

ORGANIZATsIYa_EVM
.pdfЛЕКЦИЯ N 14
оТема лекции:
Микроархитектура Pentium 4.
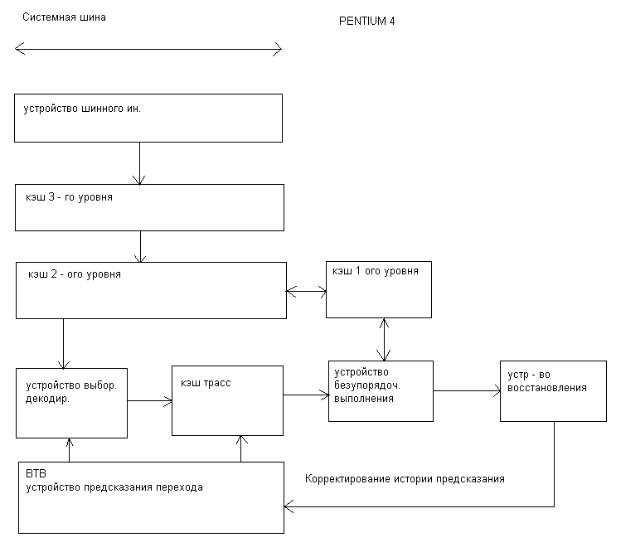
Если кратко характеризовать архитектуру Pentium 4 можно отметить следующее. Процессор Pentium 4 также как и Р6 состоит из 3х основных функциональных блоков:
1)устройство предварительной обработки инструкций в порядке их следования в программном коде. Результатом работы этого блока является последовательность микроопераций, поставляемые в исполнительном блоке.
2)блок выполнения микроопераций реализующий алгоритм безупорядоченного выполнения.
3)блок завершения.
Основное отличие от Р6, это наличие кэш трасс, представляющие память декодированных инструкций т.е. микрооперации, которые читаются из кэш трасс в буферах исполнительного устройства.
Как и в Р6 микрооперации формируются по коду выполнения программы, с той или иной лишь разницей, что эту работу блок предварительной выборки производит заранее и накапливает их в памяти. При этом работает блок предсказания перехода, который выбирает направление выполнения программы и как бы «сшивая» единую последовательность микроопераций, устраивая не только безусловные переходы, но и условные на основании данных в блоке предсказания.
Если при декодировании встречается «сложная» инструкция то как и в Р6 используется постоянная память ROM, в которой уже находиться последовательность микроопераций данной инструкции. При этом эти микрооперации не вставляются в кэш трасс и ставятся на место инструкции «заплатка» - указатель /адрес на место нахождения последовательности микроопераций в ROM.
В случае «промаха» в кэш трасс инструкции выбираются из более высокого уровня памяти. Декодируются таким образом поколения кэш трасс. Такая операция формирования сегмента кэш трасс занимает от 10,15 ти тактов до 30 ти т.е., «скрытый участок» конвейера достаточно сложная операция т.к. она проводится заранее и имеет большую «емкость» кэш трасс. Эти издержки вполне допустимы.
Сравнивая количество стадий конвейера устройства выборки/декодирования (без учета формирования очередной линейки кэш трасс) 8 по отношению к 7 стадиям в Р6. Кэш трасс представляет как бы память микропрограмм, формируемая динамически в процессе работы в процессоре и дает возможность многократно выполнять не только повторяющие инструкции но и целый сегмент программного кода.
Так на что же расходуются эти 8 стадий?
Первые 4 такта – извлечение последовательности из кэш трасс и предсказание перехода. Первый раз уже блок формирования адреса перехода выполняет свою функцию при формировании трассы но т.к. от этого момента до выполнения в процессоре проходит достаточно времени и блок предсказания переходов может иметь обновленные данные о ходе выполнения программы , то для «корреляции» в текущем моменте блок активизируется вторично. 1 такт уходит на буферизацию микроинструкции после чтения из кэш трасс и еще 1 такт чтобы выбрать «тройку» микроинструкций из очереди подготовить для нее ресурсы процессора. 2 такта уходит на замену логических регистров в микроинструкциях временными физическими из таблицы замены регистров.
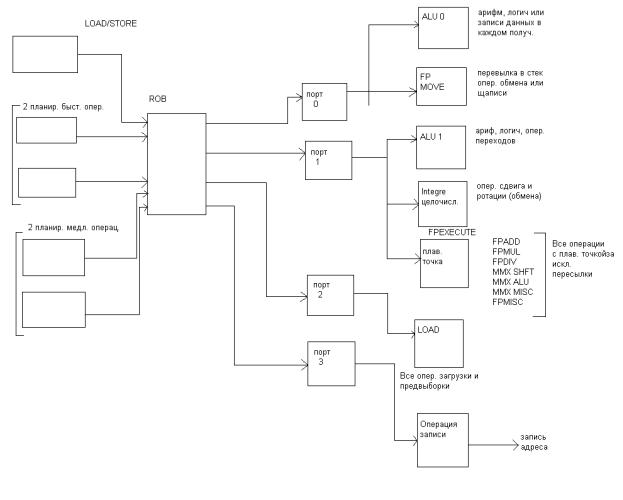
Функциональные исполнительные устройства в Pentium 4
После того как инструкция поступила в пул инструкций, процессор начинает распределять их по соответствующим исполнительным устройствам. Принцип такой же как и в Р6, но имеет свои особенности.
Во первых, если в Р6 выполнение всех микроинструкций на стадии резервирования управляется одним планировщиком, то в Pent 4 таких планировщиков 5, которые «разбирают» микроинструкцию в пуле. Все микрооперации к тому обращения к памяти формируются в отдельную очередь, которую контролирует отдельный планировщик (16 микроопераций).
Все другие формируются в другую очередь, которая управляется 2 мя «быстрыми» и 2 мя «медленными» планировщиками. Всеми простыми арифметически-логическими операциями управляют быстрые планировщики, которые распределяют по 2 микроинструкци за такт.
Второй особенность - микроинструкции отправляются выполняться на исполнительное устройство к тому моменту времени, когда должны поступить операнды из кэш. Если в Р6 схема обработки выглядит так:
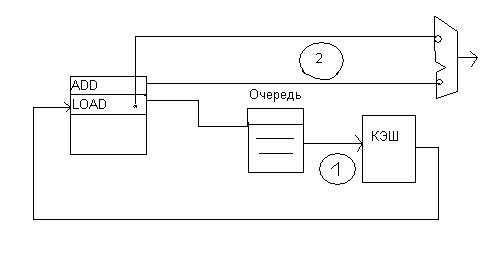
В Pentium 4 работают 2 независимых планировщика со своими микрооперациями, согласовывая (синхронизируя) между собой свои действия.
Например. планировщик распределяя микроинструкцию LOAD обращаясь за операндом в память, обязан сообщить всем остальным о постановке ее в очередь.. Планировщик, управляющий операцией сложения, в которой участвует этот операнд из памяти обязан поставить в очередь и отправить микрооперацию в исполнительное устройство с задержкой с таким расчетом, чтобы к появлению данных из кэш на шине микроинструкция была в исполнительном устройстве. Это теоретически. На самом деле чтобы избежать критической ситуации, когда данных не будет в кэш, конвейер исполнительного устройства имеет аппаратные средства повторить микроинструкцию, используя дублирующую копию микроинструкции, которая продвигалась параллельно по дублирующему псевдоконвейеру, не подвергаясь обработке в функциональном устройстве. Это делается„ с той целью чтобы в случае промаха возвратить микроинструкцию на основной конвейер для повтора.
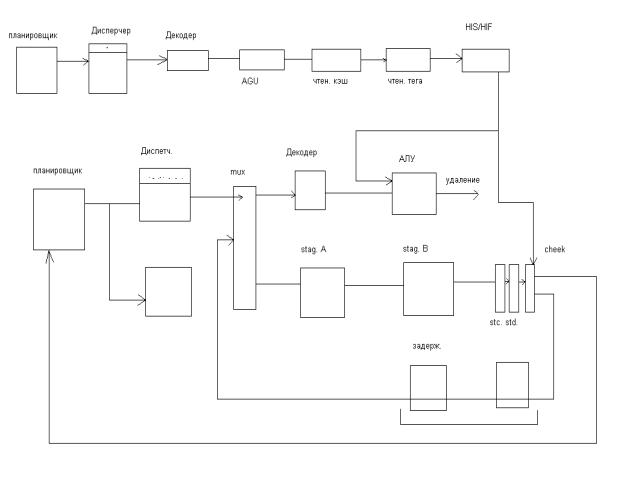
Механизм «Реплей»
Суть этого механизма заключается в том, что в исполнительном устройстве содержится 2 конвейера. Как следует из выше сказанного второй конвейер представляет циклическую память по которой продвигается копия микроинструкции в которой количество циклов равно количеству тактов необходимых для получения информации о наличии данных в кэш. Другая причина ввода петли повтора -это дать возможность планировщику посылать на конвейер и другие микроинструкции, которые имеют зависимости типа RAW от вышестоящей, посылая их на петлю повтора вслед за ней ,таким образом использовать максимально функциональное устройство и увеличить пропускную способность системы. Следует заметить что данная технология не является совершенной так как могут возникнуть ситуации когда на петлю попадает группа микроинструкций, которые имея зависимость между собой , зацикливание конвейера. А если учесть, что каждый планировщик имеет свою петлю повтора, то ситуации могут возникнуть еще критичней..
Как видно из схемы в случае «промаха» кэш микроинструкции «заворачивают» на запасной путь из 2 ого конвейера, чтобы через некоторую задержку попасть на основной конвейер. При этом блок контроля «сообщает» планировщику о ситуации, чтобы он оставил «дырку» для повтора выполнения операции.
.
Лекция 15
Краткая характеристика Power 4.
Начало направления RISC архитектуры IBM было положено с RISC System 6000 в 1990 Являющейся приемственником серии e Server p Series.
Начальная модель процессора функционировала в области частот от 20Мгц до 30Мгц. В 1993 году pow2 был разработан, работающ. В области частот от 55Мгц до 71,5Мгц и выполняет до 6 инструкций за цикл (такт).
Параллельно был анонсирован в этом же году pow601, явившийся как результат совместной разработки IBM, APL b Motorola, Texas.
Все вышеуказанные микропрограммы были 32х разр. Архитектуры. Начиная с RS64 анонсированного в 1997 году и pow3. В 1998 начинается эпоха 64х разрядных архитектур. Микропроцессоры класса RS64, RS64=2,3,4 през. Запись для коммерческих приложений. RS64 вначале работали на частоте 125Мгц. Более поздние разработки RS64 - 4 функционирующий на частоте 750Мгц.
Power - 3 был презентован (оптимизирован) для технологических приложений, работающих изначально на частоте 200Мгц. В дальнейшем модифицирован до 450Мгц. Power - 4 был разработан для использования как в коммерческих так и в технологических приложениях. Power – 4 был сконструирован в манере Power PC архитектуры .Изначально заложили для работы на частоте 1,1Ггц и 1,3Ггц.
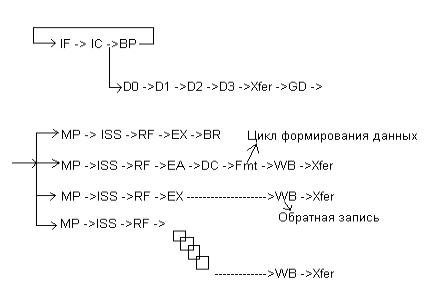
Стадии конвейера Power 4.
IF, IC, BP – циклы предназначенные для выборки инструкций и анализа предсказания перехода.
D0, D1, D2, D3 Xfer, GD – циклы, в течении которых инструкция декодируется и формируется в группы.
MP – цикл, в течении которого выявляются все зависимости, ресурсы, и группа диспетчеризуется в соответствующую очередь.
ISS – данный цикл предназначен для постановки в очередь для выполнения в функциональном устройстве, чтения соответствующего адреса регистра для выбора данных из регистрового файла и формирования адреса для записи результата .
EX – цикл выполнения.
WB – цикл записи в регистр результатов. В этом цикле инструкция заканчивает выполнение, но не завершенной она не моет завершиться по крайней мере еще 2 цикла. Xfer, CP – циклы предназначенные для завершения всех старших Групп или инструкций в той же группе.
Следует отметить, что инструкции, выбранные из кэш инструкций ждут D1 цикл, если они выбираются раньше, чем попадут в группу. Подобные инструкции могут ждать MP цикла, если ресурсы недоступны или ISS цикла или СР цикла для завершения.
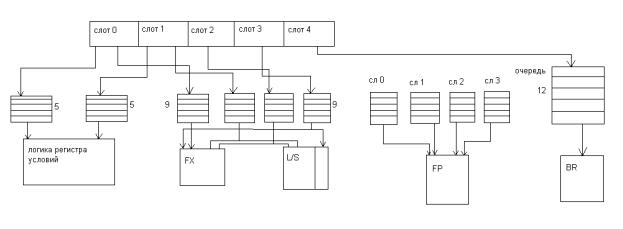
Особенностью архитектуры Power 4 является объединение инструкций в группы по 5 инструкций в каждой, которые поступают после формирования на этап диспетчеризации для дальнейшего исполнения в соответствующих исполнительных устройствах. Это делается с целью упрощения механизма отслеживания за выполнением инструкций при безупорядочном выполнении в исполнительных устройствах. Если в INTEL отслеживается каждая инструкция и удаляется с конвейера при завершении всех предыдущих, то в Power 4 удаляется группа целиком, т.е. 5 инструкций при условии, что все инструкции в группе завершены, и все предыдущие группы удаляются с конвейера. Power 4 имеет так называемую Глобальную таблицу завершения групп. Для увеличения числа инструкций находящихся на исполнении в устройствах Power 4 имеет Глобальную таблицу завершения инструкций на 20 входов. Т.е. одновременно отслеживаются 20 групп. Т.е. 20*5=100 инструкций, а при 2х ядерном до 200. Для каждой группы находящейся на этапе выполнения в таблице отводится строка, в которую заложен адрес 1 ой инструкции в группе. Таким образом, частью механизма завершения инструкций в программном порядке.
Индивидуальные группы следуют через систему то есть состояние процессора отслеживается на границе группы ,а не на границе инструкции внутри группы .Любая исключительная ситуация вызывает сохранение старшей группы, предшествующей возникновению причины прерывания.
Группа содержит до пяти внутренних инструкций. На стадии формирования группы инструкции в группе размещаются последовательно. Старшая инструкция в слот 0,следующая за ней в слот 1 и т.д. Слот 4 зарезервирован для инструкций перехода. Только одна группа инструкций распределяется за цикл и все инструкции в группе распределяются одновременно.
Индивидуальные инструкции из очередей в функциональных устройствах поступают на выполнение беcпорядочно. Результат фиксируется ,когда группа завершает выполнение условием которого является ситуация ,когда все старшие группы завершены и завершены все инструкции в группе.
Для осуществления корректного выполнения некоторым инструкциям запрещены спекулятивные операции то есть обгонять впереди идущие в программном коде. Примером таких инструкций являются инструкции чтения и записи в защищенные области памяти или такие как запись в регистры ,фиксирующие состояние процессора. Для организации безупоряочного выполнения большинство логических (архитектурных) регистров подвергаются преобразованию, но не все . Инструкции, в которых запрещено переименование, размещаются в конце группы
Внутренние инструкции в группе в большинстве своем являются системными командами ,однако, иногда системные команды разбиваются на несколько внутренних при формировании группы. Если системная команда разбивается на две внутренние, то обе они должны быть в одной группе. Если обе инструкции не могут быть размещены в одной группе, то группа заканчивается и новая группа формируется .Инструкция следуемая за разбиваемой может быть размещена в группе при наличии в ней места.
Следует отметить, что при формировании групп учитываются возможности инструкций из слотов в исполнительном устройстве. Так например, в слоте 4 могут располагаться инструкции перехода, если к моменту формирования группы таковой не окажется, то их место 4 ый слота формир. Инструкц. Н.О.П.
Так устройство, обрабатывающее содержимое регистра условий может принимать инструкции только из слота 0 или 1.
В Power 4 до 8 инструкций выбираются в каждом цикле из кэш инструкций в прямо. Логика предсказания переходов сканирует выбранные инструкции, просматривая до 2х переходов в каждом цикле. В зависимости от типа найденного перехода, различные механизмы предсказания помогают предсказывать направление и адрес перехода. Безусловные переходы не предсказываются. Pow 4 использует 3 таблицы историй переходов. Первая таблица, называемая локальным предсказанием подобна традиционной таблице В.Н.Т. Это 16.384 входов табл (2 в 14 ой степени) индексируем. Адреса инструкций перехода с 1 бит. Предсказания.
Вторая таблица, называемая глобальным предсказанием. Предсказывает направление перехода на действительную траекторию выполнения при каждом переходе. Траекторией прохождения в 11 бит регистре по одному биту на каждую группу инструкций выбранную из кэш для каждой из предыдущих 11 выбранных групп. Этот вектор называется вектором глобальной истории. Каждый бит в глобальной истории была им выбрана следующая группа из последовательного сектора кэш. Вектор глобальной истории собирает информацию о выполнении этих секторов. Т.е. если выбор направления выбранной инструкции и какая либо группа иносказ. Обрабатывается глобальный вектор немедленно модифицируется.
В.Т.В. содержит 3 таблицы:
1)таблица локальных переходов.
2)глобальная таблица
3)Селекторная таблица, осуществляющая фиксацию по каждому предсказанию.
Локальная таблица |
Глобальная таблица |
Селекторная таблица |
Power 5
1) Организация многопоточного режима.
Для этого на стадии до – после выборки инструкций из кэш они распределяются по 2м потокам отдельные буфера по 24 инструкции каждая. Таким образом, комплектуются группы инструкций из одного потока.
2)Регистровый фаил разделяется между двумя потоками. Т.е. все регистры файла доступны каждому из потоков.
3)Для реализации многопоточности размер и структура очередей были модифицированы. Таблица GCT для каждого входа (группы) сигнала содержит дополнительный бит, фиксирующий принадлежность группы к потоку.
Помимо этого каждый логический регистр при замене на физический стал содержать бит (индекс) принадлежности к потоку. А количество физических регистров было увеличено.
4)Модернизация подверглась очер. Для инструкции L/S. Дело в том, что области памяти для потоков разнесены в адресном пространстве. Поэтому очереди эти разделились поровну между потоками. А для того, чтобы исключить «пузыри» для этих инструкций организовали виртуальные очереди, в которых фиксируется инструкция при диспетчеризации, но без указания адресов памяти. Как только в реальной очереди освобождается место, инструкция переходит из виртуальной очереди в реальную, и для нее формируется адрес обращения к памяти.
Архитектурные особенности POWER 6
Главной особенностью архитектуры Power 6 от предыдущих Р4 и Р5 является вынос за пределы конвейера стадий формирования групп, поступающих на диспетчеризацию. Формирование групп в Power 6 осуществляется при переходе инструкций из кэш L2 в кэш инструкции. Таким образом, в кэш L1 поступают формированные группы. Кроме этого, если в Р4 и Р5 сохраняются зависимости внутри группы, то в Р6 инструкции в группе друг от друга независимы кроме инструкции с плавающей точкой.