

4. Неравномерность. Отклонения от нормы могут быть вызваны особыми
событиями, или могут отражать ≪беспорядочность≫ данных. Они про-
исходят случайно, и поэтому их нельзя предсказать.
Таким образом, данные по временному ряду могут быть представлены сле-
дующим математическим выражением:
где Yt —текущее значение во временном ряду в период времени t; Tt —трендо-
вый компонент в момент времени f, Ct —циклический компонент в момент вре-
мени t\ S( —сезонный компонент в момент времени Г; Rt —случайный компо-
нент в момент времени t.
В частном случае это уравнение может быть представлено в следующей
форме:
Yt=Tt+Cc+St+Rr
Также могут существовать другие формы. Наиболее часто уравнение запи-
сывается в виде множества:
Таким образом, изменения реальных значений (У) обусловливаются
четырьмя факторами. Задача аналитика состоит в ≪декомпозиции≫ временного
ряда Уна четыре составляющие. Теперь мы можем вернуться к задаче Фрэнка
Робинсона, которая заключается в прогнозировании продаж ≪Citronade≫ не
только на 2005 г., но и на каждый квартал. Вся процедура прогноза представлена
в табл. 5.5.
Сезонность. Процесс декомпозиции начинается с определения и удаления
сезонных факторов из временного ряда. Это делается для вычисления тренда.
Для изоляции сезонных изменений мы используем метод скользящих сред-
них.
Колонка 1: в этой колонке представлены последовательно пронумерован-
ные кварталы за 11 лет с 1994 по 2004 г.
Колонка 2: здесь приведены все данные за кварталы, которые были изна-
чально представлены в табл. 5.2.
Колонка 3: первым шагом в процессе устранения сезонных колебаний яв-
ляется вычисление среднего квартального значения для первого года (т. е. для
тарных четырех кварталов). Результат равняется 973,0; это число размещается
в этой колонке напротив числа 3. Следующее число получается путем смеще-
ния вниз на один квартал: выбрасывается 1-й квартал и добавляется 5-й квар-
тал. Вычисляется среднее значение 2- 5-го кварталов. Оно равняется 989,3. Это
число размещается в этой колонке напротив числа 4. Затем эта процедура про-
делывается с оставшимися кварталами. Из-за того что эти данные представля-
ют собой средние значения, отсутствует значение за первые два квартала и за
последний квартал.
Первое скользящее среднее было размещено напротив 3-го квартала. Так-
ж е его можно было расположить напротив 2-го квартала. На самом деле сред-
нее по четырем кварталам относится к ячейке между 2-м и 3-м кварталами. Эти
вычисления проделаны в 4-й колонке.
Колонка 4: высчитывается среднее значение двух чисел, стоящих в ко-
лонке 3; полученное значение размещается напротив 3-го квартала. Так как
973,0 В колонке 3 должно было быть расположено между 2-м и 3-м кварта-
лом, а 989,3 - между 3-м и 4-м кварталами, среднее этих значений (981,1)
помещается напротив 3-го квартала. В колонку 4 записываются все центра-
лизованные скользящие средние. В ходе этой процедуры теряются предпо-
следние значения.
Колонка 5: теперь мы получаем сезонные факторы. Они равняются отно-
шению реальных значений в колонке 2 к централизованным скользящим сред-
ним в колонке 4. Глядя на числа в колонке 5, можно заметить, что в каждом
четвертом квартале начиная с 3-го (т. е. в кварталах 3, 7, 11 и т. д.) значения
факторов превышают 1. Эти кварталы представляют собой летние месяцы, когда
потребление газированных напитков достигает своего максимума. Также за-
метно, что данные вторых календарных кварталов (т. е. кварталы 6,20, £4 и т. д.)
достаточно близки к 1, тогда как осенние и зимние кварталы значительно ниже
0,9.
Колонка 6: для получения квартального сезонного индекса мы должны най-
ти среднее из значений, полученных в колонке 5. Это сделано в табл. 5.6. Прин-
цип поквартальных изменении достаточно очевиден.1"
Четыре средних значения должны давать в сумме 4. Этого не происходит
из-за округлений. Теперь следует сделать незначительную корректировку. За-
тем результаты записываются в колонку 6 в табл. 5.5.
Колонка 7: при делении реальных данных, представленных в колонке 2, на
сезонные факторы из колонки 6 мы получаем набор чисел в колонке 7; эти зна-
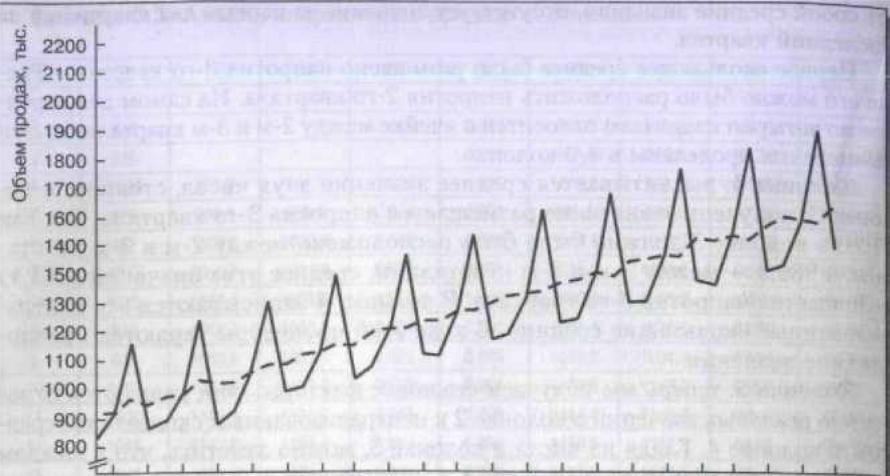
чения лишены сезонных колебаний. Реальные данные и данные после устране-
ния сезонного влияния отображены на рис. 5.6. После устранения сезонного
влияния кривая выглядит более гладкой.
Мы проделали первый этап процедуры декомпозиции:
2 4 6 8 10 12 14 16 1В 20 22 24 26 28 30 32 34 36 38 40 42 44
Р И С У Н О К
Данные о продажах
≪Citronade≫ после
устранения сезонных
колебаний
Новые данные не содержат сезонных изме-
нений. Следующий этап заключается в расчете
тренда.
Линия тренда. При расчете тренда исполь-
зуется метод наименьших квадратов. Зависимой переменной яв.кяются данные
из колонки 7 табл. 5.5. Независимой переменной является время. Кварталы
последовательно пронумерованы. Хотя начальное число значения не имеет,
будет логично начать с единицы. Таким образом, последовательные числа в ко-
лонке 1 табл. 5.5 представляют собой независимую переменную.
Форма уравнения зависит от формы числовых данных после устранения
сезонных колебаний. Поверхностное наблюдение этих данных указывает на то,
что наиболее подходящим будет использование прямой линии, но мы опробо-
вали три возможности:
•прямая линия: У= а + b(t);
•экспоненциальная функция:11 Y = аЫ\
•квадратичная функция:12 Y= а + Щ) + c(t)2.
Хотя все три вычисления дают приемлемые результаты, самый простой спо-
соб —прямая линия —дает лучшие статистические результаты. Коэффициент
смешанной корреляции (R2) = 0,996, а ^-статистика для независимой перемен-
ной = 103,6, что говорит о высокой значимости.
Экспоненциальное и квадратичное уравнения также демонстрируют боль-
шие значения смешанной корреляции, но их г-статистика значительно ниже
(а квадратичное значение в последнем уравнении оказывается статистически
незначимым),
Уравнение тренда для прямой линии выглядит следующим образом:
Y= 920,8 + 19,2882г.
Колонка 8: используя это уравнение, мы записываем в колонку 8 значение
тренда.
Колонка 9: затем путем деления значений колонки 7 назначения колонки 8
мы исключаем влияние тренда на наши данные.
(TxCxR)/T=CxR.
Таким образом, в колонке 9 остаются только циклические и случайные эле-
менты в форме процентов.
Циклические и случайные элементы. Мы могли бы закончить наш анализ
на данном этапе и перейти к прогнозу. Данные в колонке 9 изменяются доста-
точно нерегулярно в диапазоне около 5%. Часть этих изменений обусловлена
случайными факторами, которые невозможно предсказать, и поэтому их стоит
игнорировать. Однако эти данные могут содержать более длинный бизнес-цикл.
Для выделения цикла можно провести еще одно сглаживание с использовани-
ем скользящего среднего.
Колонка 10: мы можем установить предпочитаемую длину периода сколь-
зящего среднего только в каждом индивидуальном случае. В нашей иллюстрации
мы использовали три периода. Если скользящее среднее правильно устраняет
случайные изменения, оставшиеся в колонке 9, тогда колебания, представлен-
ные в колонке 10, являются циклическим индексом.
Когда индекс превышает 100%, это указывает на подъем экономики. Значе-
ния индекса ниже 100% говорят об обратном. Данные в колонке 10 меняются
очень слабо, с диапазоном менее 2%. Следовательно, нет необходимости в до-
полнительной корректировке. Однако, если индекс указывает на спад в эконо-
мике, что может повлиять на продажи прохладительных напитков, можно сде-
лать небольшую корректировку прогнозов. Такая корректировка может
основываться на текущих общих экономических прогнозах или на последних
опубликованных экономических показателях.
Прогнозирование с использованием метода
сглаживания
Прежде чем закончить раздел о проектировании, следует упомянуть еще один
метод простого прогнозирования. В этом методе для прогнозирования буду-
щего используются средние значения прошлых наблюдений. Если тот, кто де-
лает прогноз, считает, что будущее зависит от определенных усредненных зна-
чений за прошлые периоды, он может использовать два метода: простое
скользящее среднее или экспоненциальное сглаживание.
Метод сглаживания лучше всего подходит, когда данные не демонстриру-
ют устойчивого тренда, когда изменения редки и однонаправленны и когда ко-
лебания скорее случайны, чем сезонны или цикличны. Конечно, эти условия
ограничены. Однако если необходимо быстро сделать большое количество про-
гнозов и оценки включают в себя только один период в будущем, может быть
использован этот метод.
Скользящее среднее. Для прогнозирования одного периода в будущем ис-
пользуется среднее значение результатов за прошлый период. Это уравнение
выглядит просто:
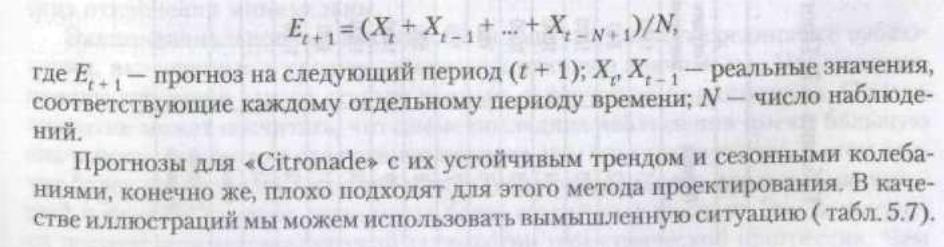

Заметьте: некоторые квадратичные ошибки кажутея неточными; это про-
изошло в результате того, что мы пренебрегли десятичными значениями.
Тот, кто осуществляет прогноз, должен решить, сколько наблюдений ис-
пользовать, применяя метод скользящего среднего. Чем больше наблюдений
используется при вычислении среднего, тем больше эффект сглаживания. Если
прошлые данные достаточно хаотичны, однако общий характер изменения ос-
тается неизменным, следует использовать большее количество наблюдений,
В табл. 5.7 были вычислены три скользящие средние —3, 4 и 5 месяцев. Итого-
вые значения показаны в колонках прогнозов. Например, прогноз 967 единиц
в 4-м периоде для скользящего среднего значения 3-го месяца получен следую-
щим образом:
£4 = (Х{ + Х2 + X3)/N= (1100 + 800 + 1000)/3 = 2900/3 = 967.
Три колонки прогнозов сильно отличаются между собой. Эти расхождения
графически показаны на рис. 5.7. Чем больше наблюдений включается в про-
гноз, тем более гладкой становится линия прогноза.
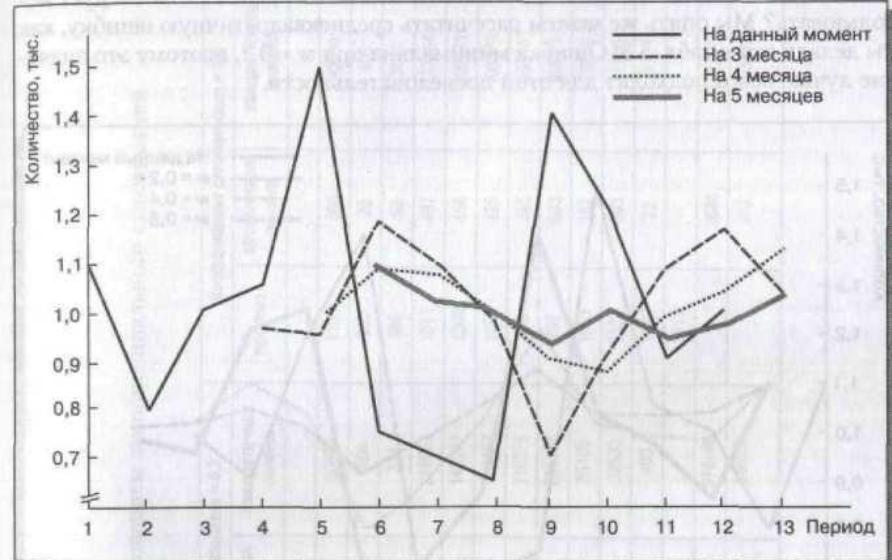
Р И С У Н О К S.7
Прогнозирование
с использованием
скользящего среднего
Какое скользящее среднее стоит использо-
вать? Можно использовать метод расчета сред-
ней ошибки и среднеквадратичной ошибки раз-
ницы между текущими данными и значениями
прогноза.13 Предпочтительнее будут последо-
вательности с наименьшими квадратичными
ошибками. В примере, приведенном в табл. 5.7, в скользящем среднем 5-го ме-
сяца отклонения минимальны.
Экспоненциальное скольжение. В методе скользящих средних все наблю-
дения, включенные в среднее, имеют одинаковую значимость. Наблюдения,
предшествующие самым старым данным, в расчет не принимаются. Однако
аналитик может посчитать, что самые последние наблюдения имеют ббльшую
значимость при оценке следующего периода, чем предшествующие. В этом слу-
чае более подходящим является метод экспоненциального скольжения, кото-
рый позволяет снижать значимость более старой информации. Это достигает-
ся посредством математической технологии геометрической прогрессии. Чем
старее данные, тем меньший вес они получают; сумма весов бесконечно боль-
шого числа наблюдений будет равняться 1. Все сложные формулы геометри-
ческих последовательностей можно упростить до следующего уравнения:
где w —удельный вес наблюдения в период времени t.
Таким образом, для того чтобы сделать прогноз на один период в будущем,
все, что необходимо, —это наблюдения за прошлый период и прогноз прошло-
го периода. Аналитик не нуждается в обширных данных за прошлые периоды,
которые необходимы для использования метода скользящего среднего. Глав-
ное решение, принимаемое аналитиком, —это выбор весового коэффициента.
Чем выше значение щ (т. е. чем ближе оно к 1), тем больше будет вес последних
наблюдений. Поэтому, когда последовательность значений достаточно измен-
чива, а значение w велико, эффект сглаживания может оказаться минималь-
ным. При меньшем значении w эффект сглаживания будет значительно более
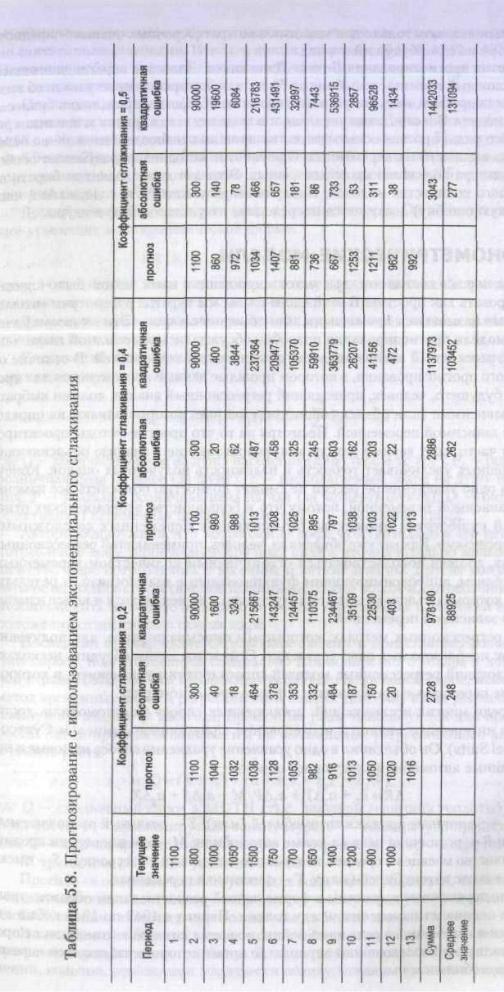
отчетливым. Результат можно увидеть в табл. 5.8 и на рис. 5.8; в данном приме-
ре значения w равны 0,2, 0,4 и 0Д! 4 Какие весовые коэффициенты следует ис-
пользовать? Мы опять же можем рассчитать среднеквадратичную ошибку, как
мы делали это в табл. 5.8. Ошибка минимальна при w = 0,2, поэтому это значе-
ние лучше всего подходит для этой последовательности.
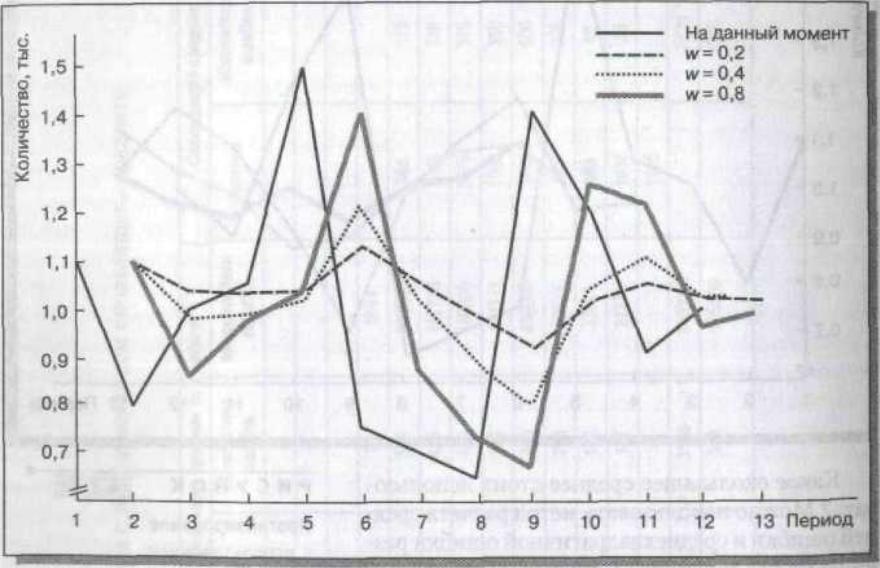
Р И С У Н О К
Прогнозирование
с использованием
экспоненциального
сглаживания
Заметьте: некоторые квадратичные ошибки
кажутся неточными; это произошло в резуль-
тате того, что мы пренебрегли десятичными
значениями.
Эти простые методы прогнозирования име-
ют свои достоинства и недостатки. Безуслов-
ным достоинством этих методов является их простота. Однако их область при-
менения ограничивается случаями, в которых наблюдается стабильность (т. е.
отсутствие тренда) со случайными колебаниями от периода к периоду. При
наличии тревда или повторяющихся отклонений более подходящим является
метод временного ряда. В любом случае, эти два метода, описанные нами, сле-
дует использовать только для максимально краткосрочных оценок —предпоч-
тительно на один будущий период.
Метод прогнозирования Бокса-Дженкинса. Здесь мы вкратце упоминаем
этот сложный и комплексный метод. Читатели, которые захотят узнать об этом
методе подробнее, могут обратиться к книгам по прогнозированию в бизнесе.
В модели Бокса—Дженкинса, как и в моделях сглаживания и анализа вре-
менного ряда, прогноз основывается на прошлых наблюдениях, а не на экзо-
генных независимых переменных. Однако этот метод не подразумевает особо-
го характера поведения прошлых данных. Этот метод позволяет выбирать из
большого количества моделей. Наилучший результат (т. е. содержащий наи-
меньшую ошибку) достигается посредством итерационной процедуры.
ЭКОНОМЕТРИЧЕСКИЕ МОДЕЛИ
До сих пор все количественные методы, описанные нами, можно было класси-
фицировать как простые. В этой части главы мы вкратце рассмотрим модели,
которые называются причинными, или объяснительными. Эти эконометриче-
ские модели прогнозирования подробно обсуждались ранее в этой главе.
Регрессионный анализ является объясняющей технологией. В отличие от
простого прогнозирования, в котором прошлые данные используются для про-
гноза будущего, человек, проводящий регрессионный анализ, должен выбрать
те независимые (или объясняющие) переменные, которые влияют на опреде-
ление зависимой переменной. Несмотря на то что простые методы проектиро-
вания часто дают верные результаты, использование в анализе объясняющих
переменных увеличивает точность и надежность полученных оценок. Конеч-
но, ни одно уравнение регрессии не сможет полностью объяснить все измене-
ние зависимой переменной, потому что в большинстве экономических отно-
шений существует множество объясняющих переменных со сложными
взаимосвязями. Как мы уже объясняли, человек, применяющий регрессионный
анализ, должен довольствоваться ограниченным количеством переменных,
уравнением, аппроксимирующим функциональные взаимосвязи, и результа-
тами, которые объясняют значительную долю изменения, хотя и не все измене-
ние, в зависимой переменной.
В регрессионных методах, которые мы описывали ранее, для получения
оценок использовалось одно уравнение. Сейчас мы хотим обсудить несколько
исследований регрессионных моделей спроса с одним уравнением, в котором
многие переменные представлены в форме временного ряда.
Среди многих исследований, посвященных спросу на автомобили, доста-
точно интересным является исследование, проведенное Дэниелом Суитсом
(Daniel Suits). Он объединил в одно уравнение уравнения спроса на новые и по-
держанные автомобили следующим образом:
0 , а2АР/М + а ^ + а4ДХ,
где R —розничные продажи автомобилей (млн); Y —реальный располагаемый
доход; Р —розничная цена на новые автомобили; М —средние сроки кредита
(количество месяцев в среднем контракте с выплатами в рассрочку); S —имею
щийся запас автомобилей (млн); X —фиктивная переменная.
Все переменные выражены в форме первой разности; таким образом, ура≫"
нение оценивает изменения между годами. Период с 1942 по 1948 г. был ис
ключей из временнбго ряда из-за войны, во время которой автомобили не про
изводились, и послевоенного периода, во время которого наблюдался перекос
на автомобильном рынке.

где Q - ежедневный __________спрос в MDTH (тыс. декатерм (единица теплоты)); G -
темп роста; Т —прогнозируемая температура: Р - температура предыдущего
Дня; W—прогнозируемая скорость ветра; а - отрезок; bvb2,b3- коэффициенты.
R2 уравнения регрессии равняется 0,983.
Прогноз ≪в основном используется для того, чтобы убедиться, что заплани-
рованные поставки соответствуют прогнозируемому спросу на следующие пять
Дней≫. Компания получает прогноз погоды на 5 дней два раза в день.
В каждом исследовании численные коэффициенты (а И Ь) были получены
при помощи регрессионного анализа. Для прогноза с использованием этих урав-
нений, конечно, необходимо произвести оценку каждой переменной в указан-
ном периоде.15 Разные значения независимых переменных приводят к альте
нативным прогнозам.
Следует сделать одно предупреждение относительно использования р^грес
сионных уравнений при прогнозировании. Все параметры (коэффициенты}
в уравнении регрессии оцениваются с применением данных за прошлый перио
(при использовании как анализа временного ряда, так и перекрестного анали
за). Прогноз, основывающийся на таких оценках, будет справедлив, только есл
связь между зависимыми переменными и независимой переменной останетс
неизменной. Фактически регрессионное уравнение обосновано только в ппе-
делах данных, которые в нем используются. Когда мы выходим за пределы этих
рамок (т. е. осуществляем прогноз с независимыми переменными, выходящими
за прошлый диапазон), мы вступаем на опасную тропу. Тем не менее прогнози-
рование с использованием метода наименьших квадратов является широко ис-
пользуемым методом, который часто применяется вполне эффективно. Однако
аналитикам не следует забывать о его ограничениях.
Хотя многие проблемы, связанные с. прогнозами, можно решить, используя
регрессионные модели с одним уравнением, бывают ситуации, когда одного
уравнения недостаточно. В таких случаях экономисты обращаются к системам
уравнений. Примером таких моделей служит множество моделей прогноза ВВП
и его составляющих частей. Такие модели могут включать в себя сотни пере-
менных и уравнений.
Модель с одним уравнением может быть применена, когда зависимая пере-
менная может быть оценена с использованием независимых переменных, кото-
рые обусловливаются событиями, не включенными в уравнение. Но что про-
исходит, когда определяющие переменные обусловливаются другими
переменными, включенными в модель? Тогда одного уравнения становится не-
достаточно.
В системе уравнений переменные делятся на эндогенные и экзогенные. Эн-
догенные переменные сопоставимы с зависимой переменной модели с одним
уравнением; они обусловливаются моделью. Однако они тоже могут влиять на
другие эндогенные переменные, так что могут выступать в роли ≪независимых≫
переменных (т. е. стоять в правой части уравнения) в одном или нескольких
уравнениях. Экзогенные переменные расположены вне системы и не обуслов-
лены внутри нее ничем; они являются действительно независимыми перемен-
ными.
Ниже приведен пример предельно простой модели частного сектора эконо-
мики, состоящей из двух уравнений:
где С - потребление; У - национальный доход; / - инвестиции.
В данном примере Си У являются эндогенными переменными. Предпола-
гается (скорее нереалистично), что /является экзогенной переменной.
Другая простая модель, состоящая их нескольких уравнений, представляет
собой взаимосвязь показателей внутри фирмы:
•продажи = /(ВВП, цены);
•издержки =/( количество товара, пены на факторы производства);
•расходы =/(продажи, цены на факторы производства);
•цена на товар =/(издержки, расходы, прибыль);
•прибыль т продажи - издержки - расходы.
В этой системе уравнений 5 переменных являются эндогенными. Экзоген-
ными переменными являются ВВП, количество товара и цены на факторы про-
изводства. Эти уравнения даны только в форме функций. Конечно, необходи-
мо определить конкретный вид уравнений.
Затем подобные системы уравнений будут решаться, для того чтобы полу-
чить коэффициенты. Рассмотрение статистических методов, которые исполь-
зуются для получения численных значений, выходит за рамки этой книги.
МЕЖДУНАРОДНЫЙ АСПЕКТ:
ПРОГНОЗИРОВАНИЕ ВАЛЮТНЫХ КУРСОВ
В главе 2 мы обсуждали проблемы, с которыми сталкиваются транснациональ-
ные корпорации. Подобная корпорация должна прогнозировать продажи, рас-
ходы и денежные потоки для операций в различных странах. Результаты этих
транзакций, осуществляемых в стране, будут зависеть от валютных курсов за-
рубежной и национальной валюты. Компании часто делают инвестиции в за-
рубежные предприятия, от которых они ожидают получить денежные потоки.
Таким образом, транснациональные корпорации (ТНК) заинтересованы в про-
гнозировании валютных курсов как в краткосрочном, так и в долгосрочном
периоде.
Для прогнозирования будущей процентной ставки в относительно корот-
ких периодах используется метод форвардной ставки. Для того чтобы понять
это, следует дать определение двум типам валютных курсов: