

- •Matrix computations on systems equipped with GPUs
- •Introduction
- •The evolution of hardware for High Performance Computing
- •The programmability issue on novel graphics architectures
- •About this document. Motivation and structure
- •Motivation and goals
- •Structure of the document
- •Description of the systems used in the experimental study
- •Performance metrics
- •Hardware description
- •Software description
- •The FLAME algorithmic notation
- •The architecture of modern graphics processors
- •The graphics pipeline
- •Programmable pipeline stages
- •The Nvidia G80 as an example of the CUDA architecture
- •The architecture of modern graphics processors
- •General architecture overview. Nvidia Tesla
- •Memory subsystem
- •The GPU as a part of a hybrid system
- •Arithmetic precision. Accuracy and performance
- •Present and future of GPU architectures
- •Conclusions and implications on GPU computing
- •BLAS on single-GPU architectures
- •BLAS: Basic Linear Algebra Subprograms
- •BLAS levels
- •Naming conventions
- •Storage schemes
- •BLAS on Graphics Processors: NVIDIA CUBLAS
- •Evaluation of the performance of NVIDIA CUBLAS
- •Improvements in the performance of Level-3 NVIDIA CUBLAS
- •gemm-based programming for the Level-3 BLAS
- •Systematic development and evaluation of algorithmic variants
- •Experimental results
- •Impact of the block size
- •Performance results for rectangular matrices
- •Performance results for double precision data
- •Padding
- •Conclusions
- •LAPACK-level routines on single-GPU architectures
- •LAPACK: Linear Algebra PACKage
- •LAPACK and BLAS
- •Naming conventions
- •Storage schemes and arguments
- •LAPACK routines and organization
- •Cholesky factorization
- •Scalar algorithm for the Cholesky factorization
- •Blocked algorithm for the Cholesky factorization
- •Computing the Cholesky factorization on the GPU
- •Basic implementations. Unblocked and blocked versions
- •Padding
- •Hybrid implementation
- •LU factorization
- •Scalar algorithm for the LU factorization
- •Blocked algorithm for the LU factorization
- •LU factorization with partial pivoting
- •Computing the LU factorization with partial pivoting on the GPU
- •Basic implementations. Unblocked and blocked versions
- •Padding and hybrid algorithm
- •Reduction to tridiagonal form on the graphics processor
- •The symmetric eigenvalue problem
- •Reduction to tridiagonal form. The LAPACK approach
- •Reduction to tridiagonal form. The SBR approach
- •Experimental Results
- •Conclusions
- •Matrix computations on multi-GPU systems
- •Linear algebra computation on multi-GPU systems
- •Programming model and runtime. Performance considerations
- •Programming model
- •Transfer management and spatial assignation
- •Experimental results
- •Impact of the block size
- •Number of data transfers
- •Performance and scalability
- •Impact of data distribution
- •Conclusions
- •Matrix computations on clusters of GPUs
- •Parallel computing memory architectures
- •Shared memory architectures
- •Distributed memory and hybrid architectures
- •Accelerated hybrid architectures
- •Parallel programming models. Message-passing and MPI
- •ScaLAPACK
- •PLAPACK
- •Elemental
- •Description of the PLAPACK infrastructure
- •Layered approach of PLAPACK
- •Usage of the PLAPACK infrastructure. Practical cases
- •Porting PLAPACK to clusters of GPUs
- •Experimental results
- •Conclusions
- •Conclusions
- •Conclusions and main contributions
- •Contributions for systems with one GPU
- •Contributions for clusters of GPUs
- •Related publications
- •Publications directly related with the thesis topics
- •Publications indirectly related with the thesis topics
- •Other publications
- •Open research lines
- •FLAME algorithms for the BLAS-3 routines

6.2. PARALLEL PROGRAMMING MODELS. MESSAGE-PASSING AND MPI
The poor scalability of multi-GPU systems, mainly due to the bottleneck of the PCIExpress bus as the number of accelerators in the system grows.
The technological improvement of modern inter-node networks (e.g., 10 Gigabit Ethernet and Infiniband). As of today, inter-node networks performance is in the same order of magnitude as current PCIExpress specification. In this sense, the PCIExpress bottleneck becomes a secondary player in the computations, not the main one.
The introduction of new independent memory spaces per node (one or more, depending on the use of one or more GPUs per node) introduces a new burden for the programmer. Whether the separated memory spaces must be visible for the library developer or not is ultimately decided by the design of the chosen software infrastructure. In this chapter, we demonstrate how a careful design can drive to a transparent port of existing distributed-memory codes to accelerated codes without major performance penalty in the framework of dense-linear algebra implementations.
6.2.Parallel programming models. Message-passing and MPI
Computational models are useful to give a conceptual and high-level view of the type of operations that are available for a program. They are mostly independent from the underlying architecture, and do not expose any specific syntax or implementation detail. Parallel computational models focus on programming parallel architectures. In principle, any of the parallel models can fit on any of the architectures mentioned in Section 6.1; however, the success and e ectiveness of the implementation will depend on the gap between the model definition and the target architecture.
A number of di erent parallel computational models have been proposed, namely:
Shared memory model: Each process accesses to a common shared address space using load and store operations. Synchronization mechanisms such as semaphores or locks must be used to coordinate access to memory locations manipulated concurrently by more than one process.
Threads model: The shared memory model can be applied to multi-threaded systems, in which a single process (or address space) has several program counters and execution stacks associated (threads). Threads are commonly associated with shared memory architectures. POSIX threads and OpenMP are the most common implementations of the threads computational model.
Message passing model: In this model, a set of processes use their own local memory during computation. Potentially, multiple processes can coexist in the same physical machine, or execute on di erent machines. In both cases, processes communicate by sending an receiving messages to transfer data in local memories. Data transfers usually require cooperative operations to be executed by each process involved in the communication. The MPI interface is the most extended implementation of the message passing model.
Hybrid models: In this model, two or more parallel programming models are combined. Currently, the most common example of a hybrid model combines the message passing model (MPI) with either the threads model (POSIX threads or OpenMP). The success of this hybrid model is directly related to the increasingly common hardware environment of clusters of SMP machines.
Distributed-memory architectures are the target of the work developed in this chapter. From the definition of the message passing model, it is the one that best fits to distributed-memory
169

CHAPTER 6. MATRIX COMPUTATIONS ON CLUSTERS OF GPUS
architectures. The success of the message-passing model is based on a number of advantages compared to other parallel computational models [74]:
Universality: The message passing model is valid for any system with separate processors that can communicate through an interconnection network. The performance or nature of the processors or the network is not taken into account by the model. Thus, virtually any modern supercomputer or cluster of workstations can fit in this characterization.
Performance: The adaptation of message passing to distributed-memory architectures makes it the perfect model for high performance computing. In these architectures, memory-bound applications can attain even super-linear speedups, and message passing is the common used programming paradigm. In addition, the control that the message passing model o ers to the programmers makes it suitable for high performance demanding implementations. On shared memory architectures, the use of message passing provides more control over data locality in the memory hierarchy than that o ered by other models such as the shared memory one.
Expressivity: Message-passing model is a complete model useful to fully express the essence of parallel algorithms.
Ease of debugging: With only one process accessing data for reading/writing, the debugging process in message-passing model is usually easier than in other models like, e.g., sharedmemory.
Historically, a number of message passing implementations have been available since the 1980s. In response to this heterogeneity in the message passing implementations, the MPI standard was introduced in 1994 [74] in its first version and in 1996 [125] in its second version. MPI has become the de facto standard for programming distributed-memory architectures. In addition, it is perfectly suitable for shared memory architectures where message passing is performed through memory copies.
The introduction of hybrid distributed-memory architectures with hardware accelerators (GPUs) per node, represents a new challenge from the software point of view. As an example, current dense linear algebra libraries for distributed-memory machines (ScaLAPACK, PLAPACK or Elemental, to name a few) are based on message-passing libraries like MPI or PVM. The introduction of new memory spaces bound to the new accelerators introduces the challenge of porting these libraries to novel architectures. If the goal is to abstract the programmer from the existence of hardware accelerators in the system, the problem is even harder to solve.
6.3.Dense linear algebra libraries for message-passing programming
In this section, we review three di erent alternatives for dense linear algebra computations on distributed-memory architectures. These libraries are illustrative of the past (and present) of the field (ScaLAPACK and PLAPACK), and the state-of-the-art in distributed-memory libraries (in the case of the Elemental framework).
6.3.1.ScaLAPACK
With the advent and popularization of distributed-memory machines, it seemed clear that LAPACK needed to be redesigned to adapt its contents. ScaLAPACK [49] was the response of the creators of LAPACK to port its functionality to distributed-memory machines. ScaLAPACK
170

6.3. DENSE LINEAR ALGEBRA LIBRARIES FOR MESSAGE-PASSING PROGRAMMING
is defined as a message-passing library for distributed-memory machines, o ering in-core and out- of-core computations for dense linear algebra implementations. It implements a subset of the functionality of the LAPACK library.
Motivation, goals and design decisions
During the early stages of LAPACK, target architectures for this project were vector and sharedmemory parallel computers. The ScaLAPACK library was initially thought as a continuation of LAPACK, focused on distributed-memory machines. To accomplish this target, ScaLAPACK delegates the communication layer to well-known message-passing communication libraries such as PVM [128] and MPI [125].
According to the ScaLAPACK User’s Guide [33], six main goals underlied the initial idea of ScaLAPACK:
E ciency, to run message-passing codes as fast as possible.
Scalability, to keep e ciency as the problem size as the number of processors grows.
Reliability, including error bounds.
Portability, across a wide variety of parallel machines.
Flexibility, so users can construct new routines from well-designed parts.
Ease of use, making the interfaces of LAPACK and ScaLAPACK as similar as possible.
Historically ScaLAPACK has been a library of success in part due to the accomplishment of many of these initial goals. For example, portability is guaranteed by the development and promotion of standards, especially for low-level computation and communication routines. The usage of BLAS and BLACS (Basic Linear Algebra Communication Subprograms) warrants the correct migration of the implementations through di erent architectures, provided there exist implementations of BLAS and BLACS for them. To ensure e ciency, the library relies on the performance of the underlying BLAS libraries, and scalability is accomplished with a optimal implementation of BLACS.
However, two of the initial goals of ScaLAPACK, flexibility and ease of use are arguable. The aim of the authors of ScaLAPACK was to create a library flexible enough to allow the scientific community to develop new routines or adapt existing ones to their necessities. As of today, 15 years after its introduction, and after becoming the most widely extended library for dense and banded linear algebra computations on distributed-memory machines, ScaLAPACK still lacks of many of the functionality present in LAPACK, mainly due to its di cult programming.
Software components and structure
Figure 6.3 describes the software hierarchy adopted in the design and implementation of ScaLAPACK. Elements labeled as local are invoked from a single process, and their arguments are stored only in the corresponding processor. Elements labeled as global are parallel and synchronous routines; their arguments (matrices and vectors) are distributed across more than one processor.
The BLAS and LAPACK components have already been described in Chapters 3 and 4, respectively. After observing the great benefits of BLAS on the performance, functionality and modularity of LAPACK, the ScaLAPACK designers aimed at building a parallel set of BLAS, called PBLAS
171
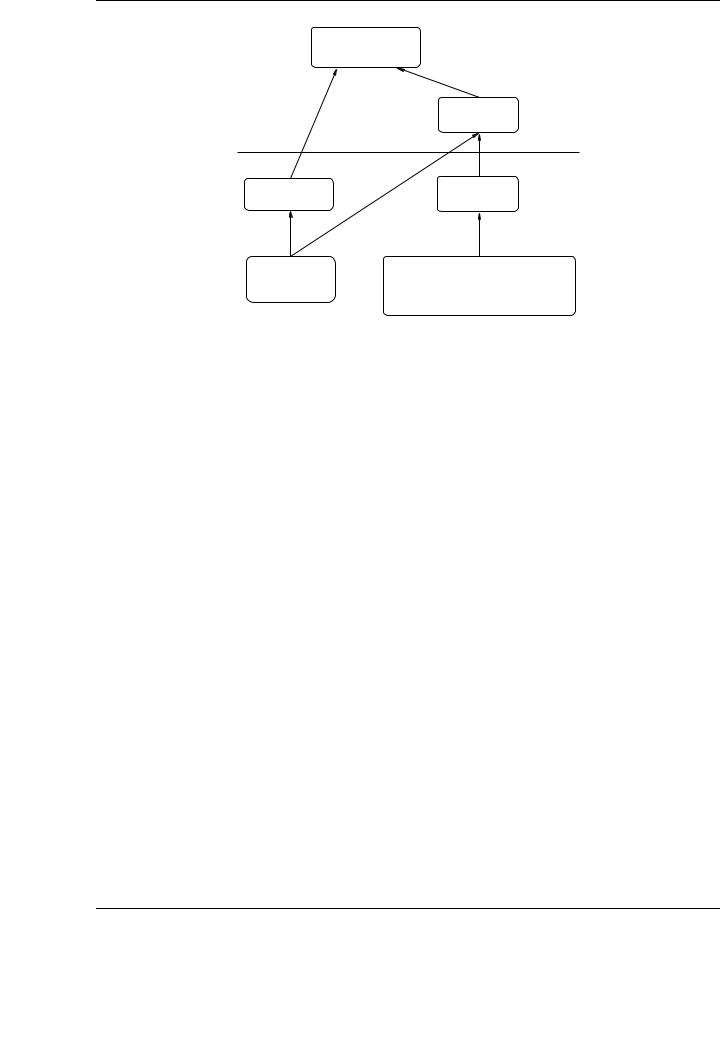
CHAPTER 6. MATRIX COMPUTATIONS ON CLUSTERS OF GPUS
ScaLAPACK
PBLAS
Global
Local
LAPACK |
BLACS |
BLAS |
Message Passing Primitives |
|
|
|
MPI, PVM, . . . |
Figure 6.3: ScaLAPACK software hierarchy.
(Parallel BLAS) [48, 112]. PBLAS implements some of the functionality of BLAS and keeps an analogous interface (as much as possible), using a message passing paradigm.
The BLACS (Basic Linear Algebra Communication Subprograms) [10, 58] are a set of messagepassing routines designed exclusively for linear algebra. Schematically, they implement a computational model in which processes, organized into a oneor two-dimensional grid, store pieces (blocks) of matrices and vectors. The main goal of BLACS was portability, and a specific design of their functions to address common linear algebra communication patterns. It implements synchronous send/receive routines to transfer matrices or sub-matrices between two processes, broadcast submatrices and perform reductions. It also implements the concept of context, that allows a given process to be a member of several disjoint process grids (alike MPI communicators).
Data distribution in ScaLAPACK
One design decision of ScaLAPACK is that all global data involved in the computations has to be conveniently distributed among processors before the invocation to the corresponding routine is performed. LAPACK uses block-oriented algorithms to maximize the ratio of floating-point operations per memory reference and increase data reuse. ScaLAPACK uses block-partitioned algorithms to reduce the frequency of data transfers between di erent processes, thus reducing the impact of network latency bound to each network transmission.
For in-core dense matrix computations, ScaLAPACK assumes that data is distributed following a two-dimensional block-cyclic [73] layout scheme. Although there exist a wide variety of data distribution schemes, ScaLAPACK chose the block-cyclic approach mainly because of its scalability [54], load balance and communication [78] properties.
Figure 6.4 illustrates a two-dimensional block-cyclic distribution layout. Here, we consider a parallel computer with P processes, arranged in a Pr × Pc = P rectangular array. Processes are indexed as (pr, pc), with 0 ≤ pr < Pr, and 0 ≤ pc < Pc. The distribution pattern of a matrix is defined by four parameters: the dimensions of the block (r, s), the number of processors in a column, Pc and the number of processors in a row, Pr. Note how, in the block-cyclic data distribution, blocks of consecutive data are distributed cyclically over the processes in the grid.
172