

ORGANIZATsIYa_EVM
.pdfТехнология нормализации результата вычисления будет сводиться к сдвигу мантиссы результата влево до первой значащей единицы в старшем разряде.
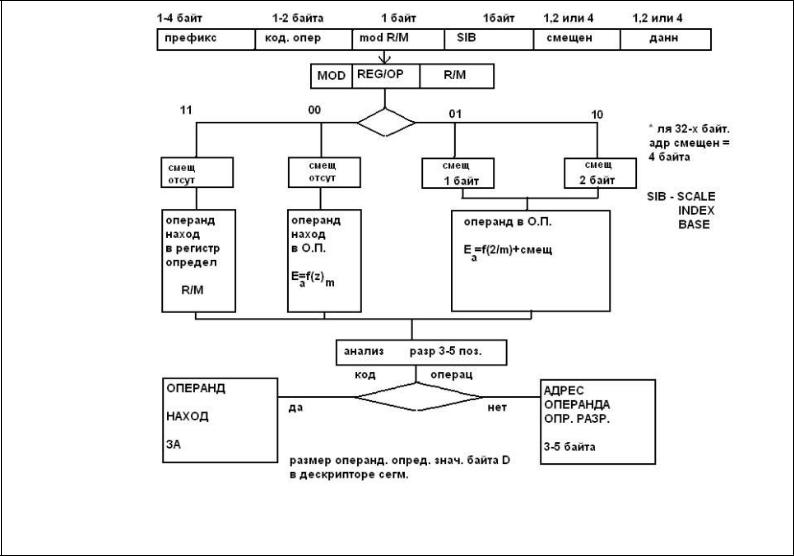
Символьное и двоично-десятичное представление информации.
Так как процессор обрабатывает не только числовую информацию но и алфавитно –цифровую, то для отображения такой информации используют специальные коды, количество разрядов для кодирования каждого элемента алфавита определяет его размер.
Для выполнения операций десятичной арифметики применяют двоично – десятичное кодирование, где каждая цифра от нуля до девяти представляется в двоичном коде и использованием четырех разрядов, так как 2*4=16, то коды
1010-1111 не используют и при обнаружении их в операциях десятичной арифметики формируется признак особого случая в процессоре.
Однако использование этого кода связано с трудностями при обнаружении переносов в операциях так как перенос из тетра-ды в тетра-ду осуществляется по модулю 16 а не 10.
Для того чтобы обнаружить перенос к одному из операндов в каждой тетра-де прибавляют 6. Если при сложении сумма в тетра-де будет больше
Или равна 10 ,то будет перенос в следующую, если переноса не будет ,
То необходима корректировка результата в тетра-де, из которой не было переноса (из нее необходимо вычесть, а это эквивалентно корректировке результата на плюс десять -6=-(16-10) .Вычитание16 с нулевыми разрядами в тетра-де 10000 не влияют на результат в тетра-де, а прибавление кода 10 (1010)
даст правильный результат)
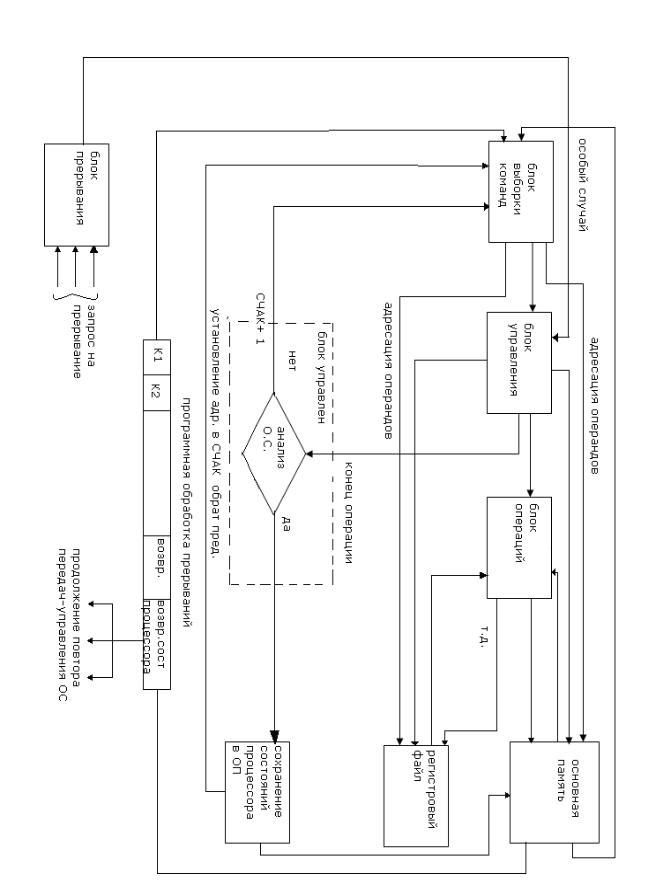
Последовательная обработка команд в процессоре.
1)Начало выполнения любой команды в процессоре начинается с выборки еѐ из памяти, размещении в регистре команд и модификация адреса счетчика команд в зависимости от длинны команды , поступающий на обработку в процессор.
2)На следующем этапе осуществляется декодирование команды еѐ полей, содержащих информацию о месте нахождения операндов; кода операции для логических и арифметических команд, а для команд управления,
вчастном случае переходов, расшифровка условий перехода и формирование адреса перехода.
3)По окончании декодирования и подготовительных операций начинается выполнение команд. Блок управления координирует работу всех узлов процессора «разбивая» выполнение команды на временные интервалы ( такты, микрокоманды, микрооперации) в зависимости от архитектуры его реализации «жесткая логика» или «микропрограммное управление».
Блок операций в различных архитектурах реализуется по-разному. В простейшем варианте представляет арифметическое устройство.
Может в своем составе содержать специальные блоки для выполнения логических операций, операций с фиксированной и плавающей точкой.
В архитектуре с конвейерной организацией в скалярных процедурах, с без упорядоченным выполнением, блок операций содержит пулы инструкций (микроопераций) ожидающих выполнение и выполненных, различные устройства для выполнения арифметических и логических операций,
обеспечивающих параллельную обработку на аппаратном уровне. Блок операций результат своих вычислений размещает в регистровый
файл или в оперативную память. Для RISC архитектур связь оперативной памяти осуществляется специальными микрооперациями или командами
STORE и LOAD.
Для контроля выполнения команд в процессоре существует специальный узел, отвечающий за сбор информации о всех отклонениях и возмущениях ( прерываний ), нарушающих последовательное выполнение программы. Все эти ситуации классифицируются как особые случаи, и в случае их возникновения в процессоре происходят прерывания с сохранением его текущего состояния и порядком управления обработки прерывания, со сменой текущего адреса команд адресом первой команды в обработчике прерываний. По окончании обработки прерывания возможны различные продолжения с передачей управления прерванной программе, операционной системе, повтором выполнения команды, аварийной остановкой.
ЛЕКЦИЯ N 9
Тема лекции:
1.Состав и назначение основных блоков процессора. Архитектура блока Тема выборки команд.
ВВЕДЕНИЕ
Как было отмечено ранее, хранение и продвижение данных потоков определяется двумя принципами ( Фон-Неймана и Гарвардской архитектурой), которые в современных архитектурах существуют совместно. В соответствии с наличием потоков команд и данных в состав процессора входят блоки , в функции которых заложены обработка и контроль за продвижением данной информации, независимо от выбранного принципа. Конечно же, в каждой архитектуре блоки эти имеют свои особенности, свои аппаратные решения, но основные функции их одни и те же. Такими блоками являются:
Блок выборки команд – продвижение, прием команды из процессора, обработка адресной информации, формирование адресов операндов и следующего адреса команды.
Блок операций – обработка данных, согласно алгоритму, определенному коду операции в команде.
Блок управления – координатор всех операций в процессоре при выполнении команды.
Рассматривая форматы команд и данных, обрабатываемых в процессоре, мы отметили, что их выбор и определяет архитектуру процессора как:
CISC – архитектура – набор сложных и простых команды реализующихся обычно за несколько тактов более 3-х или микропрограммой или группой микропрограмм
RISC – архитектура – набор простых команд реализующихся за один-два такта и имеющих формат регистр-регистр.
Процесс выполнения команды в процессоре может быть нарушен ситуацией возникающей при сбоях и отклонениях связанных особым случаем Данные нарушения контролируются специальным блоком прерывания. Архитектурно блок прерывания может располагаться как в кристалле так и отдельные его компоненты на системной плате ( контроллер прерывания 8252, и контроллер
APIC).
Знакомство с архитектурой блоков, их функционированием мы начнем в той последовательности , в какой происходит обработка команды в процессоре.
БЛОК ВЫБОРКИ КОМАНД
При разработке архитектуры Б.В.К. необходимо учитывать следующие обстоятельства:
1) Процессор производит обмен информацией с памятью за один цикл группой байт, в которой количество байт определяется числом младших разрядов, не участвующих в адресации.
Команды в ОП могут располагаться внутри адресного пространства, начиная с любого байта, поэтому прежде чем активизировать декодеры, расшифровывающие поля команд, необходимо произвести поиск начального байта команды, и затем, в соответствии с форматом команды подключить соответствующий байт команды к соответствующему декодеру или направить
их(поля) в соответствующие регистры(базы, смещения и т.д.). Различные архитектуры решают эту проблему в соответствии с форматом команд используемых ими.
Влюбом случае регистр адреса команды должен содержать все младшие разряды адреса, которые игнорируются при обращении ОП процессора за данными.
2)Для формирования адреса следующей команды необходимо знать кодировку длины команды, заложенную в формате команды. Для этого вышестоящий уровень архитектур машинных команд должен представлять эту информацию.
Всистемах с конвейерной организацией, осуществляющих запуск нескольких команд за один цикл Б.В.К. проделывает предварительную разметку пакета команд, поступающих на декодирование.
3)Б.В.К. должен содержать схему, контролирующую выполнение этапа декодирования ,а после его завершения осуществляет подачу другой команды на дешифратор, то есть осуществлять продвижение команд по буферу ,а в случае обнаружения свободного места достаточного для размещения новой порции командной информации организовать запрос с целью поиска необходимых данных на всех уровнях памяти согласно иерархии. 4)Современные системы работают с виртуальной памяти. Для этого аппаратные средства содержат блок трансляции логических адресов в физические. Адрес команды также подвергается этим преобразованиям при обращении к системной памяти, а вот содержимое регистров адресов команд - это эффективные адреса, то есть блок выборки команд в своих адресах отслеживает адреса команд в рамках страницы, поэтому в случае обнаружения выхода за рамки страницы в процессе модификации адресов Б.В.К. должен сформировать сигнал прерывания в процессоре.
При наличии буферной памяти команд для, того чтобы уменьшить вероятность промаха блок выборки команд(Б.В.К.) должен организовать своевременную загрузку следующих данных.Для этого каждый раз после подкачки команд из буферной памяти команд(Б.П.К.) в оконечный буфер не дожидаясь следующего обращения за командой в Б.П.К.,Б.В.К. осуществляет контроль за наличием следующих данных в Б.П.К. и при их отсутствии в памяти команд и при условии свободного места в оконечном буфере загружает данные в Б.П.К. и оконечный буфер, а при отсутствии места в оконечном буфере загружается только Б.П.К.
Вкомпьютерах с конвейерной организацией причиной задержки конвейера является команда перехода, то есть конфликты связанные с этими командами относят к конфликтам по управлению. Методом решения этих конфликтов является аппаратные средства так называемые блоки предсказания переходов, которые формируют адрес следующей команды на основании
статических и динамических данных ,о переходах в процессе выполнения команды.
Блок выборки в таких компьютерах сохраняет в своем составе основные блоки ,которые содержат Б,В.К. в процессоре с последовательным выполнением с одним существенным отличием. Это узел формирования адреса, обращения к КЭШ инструкции. Адрес этот формируется блоком предсказания переходов(Вranch taget buffer B.Т.В.), исходя из практики что % предсказания ≥90% , данная технология дает положительный результат.
Описание работы блока-выборки команд по структурной схеме. На примере развития архитектуры блока выборки команд можно отчетливо проследить как две альтернативные идеи: фон-неймоновская и гарвардской
архитектуры нашли свое применение в рамках одной и той же вычислительной системы, получив название «модифицированная гарвардская архитектура». На первоначальном этапе блок выборки команд представлялся счетчиком адреса очередной команды, отслеживающей выполнение команд (программа в процессоре). Источником для загрузки переданной команды для выполнения являлась оперативная память адреса, которая определялась регистром адреса команды ( IP ). Выполнение следующей команды, а точнее еѐ выборка из памяти начиналась только после выполнения предыдущей. Повышение производительности вычислений за счет аппаратных средств привело к организации иерархической структуры памяти, а точнее к появлению КЭШ, и нескольким буферным регистрам для команд, дававшим возможность предварительной выборки из памяти очередной порции команд, ждущих выполнение в процессоре. Выборка команд по-прежнему осуществлялась по общей шине команд/данных, связывающих процессор-память, сохраняя классический принцип организации Фон-Неймана, но только с уменьшением количества запросов за командами в память, благодаря наличию буферных регистров для команд.
С другой стороны усложнение системы адресации данных для выполнения на первоначальном этапе, а именно базирования и индексирования привело к необходимости для вычисления адресов использовать основной сумматор блока арифметики. И только внедрение дополнительного оборудования «адресной арифметики» в структуру блока выборки команд позволило освободить основной сумматор и совместить в процессоре этап выполнения очередной команды с этапом подготовки следующей для выполнения, включающий в себя выборку из буферных регистров, декодирование, формирование адреса операндов для обращения в память. Но в такой архитектуре не был по-настоящему применен принцип гарвардской архитектуры, и только с появлением КЭШ команд, являющихся результатом идеи увеличения емкости буферных регистров, привело к появлению отдельной шины команд в структуре блока выборки команд и с адресной шины

обращение к этой памяти. Но эта КЭШ команда была и остается не изолированной от системной шины данных/команд, связывающей процессор и память. Шина это по-прежнему остается основной магистралью заполнения командной информации КЭШ команд. кроме того она является поставщиком команд в блок выборки. Команда из основной памяти и КЭШ непосредственно поступают в буферные регистры блока в случае отсутствия (промаха) команд в КЭШ команд. Таким образом формируя модифицированную гарвардскую архитектуру характеризующуюся наличием связи шины команд и данных в случае необходимости. Таким элементом связи в структуре блока является КВД
–коммутатор выдачи данных.
Всвязи с вышесказанным можно отметить, что БВК имеет основные источники для обработки команд:
А) системная память Б) буферная память ( КЭШ данных и команд )
В) буферная память команд Следует отметить, что в дальнейшем в архитектуре компьютера появилась и
отдельная КЭШ данных. Таким образом увеличилась глубина проникновения принципов гарвардской архитектуры.
Блок выборки команд имеет в своем составе: А) Буферные регистры
Б) Схему контроля за продвижение команд в ней В) Регистры для хранения адресов команд
Адресный узел блока выборки команд Основное назначение адресного блока выборки команд - отслеживать текущее
значение адреса выполняемой команды, его модификации в соответствии с длиной выполняемой команды.
При наличии буферных регистров и кэш памяти команд, адресный узел имеет достаточно сложную структуру в функциональные обязанности входят:
а) формирование адреса обращения за командой в кэш команд б) формирование значения адреса при обращении за командой в буферную или
системную память с учетом свободного места в буфере FIFO на момент запроса в) сохранение логического адреса обращения за командой в память вышестоящего уровня (кэш или системную память) и возвращение его в адресный тракт при загрузке команд из нее.
Как видно из схемы адресный тракт содержит два регистра команд, один из которых исполнительный, то есть выходы разрядов которого подаются на схемы модификации для формирования адресов обращения за командами в кэш команд, системную или буферную память. Это регистр РАК1.
РАК1 – отслеживает текущий адрес команды. Текущий адрес команды формируется схемой модификации управляемой кодом шины предыдущей команды.
Код длины кодируется в разных системах по-разному, в частности для IBM этот код длины укладывается в коде операций и для этой архитектуры схема выглядит следующим образом:
Схема
обновления
Как видим из блока схемы выход РАК1 поступает на две схемы формирования адреса запроса для загрузки очередной порции команд в буферные регистры: А) запрос к ОП (системная память, участвуют все разряды адреса команды) формируется с использованием схем коррекции ИКР+4 и ИКР+8 которые управляются блоком микропрограммного управления и схемой контроля за продвижением команд в буфере FIFO, фиксирующей наличие свободных мест в буфере.
Схема модификации ИКР+8 активизируется при наличии признака свободного регистра РБК3, используется только при обращении за командами в оперативную или буферную память. Значение модифицированного адреса команды подается на вход блока преобразования логического адреса в физический и возвращается в адресный тракт при получении команды из памяти.
Схема модификации ИКР+4 используется при выполнении цикла запроса в оперативную или буферную память в случае отсутствия команд в кэш команд и при наличии двух свободных регистров в FIFO указывая при этом что команды будут загружены в FIFO и кэш команд.
Эта схема также используется при загрузке модифицированного адреса в регистр РАК2 с той целью чтобы в случае двух свободных регистров РБК3 и РБК2 и обнаружении данных в кэш памяти команд указать на адрес команды, которая будет загружена из кэш команд в РБК2 и в следующем такте продвижения команд в буфере будет передана в РБК1 для выполнения в процессоре.
Значение РАК2 в этом же такте будет передано в РАК1.
Б) к буферу памяти команд (КЭШ команд, участвуют младшие разряды адреса команды, определяющие размер буферной памяти: старшая часть адреса используется как тег в теговой памяти на схеме не показанной)
Для этой цели используется схема ИКР+12, модификация производится каждый раз при запросе за командами в кэш команд, независимо от того есть ли свободные места в буфере. Запрос этот формируется для анализа наличия команд в памяти команд: если команды есть в памяти ,то они считываются и заносятся в буфер