

ORGANIZATsIYa_EVM
.pdfустройства. Для сокращения времени на выполнение операции умножения применяют два метода: логический и аппаратный. Логический использует одновременное умножение на два или более разрядов множителя. Комбинационная схема анализирует группу разрядов, активизирует работу сумматора и сдвигателя. Аппаратный метод включает в себя комбинационные схемы ускоренного переноса, совмещения во времени операций сдвига и сложения, табличные методы умножения, в которых используются программируемые запоминающие устройства. В зависимости от комбинаций входных сигналов ( групп разрядов множимого и множителя) на выходе ППЗУ формируется произведение. Операция умножения в этом случае выполняется за один такт.
Кроме арифметических операций операционный блок выполняет ряд логических действий над операндами. Это И, ИЛИ, сложение по модулю два.
Операции над операндами проводят поразрядно .В многофункциональных АЛУ в целях экономии затрат на аппаратные средства при операциях над многоразрядными числами используют побайтную обработку в однобайтном тракте операционного устройства. Например, при обработке четырехбайтных операндов потребуется соответственно четыре такта работы логического сумматора, а в случае нахождения одного из операндов в оперативной памяти , потребуются кроме тактов выборки его из памяти еще такты для выравнивания на целочисленную границу считанного операнда в тракте операционного устройства так как операнд в памяти может находиться начиная с любого байта ,поэтому чтобы производить операцию над одноименными разрядами операндов и требуется эта корректировка.
Для ускорения выполнения логических операций за счет аппаратных издержек стали использовать отдельный блок логических операций, по другому стали применять блочную структуру операционного устройства. Мы уже говорили о блочном построении АЛУ для операций с плавающей точкой, так вот тенденция этого направления стала определяющей при внедрении конвейерной обработке команд в процессоре.
Основной принцип работы ускорителя выполнения логических операций-это обработка операндов словами, а не побайтно, что приводит к сокращению числа сдвигов работе сдвигателя за счет сдвига группы байт в одном такте.
Так, например, при побайтной обработке при расположении операнда в границах двойного слова (а именно такова ширина шины выборки из памяти команд/данных во многих архитектурах) требуется четыре такта как максимум для подачи байтов слова в УЛК и плюс такт на подачу второй части двойного слова на сдвигатель, то для выравнивания при обработке словами в четыре байта потребуется всего два такта.
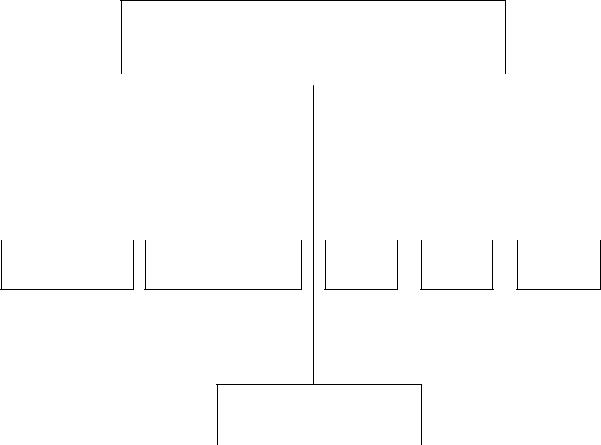
КЛАССИФИКАЦИЯ АРИФМЕТИЧЕСКИЛОГИЧЕСКИХ УСТРОЙСТВ
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ПО СПОСОБУ |
|
|
|
ПО СПОСОБУ |
|
|||||||||||||||
|
ДЕЙСТВИЯ |
|
|
|
ПРЕДСТАВЛЕНИЯ ЧИСЕЛ |
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
паралельные |
последовательные |
Фикс |
Плав |
Двоично |
|
|
точкой |
точкой |
десятичн |
ПО АРХИТЕКТУРЕ
|
|
|
|
|
|
|
БЛОЧНЫЕ |
|
МНОГОФУНКЦИОНАЛЬНЫЕ |
||||
|
|
|
|
|
|
|
Конвейерная обработка. Конвейерная обработка команд в процессоре.
Конвейерная обработка команд в процессоре и еѐ проектирование относится к так называемому методу «совмещения операций», который кроме вышеуказанной конвейеризации включает еще и параллелизм.
Параллелизм является более высокой ступенью обработки команд в процессоре и совмещения операций в нем достигается путем использования нескольких копий аппаратных средств, из-за чего и достигается высокая производительность. Примером использования параллелизма может служить аппаратная поддержка организаций технологии ……………. в «INTEL», которая за счет дублирования части аппаратных средств позволяла организовывать двух поточную обработку команд и соответственно организации двух логических процессоров на базе одного физического кристалла.
Другим примером может служить принцип работы POWER 5 SMT. Другими словами технология параллелизма это промежуточная архитектура или организация аппаратного комплекса между конвейерной организацией скалярных и суперскалярных процессоров и многопроцессорной системой..
Конвейерная организация в общем случае основана на разделении подлежащих к исполнению функций на более мелкие части, называющиеся ступенями, и выделений для каждой из них отдельного блока аппаратуры. При этом конвейерную обработку можно использовать для совмещения этапов разных команд. Производительность при этом возрастает не за счет сокращения времени выполнения одной команды, а за счет одновременной обработки команд на конвейере. Подобная технология «расчленения» выполнения команды на более мелкие этапы была еще использована в процессорах СISC архитектуры с микропрограммным управлениям; но эта технология предполагала монополизацию аппаратных средств микропрограммой на все время выполнения команды в процессоре. В принципе организация конвейерной обработки с микропрограммным управлением возможна, но для этого каждая ступень конвейера должна иметь свои микрокоманды и память для их хранения. А это связанно с аппаратными изменениями. Хотя попытки такой организации были. Примером тому был блок акселератора со своей памятью микропрограмм для выполнения операций сдвига, умножения, деления. Акселератор получал управления от основной микропрограммы, реализующей выполнение команды. Микропрограмма акселератора запускалась и шла параллельно выполнению микропрограмм. Для временного согласования работы акселератора и микропрограммы процессора микрокоманды содержат специальные микрооперации, осуществляющие остановку микропрограмм в случае необходимости.
Но в этом случае параллельная обработка осуществлялась только в рамках одной команды, это сокращало время еѐ выполнения. Максимум чего добивалась CISC архитектура это организация двухступенчатого конвейера благодаря применению модифицированной гарвардской архитектуры в структуре блока выборки команд. За счет совершения этапов выборки команды и выполнения. И так в начале 80-х стало ясно, это CISC архитектура процессора на базе принципа Фон-Неймана – совместной командной шины и
данных стала тормозом для дальнейшего повышения производительности работы процессора.
Для осуществления вышеуказанных задач необходимы другие принципы, которые были реализованы в RISC архитектуре. Но с другой стороны те наработки в программном обеспечении CISC процессоров нельзя было откинуть. Пример тому INTEL, которая для сохранения программного продукта оставила «старый» уровень архитектуры команд и для реализации конвейера в своих процессорах стала «резать» свои команды на микрооперации аппаратными средствами после выборки команд из памяти и размещения в буферных регистрах. При этом используемые для этих целей сложные декодеры( 3 штуки ) таким образом осуществляют поставку микроопераций в RISC ядро своих процессоров. В случае сложного декодирования команд, которые интерпретировались больше чем три микрооперации, используется микрокод, записанный в специальную память и представляющий набор микроопераций для выполнения этой сложной команды. Для указания принадлежности микроопераций в одной команде используется специальный бит в формате микрооперации, который устанавливается в «1» во всех микрооперациях принадлежащих команде, кроме последней ,в которой он устанавливается в 0 – указывая конец цепочки. Но конвейерная обработка команд в процессоре поставила перед разработчиками процессоров новые задачи, решение которых было связано с устранением конфликтов возникающих при работе конвейеров.
Суть этих конфликтов заключается в логических взаимосвязях элементов программного кода, который не вызывают конфликтов при их последовательном выполнении, и начинают конфликтовать при совмещении операций. К такой категории конфликтов относятся:
1)конфликт по данным
2)структурный конфликт – возникает при распределении аппаратных ресурсов при выполнении команд, когда не возможно их одновременное использование.
3)конфликты по управлению, возникающие при конвейеризации команд переходов, которые изменяют значение текущего адреса счетчика команд, и осуществляют ветвление в программе вынуждая приостанавливать конвейер до получения результата, по значению которого осуществляется переход или нет.
Структурные конфликты Прежде чем рассматривать подробно эти конфликты и способы их устранения,
определим основные этапы выполнения команды в процессоре IF-чтение команды из памяти
ID-декодирование и формирование адреса операндов ,подготовка операции для выполнения
EX-выполнение операций
MEM-если операнд находится в оперативной памяти(КЭШ) необходим такт для запроса за операндом.
WB-запись результата операции в регистровый файл.
Предполагаем RISC архитектуру ,с использованием команд STORE и LOAD (чтение и запись результата в память) стадия МЕМ.
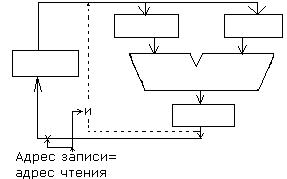
Пример: структура конфликта
IF ID EX ….EX WB
IF ID…….. .EX WB
Этап выполнения EX предыдущей команды занимает больше чем один такт, вторая команда вынуждена ждать освобождение операционного блока.
Пример2: |
|
|
|
|
IF ID EX MEM WB |
LOAD R1(R6) |
|||
IF ID EX [задержка из-за того ,]WB ADD R2 R3 R4 |
||||
|
[что регистровый файл имеет только один порт записи] |
|||
,где []-задержка |
|
|
|
|
Пример3: 1- IF ID EX MEM WB |
|
|||
2- |
IF ID |
EX [ |
] WB |
|
3- |
IF |
ID |
EX [ |
] WB |
4- |
|
[ ] |
IF ID |
EX WB |
Конфликт четвертой команды с первой одновременный запрос в память за данными и командой. Конфликт будет устранен при раздельном хранении
команд и данных(гарвардская архитектура) |
|
|
|
Конфликт по данным |
|
ADD R1 R2 R3 |
IF ID EX WB |
|
SUB R4 R1 R5 |
IF [ |
] ID EX WB |
Невозможна одновременная запись и чтение в R1.
Вариант обхода конфликта
Конфликты по управлению Конфликты по управлению, как было сказано раннее, связаны с командой
перехода, которые в любой системе команд являются условными или безусловными.
На первый взгляд, безусловные команды не должны вносить конфликт в работу конвейера, но дело в том ,что блок выборки команд узнает о типе команды на этапе дешифрации, а во вторых целевой адрес в лучшем случае будет вычислен в блоке выборки команд. Если в нем присутствует выделенная подсистема, предназначенная для быстрого выявления команд переходов и вычисления

целевого адреса. Благодаря этой подсистеме обе эти задачи (переход и адрес перехода) решаются на этапе декодирования, это уменьшает издержки работы конвейера.
Рассмотрим пример четырех случаев конвейера с предположением , что целевой адрес вычисляется на этапе работы блока выполнения(Е) Команды перехода:
Еще больше задержки возникают при выполнении условного перехода ,когда результат зависит от выполнения предыдущей команды в большинстве случаев и переход может быть определен только после анализа результата, тогда количество удаляемых команд будет зависеть от времени получения результата.
В связи с изложенной проблемой возникает задача: разработка способов, позволяющих уменьшить данные издержки.
Динамические предсказания переходов Один из способов – хранить специальную таблицу, в которую записывать
условные переходы , и там их искать, когда они появятся снова простейшая версия: для каждой команды перехода –таблица содержит одну ячейку , в которой храниться адрес команды перехода и бит ,указывающий был ли переход или нет предыдущего результата и в соответствии с этим осуществляется переход.
Такая схема эффективна в циклах.
Существует несколько способов организации таких таблиц .В сущности ее можно организовать в форме КЭШ памяти, где в качестве тега храниться адрес команды перехода. Данная схема эффективно в том случае если задержка в вычислении целевого адреса минимальна.
Для улучшения работы схем в КЭШ можно записывать целевой адрес,вычисленный при 1 процессе.
СЧАКсчетчик адреса команд БВКблок выборки команд

Однобитовая схема Однобитовая схема предсказание перехода обладает тем недостатком, что
прогноз будет предсказан при в ходе в цикл и выходе из него каждый раз. Для увеличения вероятности предсказания применяется двухбитная схема предсказания.
00-очень малая вероятность перехода, предсказание отсутствует . 01-малая вероятность перехода 10-большая вероятность перехода, предсказание делают переход
11очень большая вероятность , предсказание делают переход. нет перехода
ЛЕКЦИЯ N12

БЕЗУПОРЯДОЧЕННОЕ ВЫПОЛНЕНИЕ
Еще одним способом повышения производительности работы конвейера является использование метода без упорядоченного выполнения команд в процессоре, суть которого заключается в обработке команд на конвейере с изменением последовательности программного кода. Для наглядности приведем промер:
Для наглядности приведем пример:
1 2 3 4 5 6 7 8 9 10 11
1.Load R1 m  RAW 2. ADD R3R1R2
RAW 2. ADD R3R1R2 
3.SUB R4R5R6
ID m m m m m w
ID EX W
ID EX W

В данной последовательности команд команды 1, 2 имеют зависимости RAW которая не может быть устранена т.к. 2ая команда ждет операнда из памяти, обращение к которому может занимать несколько циклов, а в случае «промаха» в кэш, количество их будет увеличено.
С другой стороны команда 3 не связана по данным с 1й и 2й командой, и перестановка ее в позицию 2 не скажется на результате программы. Таким образом будет устранен простой конвейер.
Load R1 m SUB R4R5R6 ADD R3R1R2
1 2 3 4 5 6 7 8 9
ID m m m m m W ID EX W
ID EX W
Предположение что возможно одновременно чтение и запись в регистровый файл.
Идеология организации без упорядоченного выполнения
В свое время узел формирования адреса был вынесен из операционного блока, с той целью чтобы освободить основной сумматор от вычисления адресов операнда и перенести в блок выборки команд, в котором в совокупности с КЭШ памятью команд организован законченный цикл подготовки операндов к выполнению операций над ними в операционном блоке, таким образом сформировать 2х ступенчатый конвейер в процессоре.
Идеология без упорядоченного выполнения основана на предварительном анализе команд по возникновению конфликтов при их выполнении, задержки их выпуска по конвейер и пропуска внеочередных команд, которые могут быть беспрепятственно выполнены. Конфликты эти относятся в первую очередь к группе конфликтов по данным. Конфликты эти классифицируются по типу RAW и WAR, WAW.
Первоначально анализ возможного возникновения этих конфликтов проводился на стадии декодирования и вычисления операндов, в дальнейшем для реализации без упорядоченного выполнения формирование адресов операндов выделили в отдельную стадию конвейера с той целью чтобы дать возможность формировать адреса операндов внеочередным командам поступающим на конвейер. Таким образом стадия декодирования была разбита на два такта:
1.Такт выдачи
2.Такт чтения операндов
Такт выдачи стал контролировать ситуацию использования регистра результата в команде, предыдущими командами в качестве регистра результата (WAW – запись после записи) с целью избежать искажения при предыдущих команд. Если такая ситуация могла иметь место, то команда не выпускала на конвейер.
На этапе чтения операндов анализировать стали возможность возникновения RAW при выпуске команды на конвейер, т.е. операнды источники проходят проверку не являются ли они регистрами результата предыдущих команд, находящихся в стадии выполнения или в данный момент не происходит ли запись из функционального устройства по адресу источника в команде.
В связи с без упорядоченным выполнением, завершающую стадию конвейера, связанную с записью результата в регистровый файл, пришлось разделить на 2 части.
Это первая предварительная - стадия завершение. Вторая – запись результата.
На этапе запись результата блок управления конвейером отслеживает возможность возникновения конфликтов типа WAR для того, чтобы исключить искажение значений в регистрах, используемых в качестве источников предыдущими командами находящимися на стадии выполнения.