


CHAPTER 4. LAPACK-LEVEL ROUTINES ON SINGLE-GPU ARCHITECTURES
accelerate earlier, attaining near optimal performance results for relatively small matrices. This is di erent for the GPU implementations, in which high performance results are only reached for large matrix dimensions. In single precision, for example, the CPU attains higher performance rates for matrices up to n = 8,000; from this size on, the GPU performance becomes competitive, attaining better throughput as the matrix size is increased.
From a fine-grained perspective, a study of the implementations for di erent operand sizes reveals important di erences in the performance depending on the specific size of the matrix. For example, the Cholesky factorization operating on single-precision data (Figure 4.4) shows an important performance improvement when the matrix dimension is an integer multiple of 64; observe the results for n = 4,000, n = 8,000, n = 16,000, . . .. This behavior is inherited from that observed for the BLAS operations in NVIDIA CUBLAS, as was noted in Section 3.4.5, and is common for the Cholesky and, in general, other codes based on BLAS-3, using single and double precision.
To overcome the penalties observed in the basic blocked implementations, the following sections introduce refinements that can be applied simultaneously and/or progressively in order to improve both the performance of the factorization process and the accuracy of the solution of the linear system. These improvements include padding, a hybrid CPU-GPU implementation, and an iterative refinement procedure to improve the accuracy of the solution to the linear system.
4.3.2.Padding
Previous experiments have shown that Level 3 BLAS implementations of NVIDIA CUBLAS (specially the GEMM kernel) deliver much higher performance when operating on matrices with dimensions that are a multiple of 32 [20]. Similar conclusions have been extracted from the evaluation of Level-3 BLAS routines in Chapter 3. This situation is inherited by the Cholesky factorization implementations, as reported in previous sections.
Therefore, it is possible to improve the overall performance of the blocked Cholesky factorization process by applying the correct pad to the input matrix. Starting from a block size nb that is multiple of 32, we pad the n × n matrix A to compute the factorization
A¯ = |
0 Ik |
= |
0 Ik |
0 Ik |
|
T |
, |
||||||
|
A 0 |
|
L 0 |
L 0 |
|
|
where Ik denotes the identity matrix of order k, and k is the di erence between the matrix size n and the nearest integer multiple of nb larger than n (k = 0 if n is already a multiple of nb). By doing this, all BLAS-3 calls operate on sub-matrices of dimensions that are a multiple of 32, and the overall performance is improved. Moreover, there is no communication overhead associated with padding as only the matrix A and the resulting factor L are transferred between main memory and video memory. Although we incur in a computation overhead due to useless arithmetic operations which depends on the relation between n and 32, for moderate to large n, this overhead is negligible.
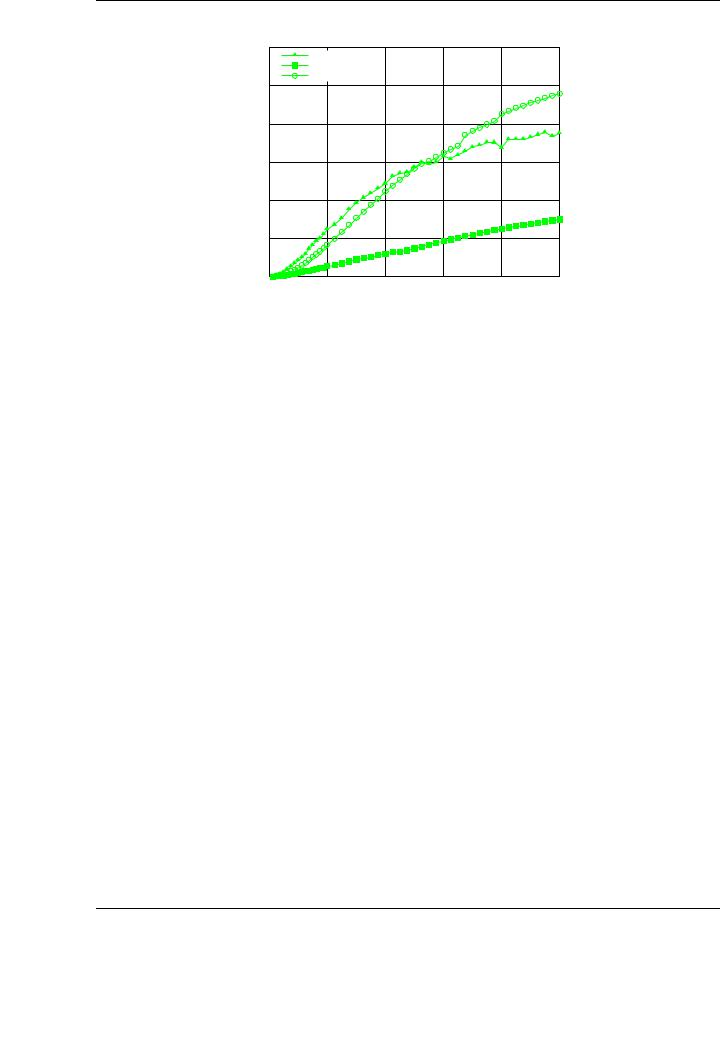
Figure 4.7 shows the performance attained for the blocked algorithmic variants for the Cholesky factorization when input matrices are padded accordingly with the directives given above. The rest of the experimental setup is the same as that used for the evaluation without padding. It is important to realiza that the attained performance rates are more homogeneous, without peaks when matrix sizes are multiples of 32. This improvement o ers a straightforward and cheap way of obtaining regular performance rates independently from the dimension of the problem.
88
4.3. COMPUTING THE CHOLESKY FACTORIZATION ON THE GPU
GFLOPS
Blocked Cholesky factorization with padding on PECO
300
GPU implementation (CUBLAS) - Variant 1 GPU implementation (CUBLAS) - Variant 2
GPU implementation (CUBLAS) - Variant 3
250
200
150
100 |
|
|
|
|
|
50 |
|
|
|
|
|
0 |
|
|
|
|
|
0 |
4000 |
8000 |
12000 |
16000 |
20000 |
Matrix size
Figure 4.7: Performance of the single-precision blocked algorithmic variants of the Cholesky factorization on the graphics processor using padding on PECO.
4.3.3.Hybrid implementation
The results attained with the basic implementations show a remarkable di erence in the performance of the factorizations for small matrices when they are carried out by the CPU or the GPU. In the first case, the performance is higher for small matrices, attaining close-to-peak performance already with the factorization of matrices of relatively small dimension. On the GPU side, the performance is low when the matrices to be decomposed are small, attaining higher performance results as the dimension is increased.
Hence, it is natural to propose a redesign of the basic blocked algorithm, in which each operation involved in the Cholesky factorization is performed in the most suitable processor. In this case, provided the optimal block size is relatively small (see Figure 4.5), the factorization of the diagonal blocks is a clear candidate to be o oaded to the CPU, as this architecture attains better e ciency in the factorization of small matrices.
Consider, e.g., any of the algorithmic variants for the Cholesky factorization shown in Figure 4.1. Each iteration of the algorithm implies the Cholesky factorization of the diagonal block A11, usually of a small dimension. In the basic implementation, this factorization is performed exclusively on the GPU using an unblocked version of the Cholesky factorization. The main overhead due to the decomposition of the diagonal block on the GPU is directly related to its small dimension.
To tackle this problem, a hybrid version of the blocked algorithm for the Cholesky factorization has been developed, delegating some of the calculations previously performed on the GPU to the CPU. This approach aims at exploiting the di erent abilities of each processor to deal with specific operations. The advantage of the CPU is twofold: due to the stream-oriented nature of the GPU, this device pays a high overhead for small problem dimensions. On the other hand, the CPU is not a ected by this and also delivers higher performance for some fine-grained arithmetic operations, specially the square root calculation, heavily used in the factorization of the diagonal block A11.
In the Cholesky factorization, the hybrid algorithm moves the diagonal block from GPU memory to main memory, factorizes this block on the CPU using the multi-threaded BLAS implementation, and transfers back the results to the GPU memory before the computation on the GPU continues.
89