

6.3. Многомерные группировки
Мы убедились, как трудно выбрать какой-то один признак в качестве основы группировки. Еще труднее проводить группировку по нескольким признакам. Комбинация двух признаков позволяет сохранить обозримость таблицы, но комбинация трех или четырех признаков дает совершенно неудовлетворительный результат: ведь даже при выделении трех категорий по каждому из группировочных признаков мы получим 9 или 27 подгрупп. Равномерность распределения единиц по группам в принципе невозможна. Вот и получаются группы, в которые входят 1—2 наблюдения. Сохранить сложность описания групп и вместе с тем преодолеть недостатки комбинационной группировки позволяют методы многомерных группировок. Часто их называют методами многомерной классификации.
Эти методы получили распространение благодаря использованию ПЭВМ и пакетов прикладных программ. Цель этих методов — классификация данных, иначе говоря, группиров-
191
--- конец страницы ---
----------стр. 192 ____________________
ка на основе множества признаков. Такие задачи широко распространены в науках о природе и обществе, в практической деятельности по управлению массовыми процессами. Например, выделение типов предприятий по финансовому положению, по экономической эффективности деятельности проводится на основе множества признаков; то же при выделении групп клиентов в банке.
Простейшим вариантом многомерной классификации является группировка на основе многомерных средних.
Многомерной средней называется средняя величина нескольких признаков для одной единицы совокупности. Поскольку нельзя рассчитать среднюю величину абсолютных значений разных признаков, выраженных в разных единицах измерения, то многомерная средняя вычисляется из относительных величин, как правило, — из отношений значений признаков для единицы совокупности к средним значениям этих признаков:

Таблица 6.9 Характеристики предприятий Всеволожского района Ленинградской области в 1999 г.

Эти признаки можно считать однородными, так как большая их величина положительно характеризует экономику предприятия. Предпочтительнее обобщать в многомерной средней признаки, либо все «положительные», либо все «отрицательные» (чем больше, тем хуже).
Многомерные средние, приведенные в последней графе табл. 6.9, обобщают четыре признака. При этом значимость признаков для оценки предприятия полагается одинаковой, что, конечно, спорно. Можно усложнить методику, приписав признакам на основе экспертной оценки разные веса, и вычислить взвешенные многомерные средние.
Судя по полученным значениям рь предприятия делятся на группы с многомерными средними ниже 100% (четыре предприятия), несколько выше 100% (два предприятия) и резко превышающие 100% (два предприятия).
При большом объеме совокупности для выделения групп на основе многомерной средней необходимо установить интервалы значений многомерной средней:
Затем следует провести группировку единиц: определить их количество в каждой группе и постараться указать, в чем состоят качественные различия между группами.
Более обоснованным методом многомерной классификации является кластерный анализ. Само название метода этимологически берет начало от слов «класс», «классификация». Английское слово «the cluster» имеет значения: группа, пучок, куст, т.е. объединение каких-то однородных явлений. В данном контексте оно близко к математическому понятию «множество», причем, как и множество, кластер может содержать только одно явление, но не может в отличие от множества быть пустым.
Каждая единица совокупности в кластерном анализе рассматривается как точка в заданном признаковом пространстве. Значение каждого из признаков у данной единицы служит ее координатой в этом пространстве по аналогии с координатами точки в нашем реальном трехмерном пространстве. Таким образом, признаковое пространство — это область варьирования всех признаков совокупности изучаемых явлений. Если мы уподобим это пространство обычному пространству, имеющему евклидову метрику, то тем самым получим возможность измерять «расстояния» между точками признакового пространства. Эти расстояния называют евклидовыми. Их вычисляют по тем же правилам, что и в обычной евклидовой геометрии. На плоскости, т.е. в двухмерном пространстве, расстояние между точками А я В равно корню квадратному из суммы квадратов разностей координат этих точек по оси абсцисс и по оси ординат — на основе теоремы Пифагора (рис. 6.1):

Совершенно очевидно, что нельзя суммировать квадраты отклонений одной точки от другой в абсолютных значениях
194
 195
195



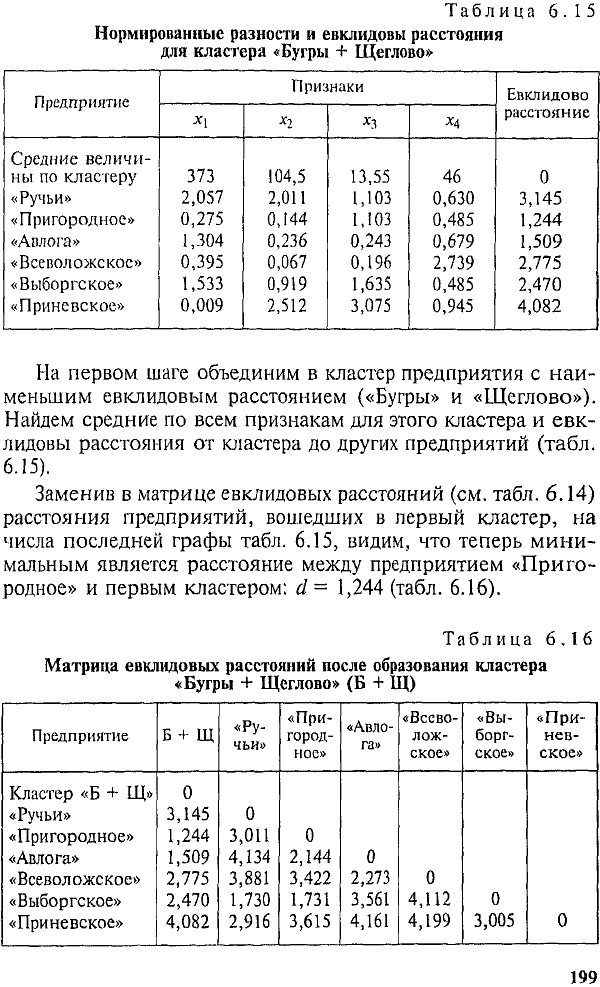
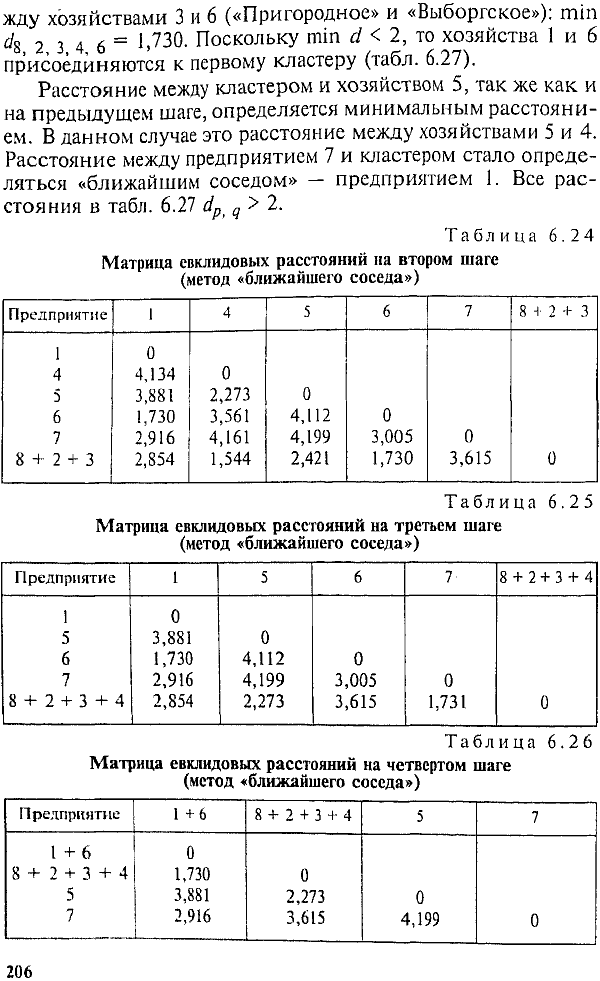
Следовательно, на втором шаге к первому кластеру присоединяется предприятие «Пригородное». Вычисляем средние величины, нормированные разности по каждому признаку и евклидовы расстояния от кластера, включающего три предприятия («Бугры», «Щеглово», «Пригородное»), до каждого из оставшихся предприятий. Результаты представлены в табл. 6.17.
Заменив евклидовы расстояния предприятий, вошедших в кластер, данными последней графы табл. 6.17, получим новую матрицу евклидовых расстояний (табл. 6.18).
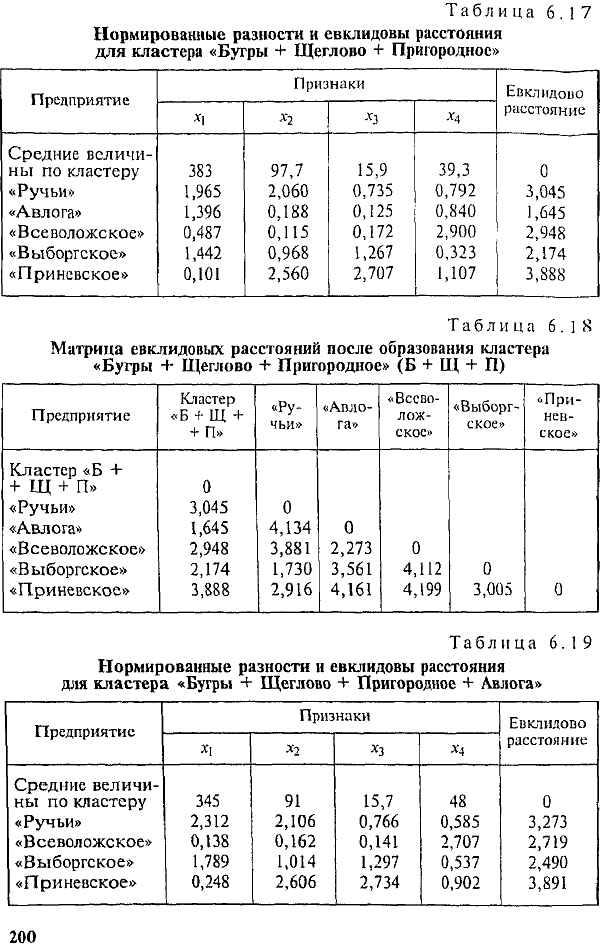
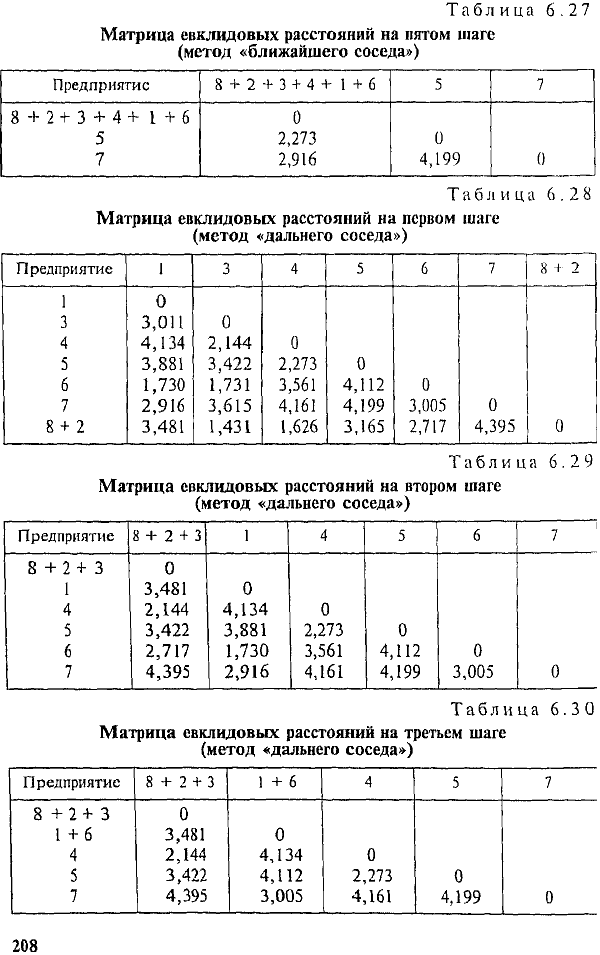
Минимальным является евклидово расстояние от кластера до предприятия «Авлога». На третьем шаге образуем кластер «Бугры + Щеглово + Пригородное + Авлога». Полученные средние величины для кластера, нормированные разности и евклидовы расстояния представлены в табл. 6.19 и 6.20.
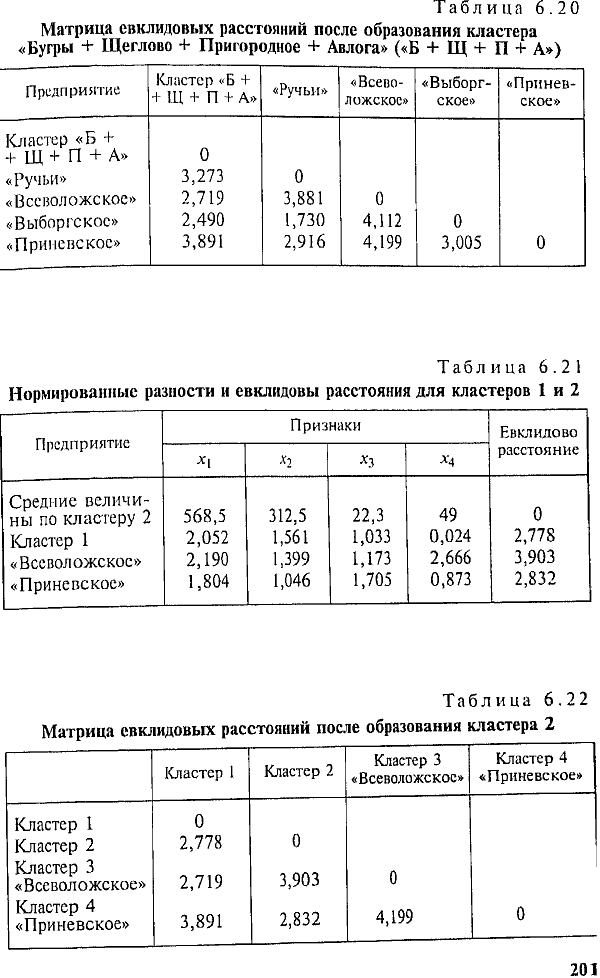
Минимальное евклидово расстояние между предприятиями «Ручьи» и «Выборгское» меньше двух, следовательно, эти предприятия объединяются в кластер 2 (табл. 6.21). Кластер «Б + Щ + П + А» будем называть кластером 1.
После четвертого шага получаем новую матрицу евклидовых расстояний (табл. 6.22).
Согласно табл. 6.22 все расстояния больше двух. Оставляем четыре типа предприятий: предприятия, вошедшие в кластер 1, кластер 2, кластер 3 («Всеволожское») и кластер 4 («Приневское»).
Сравнивая результат кластерного анализа с многомерными средними (см. табл. 6.9), видим, что состав кластера 1 точно отвечает тем хозяйствам, чьи многомерные средние ниже 100%. Также выделение в самостоятельный кластер предприятия «Приневское» соответствует его высшему значению многомерной средней. А вот объединение в кластер 2 предприятий «Ручьи» и «Выборгское» не соответствует многомерным средним, по которым к предприятию «Ручьи» было ближе предприятие «Всеволожское». В результате резкого отличия по признаку X4 предприятие «Всеволожское» выделилось в отдельный кластер 3.
Обобщая рассмотренную процедуру кластерного анализа, представим действия в виде определенной последовательности.
1. Вычисление средних величин для каждого из классификационных признаков х: в целом по совокупности.
202
 Опоеделение весов - весьма
сложная задача, выходящая за пределы
компетенции статистики. О том какие
признаки важнее при классификации тех
или иных объектов, могут судить не
статистики, а специалисты в соответствующей
отрасли. Поэтому одним из способов
определения весов признаков при
кластерном анализе являются оценки
экспертов. Опросив специалистов-экспертов
(не менее 6-10), статистик сможет определить
по их оценкам место (роль) каждого
группировоч-ного признака. Затем найти
средний «вес» признака. Можно просить
экспертов ранжировать признаки по
порядку значимости и определять «среднее
место», но оценка при этом будет очень
грубая: признак, поставленный на первое
место, будет вдвое важнее второго и в
двадцать или тридцать раз важнее
последнего. Для того чтобы различия
весов были не столь значительными,
можно просить экспертов распределить
общую сумму оценок (100 или 1000%) между
группировочными признаками в соответствии
с их значениями. Тогда каждому из
признаков будет приписана некоторая
доля этой общей суммы, можно двум-трем
признакам приписать одинаковые веса.
Но этот способ взвешивания требует от
экспертов большей точности и напряжения,
чем простое ранжирование признаков.
Опоеделение весов - весьма
сложная задача, выходящая за пределы
компетенции статистики. О том какие
признаки важнее при классификации тех
или иных объектов, могут судить не
статистики, а специалисты в соответствующей
отрасли. Поэтому одним из способов
определения весов признаков при
кластерном анализе являются оценки
экспертов. Опросив специалистов-экспертов
(не менее 6-10), статистик сможет определить
по их оценкам место (роль) каждого
группировоч-ного признака. Затем найти
средний «вес» признака. Можно просить
экспертов ранжировать признаки по
порядку значимости и определять «среднее
место», но оценка при этом будет очень
грубая: признак, поставленный на первое
место, будет вдвое важнее второго и в
двадцать или тридцать раз важнее
последнего. Для того чтобы различия
весов были не столь значительными,
можно просить экспертов распределить
общую сумму оценок (100 или 1000%) между
группировочными признаками в соответствии
с их значениями. Тогда каждому из
признаков будет приписана некоторая
доля этой общей суммы, можно двум-трем
признакам приписать одинаковые веса.
Но этот способ взвешивания требует от
экспертов большей точности и напряжения,
чем простое ранжирование признаков.
Субъективность экспертных оценок в какой-то мере можно компенсировать статистической обработкой. Например, по каждому признаку перед определением средней оценки его веса можно отбросить максимальную и минимальную оценки, если они существенно отличаются от оценок остальных экспертов. Можно вообще исключить того эксперта, чьи оценки в среднем отличаются от средних оценок признаков более чем, например, на 2а. Однако эти статистические коррективы небезупречны и допустимы при значительном числе экспертов для того, чтобы их средние оценки были надежны.
Существует и другая возможность оценки роли группиро-вочных признаков, их значимости для классификации: на основе стандартизованных коэффициентов регрессии или коэффициентов раздельной детерминации (гл. 9).
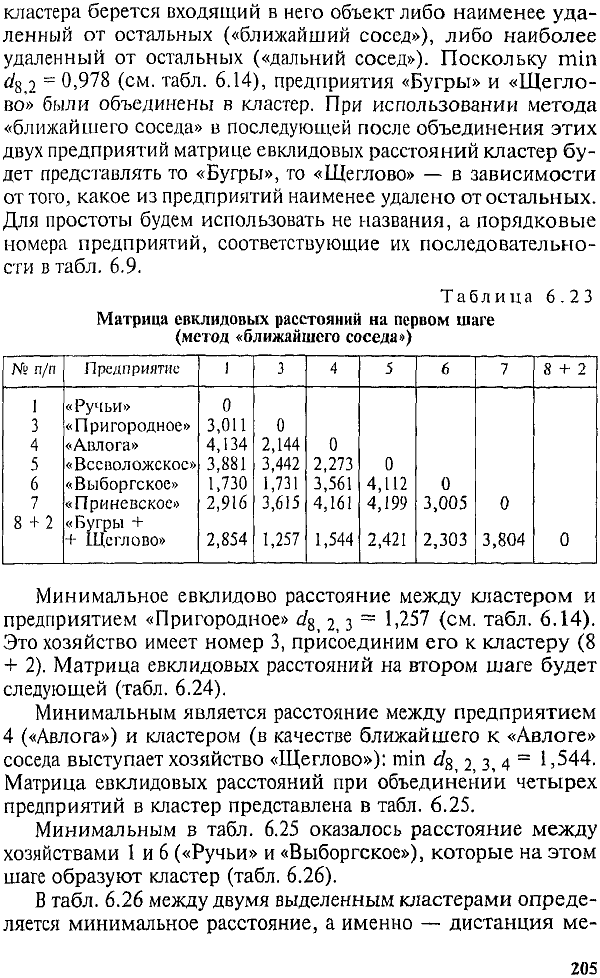
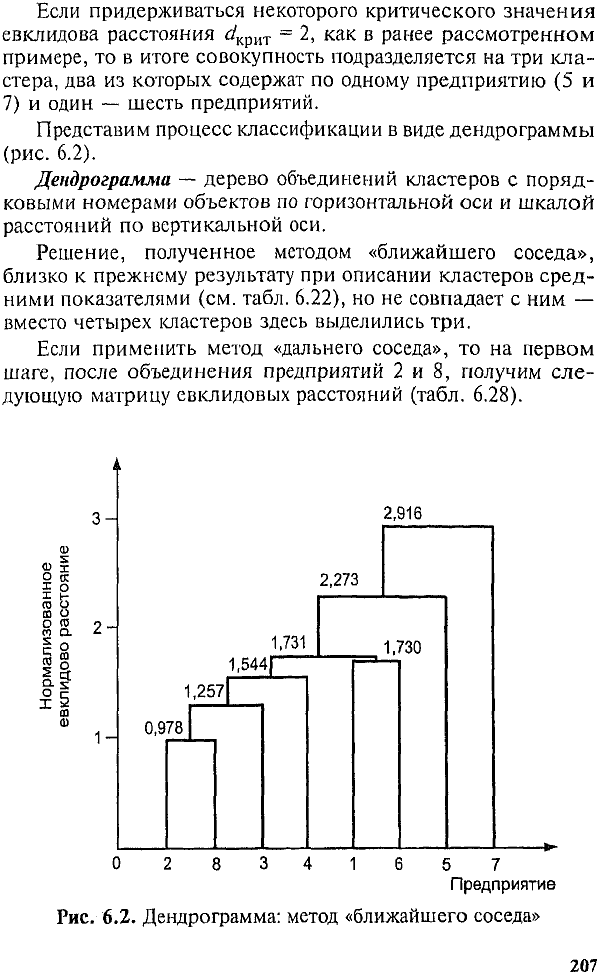
Рассмотренный алгоритм иерархической классификации можно модифицировать, используя метод «.ближайшего» или «дальнего соседа» (табл. 6.23). В этом случае в матрицу евклидовых расстояний вводятся расстояния, полученные не на основе средних величин по кластеру; в качестве представителя
204



РЕЗЮМЕ
Требование однородности данных выдвигается на всех этапах статистического анализа. Для получения однородных данных проводится группировка. При этом различия между единицами, отнесенными к одной группе, должны быть меньше, чем между единицами, отнесенными к разным группам.
Проведение группировки включает выбор группировочного признака (или признаков) и определение границ интервалов. Чаще всего группировки проводятся с равными интервалами, но при неравномерном изменении группировочного признака и его значительной вариации применяются группировки с равнонаполненными интервалами.
В зависимости от цели проведения различают следующие виды группировок: типологические, структурные, аналитические.
Типологическая группировка проводится с целью выделения социально-экономических типов.
Структурная группировка соответствует вариационному ряду.
Аналитическая группировка строится для изучения зависимости одного признака от другого. На ее основе измеряются сила и теснота связи, т.е. вычисляется эмпирическое корреляционное отношение. Для погашения влияния прочих факторов в аналитической группировке целесообразно рассчитывать стандартизованные групповые средние. Выводы о характере и интенсивности связи между признаками во многом зависят от выбранного числа групп.
При необходимости группировки по многим признакам для каждой единицы рассчитывают многомерную среднюю, а затем по ее значениям группируют данные.
Многомерные группировки часто называют многомерными классификациями. Они бывают иерархические, неиерархические, основанные на мерах различия или сходства. В качестве меры различия чаще всего используется евклидово расстояние. Среди иерархических классификаций выделяются метод средних, метод «ближайшего соседа», метод «дальнего соседа».
212
Исходя из структуры типа (ядро + слой) развиваются вероятностные классификации, так называемые классификации в размытых (нечетких) множествах.