

3. Методы генерации случайных величин и последовательностей
Датчики равномерно распределенных случайных чисел. При статистическом моделировании стохастических систем возникает необходимость в определении случайных событий, величин и последовательностей по заданным статистическим характеристикам. В основе их определения лежит использование последовательности чисел, равномерно распределенных в интервале (0,1). Программы ВС, формирующие такие последовательности, называют датчиками или генераторами случайных чисел.
Для получения последовательности равномерно распределенных случайных чисел с помощью ВС часто используется мультипликативный способ. Случайные числа получаются из рекуррентного соотношения
![]() (17)
(17)
где А, С — константы; М — достаточно большое положительное целое число.
При соответствующем
выборе констант и задании некоторого
начального значения
![]() эта формула позволяет получать
последовательность целых чисел,
равномерно распределенных в интервале
(0, М — 1). Последовательность имеет
период повторения, равный М.
Поэтому точнее называть числа
псевдослучайными. Случайные числа,
равномерно распределенные в интервале
(0,1), находятся масштабным преобразованием
полученных целых чисел.
эта формула позволяет получать
последовательность целых чисел,
равномерно распределенных в интервале
(0, М — 1). Последовательность имеет
период повторения, равный М.
Поэтому точнее называть числа
псевдослучайными. Случайные числа,
равномерно распределенные в интервале
(0,1), находятся масштабным преобразованием
полученных целых чисел.
Моделирование
случайных событий и дискретных величин.
Для моделирования случайного события
X, наступающего с вероятностью
Р, берется значение
![]() случайного числа, равномерно распределенного
на интервале (0,1), и сравнивается с Р.
Если
случайного числа, равномерно распределенного
на интервале (0,1), и сравнивается с Р.
Если
![]() Р,
то считается, что произошло событие X.
Р,
то считается, что произошло событие X.
Предположим, что дискретная случайная величина Y может принимать значения y1, …, yn вероятностями р1, ..., рп.. При этом
![]() .
.
Тогда берется значение случайного числа, распределенного равномерно на интервале (0, 1), и определяется такое k, принадлежащее совокупности (1, n), при котором удовлетворяется неравенство
![]()
Тогда случайная величина Y принимает значение уk..
Моделирование случайных непрерывных величин. Пусть непрерывная случайная величина Y имеет произвольный закон распределения. Предположим, что она задается эмпирической плотностью распределения f* (у) — гистограммой (рис. 5, а). Из гистограммы определяется эмпирическая функция распределения F* (у) — дискретная кумулятивная функция (рис. 5, б) для середин интервалов группирования случайной величины в пределах (ymin, y max).
Для определения одного конкретного значения случайной величины Y берется значение α случайного числа, равномерно распределенного на интервале (0, 1). Затем находится такое k, при котором
![]()
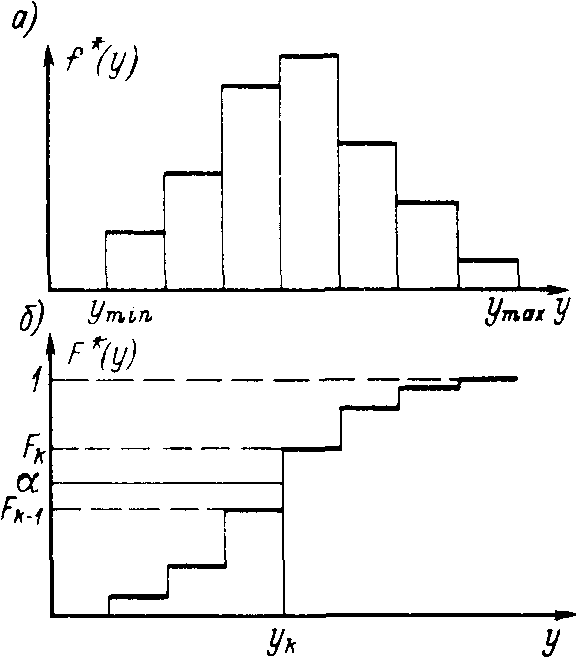

Рис. 5. Графики для определения значения случайного числа по дискретной и интегральной функции распределения
Тогда искомое случайное число равное (рис. 5, б). Это же правило применимо и при задании случайной непрерывной величины интегральной функцией распределения F (у), как показано на рис. 5, б. Оно вытекает из теоремы: если случайная величина Y имеет плотность распределения F (у), то ее распределение
![]() (18)
(18)
является равномерным на интервале (0, 1).
Для некоторых законов распределения (экспоненциальный, Эрланга) имеются простые аналитические зависимости у = Ф ( ). Например, пусть требуется получить конкретное значение случайного числа Y с экспоненциальным законом распределения. Подставим в формулу (18) а и плотность распределения:

После интегрирования получается
![]()
Разрешая это уравнение относительно уk,, имеем
![]()
Учитывая, что если
случайная величина
![]() подчинена равномерному закону
распределения в интервале (0, 1), то
случайная величина
подчинена равномерному закону
распределения в интервале (0, 1), то
случайная величина
![]() также имеет равномерный закон
распределения в интервале (0, 1),
последнее соотношение можно заменить
следующим:
также имеет равномерный закон
распределения в интервале (0, 1),
последнее соотношение можно заменить
следующим:
![]() (19)
(19)
Процедура определения конкретного значения случайного числа с заданным законом распределения называется случайным испытанием или «бросанием жребия».
Моделирование
случайных процессов сводится на практике
к определению последовательностей
случайных величин. Исходными данными
являются функции распределения,
определенные в требуемые моменты
времени, и последовательность случайных
чисел
![]() подчиняющаяся равномерному закону
распределения в интервале (0, 1).
Конкретные значения случайных процессов
в нужные моменты времени находят по
изложенным выше правилам.
подчиняющаяся равномерному закону
распределения в интервале (0, 1).
Конкретные значения случайных процессов
в нужные моменты времени находят по
изложенным выше правилам.
В большом числе публикаций, рассматриваются вопросы алгоритмизации, программирования и исследования качества датчиков случайных чисел.
В процессе статистического моделирования существует необходимость в частом обращении к датчикам случайных чисел. С их помощью формируются конкретные значения случайных параметров каждой заявки, параметров обслуживания заявки каждым устройством; определяются пути продвижения заявки по тому или иному маршруту при вероятностной дисциплине маршрутизации и т. д. Имитационное моделирование систем по принципу особых состояний проводится с постоянным использованием датчиков случайных чисел для формирования всех управляющих последовательностей.