

ORGANIZATsIYa_EVM
.pdfЛЕКЦИЯ N13
Тема лекции:
Микроархитектура процессоров INTEL класса
«Pentium»
Классическим примером процессоров этого класса является модель процессора Р6
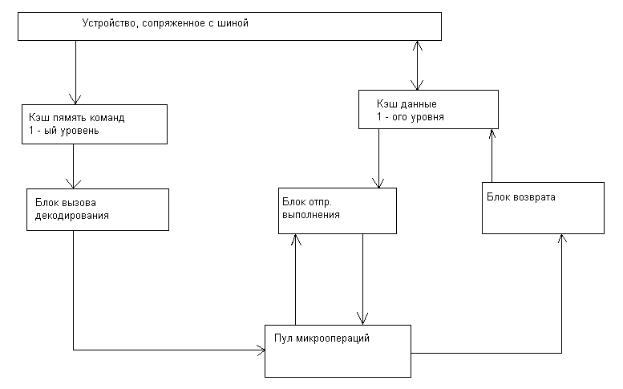
(Pentium Pro) ставший в свое время базовой для процессоров Pentium 2 и 3. Микроархитектура этого процессора содержит аппаратные средства, обеспечивающие конвейерную обработку команд и всех ситуаций, возникающих при этом, ранее нами рассмотренных аппаратными средствами.
Как видно из блок схемы процессор содержит 3 отдельных независимых функциональных блока, обеспечивающих 3х фазную обработку команд.
А) выборка Б) выполнение
В) завершение Эта классическая структура применялась и ранее в предыдущих поколениях различных
микроархитектур, с той лишь разницей, что для CISC моделей эти функциональные блоки были связаны воедино во время выполнения отдельной команды. Наличие кэш команд и данных 1 ого уровня является признаком модифицированной Гарвардской архитектуры, обеспечивающей совмещение выполнения выборки очередной команды c выполнением предыдущей. Эта технология была использована и ранее, к примеру, в наших отечественных моделях (ЕС 1045 и др.).
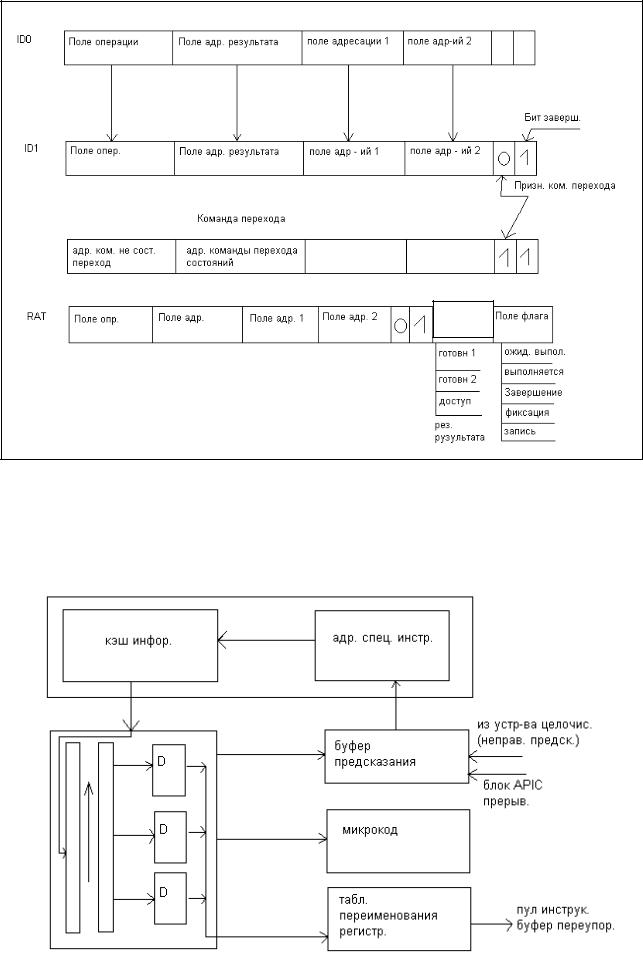
Микроархитектура блока декодирования имеет классические элементы, присущие любой системе, будь то жесткая логика или микропрограммное управление и предназначены для дешифрации команд и задания алгоритма обработки команд в процессоре. Но с другой стороны каждый блок имеет свои особенности, связанные со структурой и форматами команд, поступающих на обработку. Так в рассматриваемой архитектуре . команды имеют сложную структуру, которые разрабатывались без учета конвейерной обработки еще в предыдущих моделях (CISC).
Поэтому для сохранения преемственности программного обеспечения пришлось разрабатывать сложные декодеры, преобразующие СISC команды в набор микроопераций, представляющих по сути RISC команды. Для решения этой задачи пришлось разрабатывать достаточно сложные декодеры и организовывать многостадийный конвейер в рамках блока. Как мы уже говорили ранее, что формат команд, используемых в микропроцессорах класса х86 и в последующих разработках на базовой модели P6,
кроме поля кода операции имеет поле байта-модификатора в которых содержится вся информация о структуре команды, ее длине и способах адресации операндов, которая и
служит исходной информацией для разработки аппаратных средств декодеров..
По сути, о чем мы сейчас говорили это классическая функция блока декодирования по преобразованию команды в набор микроопераций. Тогда же в чем же особенность?
А особенность заключается в том, что в CISC архитектурах микрооперации, выполняющиеся последовательно одна за другой функционально связаны, как и команды в программном коде, адрес текущей определяет адрес последующей. В данном же решении микрооперации выходящие из декодера сохраняются в промежуточном буфере, становясь доступными группе исполняющих устройств, для которых они предназначены независимо от принадлежности команд в программном коде.
Возникает вопрос? А как же строгая последовательность программного кода. А для этого декодер на этапе декодирования связывает в цепочку микрооперации, принадлежащие одной команде, для того чтобы в процессе выполнение команды считать выполненной, когда все микрооперации в цепочке устанавливают флаг статуса «выполненных». А так как в случае беспорядочного выполнения возможно и внеочередное выполнение команды, команда удаляется из процессора только в том случае, если предыдущие команды выполнены.
Именно чтобы обеспечить эту функцию аппаратными средствами используется буфер микроопераций, в котором микрооперации записываются и удаляются в строгой последовательности согласно программному коду.
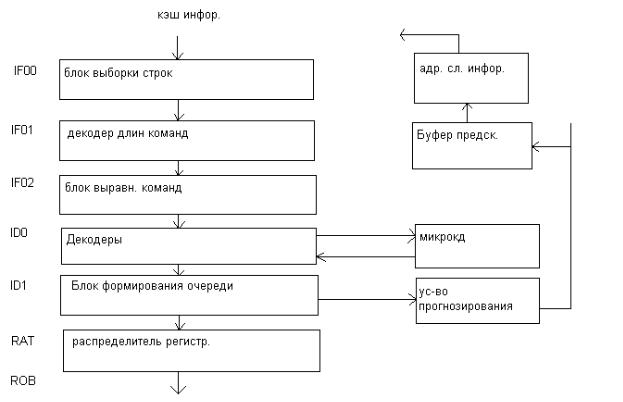
Как видно из блок схемы буфер микроопераций (пул микроопераций) является связывающим звеном между тремя основными блоками в процессоре. Он представляет адресуемую память, состоящую из 40 регистров. Он содержит микрооперации ожидающие выполнения, а также те, Которые уже выполнены, но не получили статус удаления из буфера «фиксация». Устройство диспетчера может выбирать для выполнения, как уже упомянуто выше, любую микрооперацию при готовности операндов и наличии свободного функционального устройства для их обработки Максимально 2 физических регистра со статусом завершения (удаления) могут быть прочитаны в каждом цикле. А теперь кратко о стадиях конвейера блока выборки декодирования. Наличие 3х стадий IF0, IF1, IF2 на этапе выборки объясняется следующими причинами.
1)выборка из кэш (32 байта кода программ.)
2)определение начала команд, их длина в области 32 байта (дешифрация кода команды и байта модификатора)
3)этап выравнивания. Т.к. декодеры работают с жестко распределенными полями в формате команды.
Команда, поступающая из декодирования должна быть выровнена на начало границы ввиду того, что в границах 32х байта считанных их кэш может начинаться не обязательно с 0 – ого байта.
Этап декодирования включает 2 стадии: ID0, ID1.
Первая собственно предназначена для формирования форматов микроопераций. Вторая для выстраивания очереди микроопераций.
Блок формирования очереди работает следующим образом:
Получив микрооперацию от декодера, он контролирует прием бита «завершения» из декодера в каждой следующей микрооперации и при получении его устанавливать признак конца цепочки, таким образом, связывая все микрооперации относящиеся к одной команде.
На этой же стадии конвейера получая от декодера признак команды, в случае обнаружения команды перехода формируется адрес следующей команды
с учетом, что переход назад более вероятен, чем вперед, на случай если блок предсказания не имеет другой информации о направлении перехода.
Блок декодирования имеет в своем составе 3 декодера, 2 предназначены для декодирования «простых» команд и один «сложный», декодирующий как простые, так и сложные команды. При работе декодеров имеется своя специфика. Если «сложный» декодер захватывает сложную команду, за которой следует «простые» две команды, то работают все декодера. Если же идет простых 3 команды, то 3 декодера работают одновременно и выдают в одном такте 3 микрооперации.
4 – 1 – 1 (6 микроопераций)
1 – 4 – 1 (2 микрооперации)
1 – 1 – 1 (3 микрооперации) Этап RAT.
На этой стадии конвейера поддерживается переименование регистров (логических) программных в физические для исключения конфликтов WAR и WAW. Реальные программные регистры могут быть заменены в микрооперации любым из 40 внутренних, находящиеся в буфере.
Кроме того, на этой стадии к коду микрооперации добавляется поле статуса и поле «флагов», после чего микрооперации поступают в пул микрооперации, поле микрооперации дополняется разрядами для хранения значений самих операндов.
Структура микрооперации R*R ->R
сост
Устройство выборки (декодирования)
Пул инструкций.
Пул инструкций принимает поток микроопераций, определяемый программным кодом. Он представляет адресуемую память, состоящую из 40 регистров. Он содержит микрооперацию ожидающую выполнения, а также те, которые уже выполнены, но не получили статус «фиксации». Устройство диспетчеризации может выбирать для выполнения любую микрооперацию при готовности операндов. Максимально 2 физических регистра со статусом завершения могут быть прочитаны в каждом цикле.
Устройство диспетчеризации / выполнения.
Устройство диспетчеризации / выполнения является устройством безпорядоченного выполнения, которое диспетчеризирует и выполняет согласно зависимости данных и доступности ресурсов. Выбор и диспетчеризация микроопераций из пула инструкций управляется станцией резервирования. Она постоянно сканирует пул инструкций с целью поиска микроопераций готовых для выполнения. Т.е. все источники – операнды доступны и диспетчеризация их к доступным устройствам.
Результат выполнения микрооперации возвращается в пул и хранится совместно и микрооперациями до тех пор, пока не обработаются устройством восстановления. Процесс выполнения и диспетчеризации является классическим процессом безупорядоченного выполнения, где микрооперации обрабатываются в соответствии с готовностью данных и наличия ресурсов без учета порядка следования в программе.
Когда 2 или более микрооперации одного типа претендуют в одно и тоже время на один ресурс, они выполняются в порядке FIFO поступления в пул.
Исполнение микрооперации осуществляется двумя целочисленными устройствами, двумя устройствами с плавающей точкой и одним устройством обращения к памяти, позволяя диспетчеризовать до 5 микроопераций за такт. Устройство формирования адресов для команд перехода промахи перехода и сигнализирует BTB произвести перезагрузку конвейера. Устройство связи с памятью управляет микрооперациями «Загрузка» и «Запись». Для чтения из памяти достаточно одного адреса, поэтому эта операция декодирует в одну микроперацию. Запись декодируется в 2 микрооперации (адрес/данные).
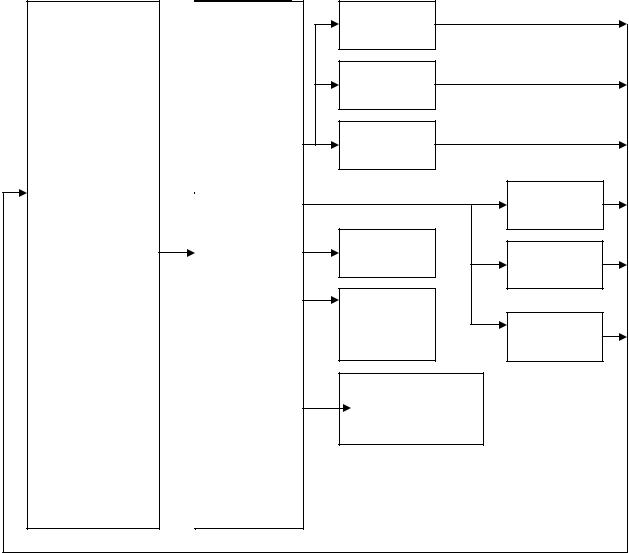
ПУЛ |
Формиров. |
|
|
микроопераций |
адресов |
|
|
Станция |
|
|
|
резервирова |
Плав.точк |
|
|
ния |
|
||
|
|
||
порт0 |
Целочисл |
|
|
операции |
|
||
|
|
||
порт1 |
|
Целочисл. |
|
|
|
||
|
|
операции |
|
порт2 |
Операции |
ММХ |
|
LOAD |
|||
|
Технолог. |
||
|
|
||
порт3 |
Операции |
|
|
|
|
||
|
STORE |
Плав.точк |
|
|
Форм адр |
||
|
|
||
порт4 |
Операции |
|
|
STORE |
|
||
|
|
||
очередь |
Данные записи |
|
|
|
|
||
микроинстр |
|
|
|
укций |
|
|
|
готовых к |
|
|
|
выполнению |
|
|
Блок обработки изменением последовательности.
Основная задача этого блока осуществлять контроль за состоянием микрооперацией находящейся в пуле инструкций и по мере их готовности к выполнению в других устройствах помещать их для выполнения. Попав в пул, микрооперация становится доступной Для выполнения в функциональных устройствах, о чем свидетельствует бит «готовности»
в поле типов микрооперации. Длина очереди 20 элементов.
Диспетчер распределяет микрооперации по портам, которые связаны с функциональным устройством. При этом каждый порт имеет свои собственные очереди, в виде FIFO. Некоторые функциональные устройства разделяют один порт, который является мультиплексным. Может случиться так, что в такте будет несколько микроопераций, претендующих на обработку. В этом случае вступает механизм приоритета, учитывающий «важность микрооперации» и ее момент поступления в ROB (пул инструкций). Так, например микрооперация перехода считается важнее, нежели микрооперация обработки целых чисел.
Микрооперация, попав в порт после обработки в функциональном блоке «возвращается» в пул инструкций, получая статус «выполнена». Функциональный блок должен «знать» адрес регистра в ПУЛе, значение которого должно сопровождаться инструкцией.
Т.е. являться тегом ее в процессе всей обработки. Исходя из стадий конвейера, который реализует работу блока, а их 3. Можно предположить, что:
1)ROB является полностью ассоциативной памятью.
2)для выдачи микроопераций в станцию резервирования в ROB участвуют только регистры с меткой «очередь» (стадия резервации).
3)Поиск осуществляется по коду операции или нескольких их возможных значений.
4)Каждый порт для организации связи с ячейкой ROB имеет магистраль, на которую выходит регистры ROBа. Только в этом случае поиск может быть осуществлен за один такт и эти же регистры могут выдать информацию в порт в следующем такте. Для возвращения результата в ROB функциональные блоки ы также должны иметь собственные магистрали для записи результатов в ROB.
Основное назначение блока восстановления.
Основное назначение блока восстановления - отправлять результаты спекулятивного выполненных микроопераций в машинные регистры, адресуемые в программном коде или в ячейки оперативной памяти. Т.е. следить за выполнением микрооперации в пулt инструкций и записывать результаты их выполнения строго согласно программному коду. Для этого подобно станции резервирования блок восстановления постоянно контролирует состояние микрооперации в пуле инструкций, просматривая, чтобы они были выполнены и не имели бы зависимости от других микроопераций в пуле, прежде чем фиксировать их окончательные результаты в процессоре, учитывая при этом наличие прерывания исключений и условие перехода.
Устройство восстановления способно восстанавливать до 3х микроопераций в такт, после того , как результаты микрооперации зафиксировали в машинных регистрах , они удаляются из пула. Подобно блоку отправки / выполнения конвейер блока восстановления имеет 3 стадии.
1)Анализ выполнения операции
2)Запись результатов в машинные регистры
3)Удаление выполненных микроопераций.
Устройство сопряжения с шиной предназначено для связи процессора с кэш памятью 1 ого и 2 ого уровня и системной памятью. Связь с кэш 1-ого уровня осуществляется для

кэш данных и кэш команд, осуществляя реализацию модифицированной гарвардской архитектуры. Связь с памятью 2 ого уровня осуществляется по отдельной шине 64 бит. Системная шина представляет собой группы сигналов независимых. функционально друг от друга, тем самым, обеспечивая конвейерную организацию. Для обеспечения конвейерной организации устройство шинного интерфейса содержит буфер запросов к памяти, состоящей из очередей по записи и чтению. Данный буфер обеспечивает, например выполнение запросов чтения, давая возможность «обгонять» операциям чтения, операции записи, тем самым осуществлять спекулятивное чтение данных, то есть доставляя их заранее в процессор.Следует отметить запись осуществляются только строго в программной последовательности.
С учетом безупорядоченного выполнения и чтения как следствие данного режима устройство сопряжения с шиной или «записи/чтения» должно обеспечивать следующие условия:
1)Запись никогда не выполняется спекулятивно
2)Запись выполняется только в программном порядке
3)Операции записи диспетчеризуются только когда адрес и данные доступны и нет более старшей записи, ожидающей диспетчеризации
4)Запись может быть блокирована, чтобы дать возможность ее обходить операциям чтения.
5)Возможность «спекулятивного» выполнения чтения когда более младшая операция чтения обгоняет старшиеперации чтения .
Для реализации чтения необходимо:
Для записи
В связи с этим каждому входу очереди запросов на запись соответствует Очередь SRQ – содержит адрес записи
Очередь SDQ – содержит данные записи
Для очереди на чтение соответствующей очереди LRQ
Вход SDQ содержит результат, который должен быть записан после того, как все предыдущие микрооперации в пуле будут в фазе завершения, как только будет разрешение их удаления данные должны быть записаны в память.