе последовательность символов исходного файла преобразуется в последовательность лексем.
Синтаксический (грамматический) анализ. Последовательность лексем преобразуется в древо разбора.
Семантический анализ. Древо разбора обрабатывается с целью установления его семантики (смысла) — например, привязка идентификаторов к их определениям, типам данных, проверка совместимости типов данных, определение результирующих типов данных выражений и т. д. Результат обычно называется «промежуточным представлением/кодом», и может быть дополненным древом разбора, новым древом, абстрактным набором команд или чем-то ещё, удобным для дальнейшей обработки.
Оптимизация. Удаляются избыточные команды и упрощается (где это возможно) код с сохранением его смысла, то есть реализуемого им алгоритма (в том числе предвычисляются (то есть вычисляются на фазе трансляции) выражения, результаты которых практически являются константами). Оптимизация может быть на разных уровнях и этапах — например, над промежуточным кодом или над конечным машинным кодом.
Генерация кода. Из промежуточного представления порождается код на целевом языке (в том числе выполняется компоновка программы).
В конкретных реализациях компиляторов эти фазы могут быть разделены или, наоборот, совмещены в том или ином виде.
Важной исторической особенностью компилятора, отражённой в его названии (англ. compile — собирать вместе, составлять), являлось то, что он мог производить как трансляцию так и компоновку (то есть состоял из двух частей — транслятора и компоновщика). Это связано с тем, что раздельные трансляция и компоновка как отдельные фазы компиляции выделились значительно позже появления компиляторов. В связи с этим, вместо термина «компилятор» иногда используют термин «транслятор» как его синоним, что, правда, терминологически неправильно: либо в старой литературе, либо когда хотят подчеркнуть его способность переводить программу в машинный код (и наоборот, используют термин «компилятор» для подчёркивания способности собирать из многих файлов один).
18. Внутреннее представление целых чисел в ПК


19. Внутреннее представление вещественных чисел в ПК
20. Подпрограммы (общее, стандартные и пользовательские, глобальные и локальные переменные, передача параметров)






21. Отладка. Виды программных ошибок
22. Отладка. Автоматизированные средства (пошаговое выполнение, трассировка, выполнение до курсора, сброс программы)
23. Отладка. Автоматизированные средства (окно просмотра/изменения значений переменных, просмотр стека вызовов, точки останова)
24. Способы отладки программ. Примеры.
См. лекцию
25. Структура программы





26. Простые типы данных
См вопрос 18,19
+

27. Составные типы данных (структуры, массивы)
Массив – конечная последовательность данных одного типа. Массив –
объект сложного типа, каждый элемент которого определяется именем (ID) и
целочисленным значением индекса (номера), по которому к элементу массива
производится доступ. Рассмотрим одномерные массивы.
Внимание! Индексы массивов в языке С/С++ начинаются с 0.
В программе одномерный массив декларируется следующим образом:
тип ID массива [размер];
где размер – указывает количество элементов в массиве. Размер массива может
задаваться константой или константным выражением.
Примеры декларации массивов:
int a[5];
double b[4] = {1.5, 2.5, 3.75};
в целочисленном массиве а первый элемент а[0], второй – а[1], ..., пятый – а[4].
Для массива b, состоящего из действительных чисел, выполнена инициализация,
причем элементы массива получат следующие значения: b[0]=1.5, b[1]=2.5,
b[2]=3.75, b[3]=0.
В языке С/С++ не проверяется выход индекса за пределы массива.
Корректность использования индексов элементов массива должен
контролировать программист.
Примеры описания массивов:
const Nmax=10;
– задание максимального значения;
typedef double mas1[Nmax*2];
– описание типа одномерного массива;
int ss[10];
– массив из десяти целых чисел.
Элементы массивов могут использоваться в выражениях так же, как и
обычные переменные, например:
f = 2*a[3] + a[Ss[i] + 1]*3;
a[n] = 1 + sqrt(fabs(a[n–1]));


28. Структура простого следования. Понятие и смысл оператора присваивания. Приоритет выполнения операций


29. Организация консольного ввода/вывода


30. Операторы ветвления
Неполное ветвление: if (выражение) оператор;
Полное ветвление: if (выражение) оператор; else оператор;
Оператор переключатель:
switch (условие)
{
case константа: инструкции;
case константа: инструкции;
case константа: инструкции;
…
case константа: инструкции;
default: инструкции;
}
Каждая ветвь case может быть помечена одной или несколькими целочисленными константами или же константными выражениями. Выполняется та ветвь case, для которой константа (выражение) совпала с условием, указанным в начале переключателя switch. Если выяснилось, что ни одна из констант не подходит, то выполняется ветвь default. Если этой ветви нет, то ничего не выполняется.
Условие, следующее за ключевым словом switch в круглых скобках, может быть любым выражением, допустимыми в языке программирования С, значение которого должно быть целым.
Значение этого выражения является ключевым для выбора из нескольких вариантов. Тело оператора switch состоит из нескольких операторов, помеченных ключевым словом case с последующим константным выражением. Константное выражение может быть одно или их может быть несколько, кроме того, возможно использование целочисленных констант. Следует отметить, что использование целого константного выражения является существенным недостатком, присущим рассмотренному оператору.
Так как константное выражение вычисляется во время компиляции, оно не может содержать переменные или вызовы функций. Обычно в качестве константного выражения используются целые или символьные константы.
Все константные выражения в операторе switch должны быть уникальны. Ветвь default может отсутствовать. Ветви case и default могут располагаться в любом порядке.
Список операторов (инструкций) может быть пустым, либо содержать один или более операторов. Причем в операторе switch не требуется заключать последовательность операторов в фигурные скобки.
Отметим также, что в операторе switch можно использовать свои локальные переменные, объявления которых находятся перед первым ключевым словом case, однако в объявлениях не должна использоваться инициализация.
Схема выполнения оператора switch следующая:
- вычисляется выражение в круглых скобках;
- вычисленные значения последовательно сравниваются с константными выражениями, следующими за ключевыми словами case;
- если одно из константных выражений совпадает со значением выражения, то управление передается на оператор, помеченный соответствующим ключевым словом case;
- если ни одно из константных выражений не равно выражению, то управление передается на оператор, помеченный ключевым словом default, а в случае его отсутствия управление передается на следующий после switch оператор.
В конце каждой ветви достаточно часто ставится инструкция break. Это связано с тем, что после выполнения одной ветви программа проверяет возможность выполнения остальных "ниже" находящихся ветвей. Инструкция break вызывает немедленный выход из переключателя switch.
Для того, чтобы выполнить одни и те же действия для различных значений выражения, можно пометить один и тот же оператор несколькими ключевыми словами case.
31. Операторы циклов (с постусловием, с предусловием, итерационные и неитерационные, вложенные циклы). Операторы Break и Continue.
7. Структуры циклов
Цикл - это конструкция языка программирования, которая используется для выполнения каких-либо действий определенное количество раз.
Любой цикл состоит из следующих элементов:
Точки входа
Тела цикла, которое содержит операторы, выполняемые за один проход
Точки выхода
Условного выражения, определяющего момент окончания цикла
Дополнительно используемых операторов break и continue
7.1. Цикл с параметром (счетчиком, с управляющей переменной)
Вариант циклического вычислительного процесса, характерные особенности которого состоят в том, что:
число повторений цикла известно к началу его выполнения;
управление циклом осуществляется с помощью переменной порядкового типа, которая в этом циклическом процессе принимает последовательные значения от заданного начального до заданного конечного значений.
Для компактного задания подобного рода вычислительных процессов и служит оператор цикла с параметром.
7.1.2. На С++
Синтаксис цикла for таков:
for (начальное значение; условие выполнения; приращение)
{
Операторы;
}
В скобках после ключевого слова for находятся три выражения:
Инициализирующее. Оно предназначено для инициализации счётчика цикла.
Условие проверки цикла. Здесь, как правило, находится операция отношения. Если она возвращает единицу, то выполняется тело цикла, если возвращает ноль, то выполняется первый оператор стоящий за закрывающей фигурной скобкой.
Выражение инкрементирования (декрментирования) счётчика цикла. В этом выражении мы можем изменить значение счётчика. Можно использовать инкрементное выражение с любым параметром инкремента, например:
For (int і = 0; і <= GetNumberOfElements(); і += 2) {...}
for(int i = 0; i < 100; i += 10) {...}
Как работает цикл:
Инициализация счётчика
Проверка счётчика
Выполнение тела цикла
Инкремент (декремент) счётчика
Проверка счётчика
Выполнение тела цикла
И так, до тех пор, пока условное выражение не вернёт ноль.
В качестве условного выражения допустимо любое выражение С++, результатом которого может быть true. Ниже приведены примеры правильной записи условных выражений:
For (int і = 0; і < 100; i++) {...}
For (int і = 1; і == numberOfElements; i++) {...}
Любой из трех параметров цикла for может быть опущен.
Если опустить первый и третий операторы, то цикл for будет подобен циклу while, рассматриваемому далее.
Пример:
int cycle = 0; // объявляем переменную cycle типа int
for( ; cycle < 5; ) // опускаем 1-й и 3-й параметр
{
cycle++; // увеличиваем значение переменной на 1
cout << "Yes!"; // выводим на экран слово Yes!
}
cout << "\nCycle: << cycle << ".\n";// после цикла выводим значение переменной
В результате выполнения программы на консоль будет выведен текст
Yes!Yes!Yes!Yes!Yes!
Cycle:5.
Если опустить все три параметра, организуем бесконечный цикл.
for(;;)
{
printf("A"); // печатаем букву A
}
7.2. Итерационные циклы
Итерационные циклы отличаются от циклов с параметром тем, что в них заранее неизвестно число повторений.
Пусть мы отправляемся за грибами и возвращаемся домой, когда корзина наполнится. Все грибники делятся на 2 категории:
Смотрят, есть ли место в корзине, а уже потом срывают грибы, если их можно поместить в корзину. (Правда, в жизни таких грибников встречать не приходилось)
Сначала срывают грибы, а уже потом думают, как их положить в корзину.
Отсюда получаются два варианта реализации итерационных циклов: с предусловием и с постусловием.
В цикле с предусловием сначала проверяется условие, а потом делается шаг. Грибник придет с полной или почти полной корзиной. В цикле с постусловием – сначала шаг, а потом проверка. Как всякий нормальный грибник, этот принесет полную или слегка переполненную корзину.
Какой алгоритм выбрать зависит от конкретной задачи.
Нужно проанализировать событие, которое ожидается. Если оно может случиться до первого шага, то нужен цикл с предусловием. А если событие не может случиться до первого шага, то нужен цикл с постусловием.
Заметим, что оператор цикла с постусловием является более общим, чем оператор цикла с параметром — любой циклический процесс, задаваемый с помощью цикла с параметром можно представить в виде цикла с постусловием. Обратное утверждение неверно.
Оператор цикла с предусловием можно считать наиболее универсальным – с использованием таких операторов можно задать и циклические процессы, определяемые операторами цикла с параметром и постусловием.