

Xlabel(''), ylabel('Выходыa(I)'),grid
subplot(3,1,2)
plot(0:30,[[0 0]; W],'k') % Рис3.1,б
Xlabel(''), ylabel('Весавходовw(I)'),grid
subplot(3,1,3)
for i=1:30, E(i) = mse(e{i}); end
semilogy(1:30, E,'+k') % Рис. 3.1,в
Xlabel(' Циклы'), ylabel('Ошибка'),grid
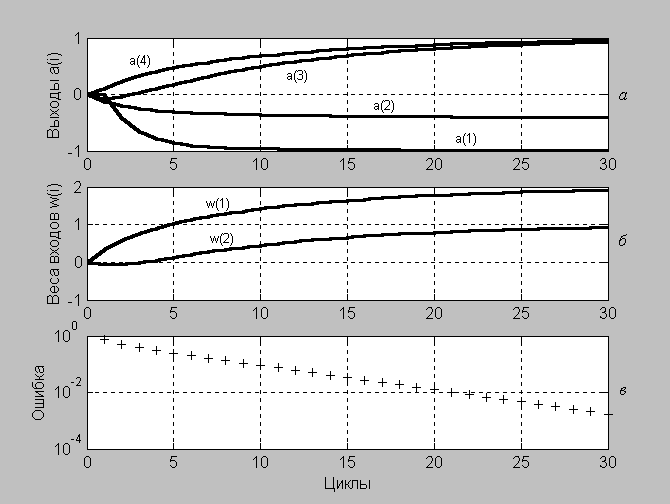
Рис. 3.1
Первый выход тот же, что и при нулевом значении параметра скорости настройки, так как до предъявления сети первого входа никаких модификаций не происходит. Второй выход отличается, так как параметры сети были модифицированы. Веса продолжают изменяться при подаче нового входа. Если сеть соответствует задаче, корректно заданы обучающие последовательности, начальные условия и параметр скорости настройки, то в конечном счете погрешность может быть сведена к нулю.
В этом можно убедиться, изучая процесс адаптации, показанный на рис. 3.1. Условие окончания адаптации определяется погрешностью приближения к целевому вектору; в данном случае мерой такой погрешности является среднеквадратичная ошибка mse(e{i}), которая должна быть меньше 0.015.
На рис. 3.1, апоказаны выходы нейронов в процессе адаптации сети, на рис. 3.1,б– коэффициенты восстанавливаемой зависимости, которые соответствуют элементам вектора весов входа, а на рис. 3.1,в– ошибка обучения. Как следует из анализа графиков, за 12 шагов получена ошибка обучения 1.489e–3.
Предлагаем читателю самостоятельно убедиться, что для исследуемой зависимости обучающие последовательности вида
P = {[–1; 1] [–1/2; 1/2] [1/2; –1/2] [1; –1]}; % Массив векторов входа
T = {–1 –1/2 1/2 1}; % Массив векторов цели
не являются представительными.
Групповой способ.Рассмотрим случай группового представления обучающей последовательности. В этом случае входы и целевой вектор формируются в виде массива формата double.
P = [–1 –1/3 1/2 1/6; 1 1/4 0 2/3];
T = [–1 –5/12 1 1];
Используется та же модель статической сети с теми же требованиями к погрешности адаптации. При обращении к М-функции adapt по умолчанию вызываются функцииadaptwbиlearnwh; последняя выполняет настройку параметров сети на основе алгоритма WH, реализующего правило Уидроу – Хоффа (Widrow – Hoff).
Основной цикл адаптации сети с заданной погрешностью выглядит следующим образом:
% Групповой способ адаптации сети с входами P и целями T
net3 = newlin([–1 1;–1 1],1, 0, 0.2);
net3.IW{1} = [0 0]; % Присваивание начальных весов
net3.b{1} = 0; % Присваивание начального смещения
net3.inputWeights{1,1}.learnParam.lr = 0.2;
P = [–1 –1/3 1/2 1/6; 1 1/4 0 2/3];
T = [–1 –5/12 1 1];
EE = 10; i=1;
while EE > 0.0017176
[net3,a{i},e{i},pf] = adapt(net3,P,T);
W(i,:) = net3.IW{1,1};
EE = mse(e{i});
ee(i)= EE;
i = i+1;
end
Результатом адаптации при заданной погрешности являются следующие значения коэффициентов линейной зависимости, значений выходов нейронной сети, приближающихся к значениям желаемого выхода, а также среднеквадратичная погрешность адаптации:
W(63,:)
ans = 1.9114 0.84766
cell2mat(a(63))
ans = –1.003 –0.36242 1.0172 0.94256
EE = mse(e{63})
EE = 0.0016368
mse(e{1})
ans = 0.7934
Процедура адаптации выходов и параметров нейронной сети иллюстрируется рис. 3.2.
subplot(3,1,1)
plot(0:63,[zeros(1,4); cell2mat(a')],'k') % Рис.3.2,a