

ORGANIZATsIYa_EVM
.pdfБЛОК ВЫБОРКИ КОМАНД POWER4.
Прежде чем рассматривать архитектуру блока выборки команд POWER 4 необходимо отметь следующее:
POWER4 является суперскалярным процессором с конвейерной организацией обработки команд. Как мы увидим далее, при рассмотрении технологии конвейерной обработки команд в процессоре возникают конфликты по управлению, связанные с выполнением команд переходов.
Для уменьшения времени простоя конвейера используется технология предсказания переходов то есть вероятностный метод продвижения команд по конвейеру .Не вдаваясь в подробности функционирования механизма логики предсказания переходов, который мы рассмотрим позже, отметим только то , что загрузка очередной порции команд в кэш инструкций из вышестоящего уровня иерархии памяти происходит по адресу, сформированному этой логикой (блоком предсказания переходов)
Так как адреса обращения за командами являются логическими при использовании виртуальной памяти и требуется их преобразование в физические, то для сокращения числа обращений к блоку преобразования адресов, используются буфера быстрой переадресации (TLB) , в которых хранятся значения адресов логических страниц и соответствующих им физические адреса , вычисленные ранее при первом обращении в память по выше упомянутым логическим адресам этих страниц.
Но в отличии от кэш данных механизм обнаружения команд в кэш инструкций и использование буферов быстрой переадресации намного сложнее и это в первую очередь связано с использованием вероятностного метода выбора инструкций из кэш.
Если при загрузке строки данных в кэш промах в дальнейшем при обращении к данным этой строки может возникнуть при изменении их самим процессором или другим агентом системы (многопроцессорные системы) , то при загрузке строки команд в кэш инструкций нет ни какой гарантии, что все команды в этой строке будут выполнены полностью, прежде чем будет загружена другая порция команд в кэш инструкций (из за команд переходов).
Уменьшить вероятность промаха можно уменьшением размера строки ,загружаемой в кэш инструкций, но при этом возрастает размер буфера переадресации.
Большой же размер строки приводит к увеличению числа команд переходов и усложняет логику предсказаний и снижает вероятность правильности предсказания ,поэтому был выбран компромиссный вариант – выбирать строку большого размера ,а анализ предсказания переходов осуществлять по секторам строки ,на которые она делиться. При чем РАЗМЕР
СЕКТОРА выбрать равным буферу , в который читаются команды из кэш инструкций для выполнения в процессоре. Но для этого пришлось вводить не один буфер TLB а два, потому что первый хранит физические адреса строк находящихся в кэш в соответствии с логическими адресами обращения за командами .а второй буфер осуществляет контроль за продвижением команд внутри строки каждый раз при загрузке очередного сектора из кэш инструкций в буферные регистры путем сравнения физических адресов из обоих буферов
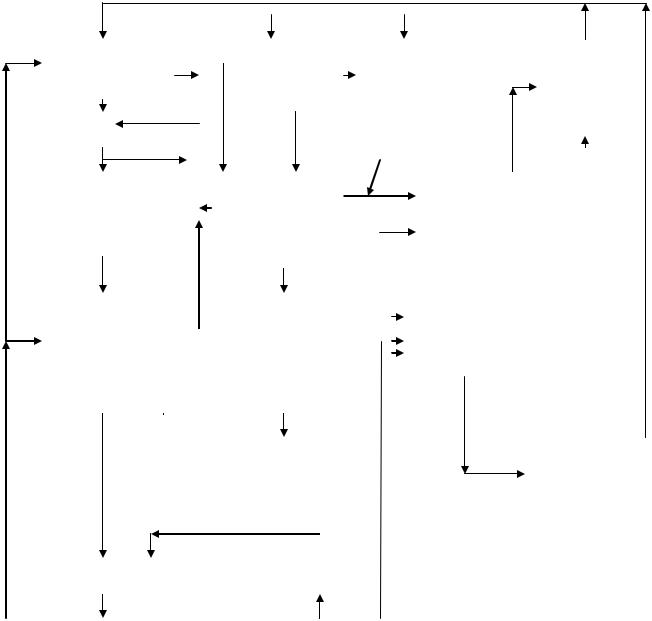
Инструкция выбирается из КЭШ инструкций по значению адреса IFARInstr.fetch address reg.
Обычно IFAR загружается согласно логике предсказания перехода.
Вслучае ошибочного предсказания ,необходимо будет произвести корректировку значения IFAR, чтобы продолжить выполнение потока инструкций в нужном направлении. Кроме этого изменение потока инструкций может быть вызвано прерыванием от внешних событий, в любом случае, как только в IFAR будет загружен адрес команды, то до восьми инструкций поступает на конвейер в каждом цикле.
Каждая строка в КЭШ инструкция составляет 128 байт, которая разделена на 4 эквивалентных сектора по 32 байта, которые определяют ширину данных записи/ считывания в цикле работы кэш памяти команд.
Вархитектуре Power взят буфер Т LB( translate looksid buffer) и SLB – (Segment looksid buffer) для преобразования эффективного адреса в реальный. Power4 содержит 4 буфера трансляции (по два на каждый процессор в двух ядерной архитектуре то есть на каждый процессор приходится кэш команд и кэш данных).
Когда конвейер инструкций готов получать инструкцию, содержимое IFAR посылается в полностью ассоциативный буфер IDIR(Instr. Directory), который адресуется частью эффективного адреса, другая часть которого используется как тег . Кроме этого теговая строка содержит 42 бита реального адреса, содержащие два полных физических адреса строк, переписанных из кэш L2 в кэш инструкций и находящихся в ней на данный момент. Так как размер кэш L2 составляет 1,5 МГБ, то для фиксации адресов двух строк из кэшL2 в кэш инструкций нужны эти 42 разряда.
Вблоке выборки команд имеется еще таблица переадресации IERAT , которая имеет такую же архитектуру как и выше упомянутый буфер с той лишь разницей , что в теговой строке содержится физический адрес-результат преобразования логического адреса. Содержимое этих двух буферных таблиц и является исходной информацией для определения наличия команд в кэш инструкций.
И так содержимое регистра адреса выборки инструкций ,обновляется принимая значение адреса первой инструкции в следующем секторе, после того
как он будет передан в кэш инструкций , выше упомянутые таблицы и в блок
предсказания где сформируется адрес команды, по которому возможно пой дет выполнение программы, если по данному адресу логика обнаружения команд перехода зафиксирует таковую или по другим адресам в считанном секторе в случае его нахождения в кэш инструкций .
Если в считанном секторе не будет обнаружен факт перехода и все команды в секторе будут выполняться последовательно, то в буфер инструкций будет загружен следующий сектор.
А сейчас вернемся к началу цикла выборки инструкций из кэш и рассмотрим подробнее механизм обнаружения их в памяти .
И так по значению в IFAR считывается значение реального адреса из “IDIR” эффективный и реальный адреса из таблицы IERAT.
IERAT (содержит эффективный и соответствующий ему реальные адреса) проверяется с тем чтобы проверить достоверность входа и чтобы реальный адрес сравнить со значением IDIR. Если в таблице IERAT установлен флаг
INVALID, то
EA должен быть транслирован из TLB и SLB. Выбранная инструкция
«пузырится». Если IERAT VALID, RAIPIR=RAIER устанавливая Icahehit i=1, разрешает продвижение конвейера и работу блока предсказаний и IFAR вновь
устанавливается в соответствии с индикатором ВТВ. Активизируются декодеры, начинается формирование групп, логика разрешает выбранным инструкциям продвигаться по конвейеру.
ЕСЛИ обнаружен промах, возможны несколько сценариев:
1)буфер предвыборки проверяется есть ли в нем затребованная инструкция, и если да, логика продвигает эти инструкции к конвейеру: как если бы они были выбраны из КЭШа и записывает также критический сектор в КЭШ.
2)Если инструкции нет в буфере, формируются два последовательных запроса к КЭШ уровня L2. L2 обрабатываются, в результате чего будет произведена запись в кэш инструкций и в буфер предвыборки .
Вслучае присутствия затребованной инструкции в буфере предвыборки, организуется запрос в кэш L2 за очередной строкой.
Вдополнение к механизму выборки инструкции по затребованным запросам БВК осуществляет выборку инструкций, которые в скором времени будет затребована для выполнения.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Кэш |
|
|
|
Ra |
|
тег |
|
|
Ra |
Ea |
|
V |
|
|
|
|
Буфер |
|
|
|||||||||||||||
|
инструкций |
|
|
|
|
|
|
* |
|
IDIR |
|
|
|
|
|
* |
|
|
|
|
|
|
|
Предварит |
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
IERAT |
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
* |
|
dir |
|
|
|
|
|
* |
|
|
|
|
|
|
|
ельной |
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
выборки |
|
|
|
|
|
и |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Hit=0 |
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Логика |
|
|
|
|
Схема |
|
|
|
|
|
|
|
|
|
|
Схема обнаружения |
|
|
||||||||||||||||
|
обнаружения |
|
|
|
|
обнаружения |
|
|
|
|
|
|
команд в буфере |
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||||||
|
Команд |
|
|
|
|
команд в кэш |
|
|
|
|
|
|
Предварительной |
|
|
|
|
||||||||||||||||||
|
перехода |
|
|
|
|
инструкций |
|
|
|
|
|
|
выборки |
|
|
|
|
||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Блок |
|
|
|
|
|
|
Буфер |
|
|
|
|
Блок |
|
|
|
|
|
|
|
|||||||||||||||
|
предсказания |
|
|
|
|
|
|
Инструкций |
|
|
|
|
Трансляции |
|
|
|
|
|
|
|
|||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||||||||
|
Адреса |
|
|
|
|
|
|
|
|
|
IBF |
|
|
|
|
адреса |
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||
|
перехода |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
BTB |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
V=0 |
|
|
|
|
|
|
|
||||||
|
|
|
|
|
Hit=1 |
|
|
Схема |
|
|
|
|
Кэш L2 |
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
формирования |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
Групп |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
инструкций |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рег. Адр. Инстр. |
IFAR |
|
|
|
|
инкр |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
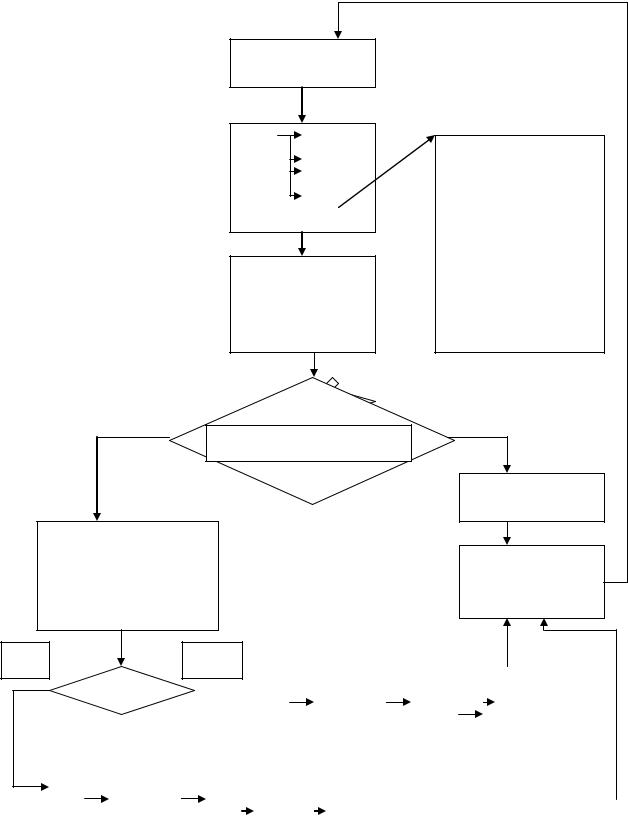
Установить hit:=0 Проверить наличие команд в буфере предварительной выборки
Буфер свободен |
|
||
IFAR |
IC |
в IFAR |
|
|
IDIR |
||
|
устанавливается |
||
|
IERA |
||
|
значение адреса |
||
|
BTB |
||
|
первой команды в |
||
IFAR:= ИНКР |
|||
следующем секторе; |
|||
|
|
||
|
|
если BTB не |
|
Чтение команд из |
скорректирует адрес, |
||
то будет в IBF |
|||
Кэш |
|
||
|
загружен следующий |
||
Анализ |
|
||
|
сектор из кэш |
||
IDIR,IERAT |
|||
инструкций |
|||
|
|
||
RAidir=RAierat |
|
||
|
|
Уст HIT:=1 |
|
|
|
Загрузить IFAR |
|
|
|
Значением адреса |
|
|
|
из BTB |
|
нет |
да |
|
Преобразовать |
|
Загрузить: |
||
|
EA |
RA |
|
1.сектор |
IC, IBF |
|
|
|
|
2.L2 |
буф. Пред. Выб. |
|
|
|
|
|
|
Преобразовать |
|
Загрузить: |
|
|
EA |
RA |
|
2строки |
|
|
|
|||
|
|
|
1.L2 IC: 2.L2 буф.пред.,выб. |
|
|
|
|
|
|
ЛЕКЦИЯ N10
Тема лекции: Процессор. Блок управления.
Классификация блоков управления по способам реализации выполнения команд: c жесткой логикой, микропрограммное управление
Блок управления.
Выполнение машинной команды в процессоре, как было отмечено ранее, разбивается на этапы называющимися машинными циклами.
Реализация этих этапов в процессоре осуществляется двумя способами управления: 1) микропрограмма ; 2) жесткая логика.
Прежде чем рассматривать эти два этапа отметим их применение в интерпретации команд в процессоре с точки зрения эволюционного развития его архитектуры.
Способ «жесткая логика» реализуется аппаратными средствами с использованием комбинационных схем, вырабатывающих распределенные во времени управляющие сигналы в процессоре, необходимые для выполнения команд.
В этих комбинационных схемах связи между базовыми логическими элементами являются постоянными и определяются зависимостями выраженными в математических формулах Булевой алгебры, которые устанавливают соответствия между значениями входных и выходных сигналаов.
Модернизация логики работы такого блока управления возможна только путем схемного изменения.
Микропрограммное управление.
Суть этого способа заключается в том что блок управления содержит память, в которую записываются микропрограммы, в которых каждая микрокоманда управляет процессором в течение машинного такта. Для этого в каждом такте процессора из памяти микропрограмм происходит чтение микрокоманды, которая содержит информацию, изменяющую состояния элементов в блоках процессора в течение машинного такта.
Данный способ позволяет динамически изменять архитектуру блока управления, добавляя новые функциональные возможности путем добавления в управляющую память новых микропрограмм. Для этого нет необходимости изменять все схемные связи в блоке управления. Для этого только необходимо чтобы память микропрограмм была перезаписываемой.
Применение этого способа дало разработчикам возможность увеличить функциональнее возможности процессора. И особо бурное применение этого способа приходится на 70-е годы прошлого столетия. Но этот способ имеет недостаток, который заключается в следующем:
Микропрограммное управление позволяет выполнять только одну команду в процессоре, которая монополизирует блок управления, кодом операции, который является вектором вызова конкретной микропрограммы и, пока она не реализуется, переход к выполнению другой не возможен. А требования времени ставили задачу повысить производительность процессора.
Вот тогда и появилось направление RISC архитектуры с жесткой логикой. То есть, эволюция сделала виток, но только жесткая логика была
модернизована и перестала удерживать функциональные блоки в связи, как это было на первоначальном этапе до появления микропрограмм управления, когда метод жесткой логики реализовывал только последовательное выполнение команд, когда текущий код команды управлял всеми комбинационными схемами процессора и распределением управляющих сигналов в течение выполнения команды.
RISC архитектура реализовала конвейерную обработку команд, архитектура в которой функциональные блоки процессора, отвечающие за выполнение этапов команд стали независимы друг от друга, а сами команды упростились, и необходимость в их интерпретации через средства микропрограммного управления отпала сама собой, а жесткая логика взяла на себя функции управления конвейером, устранение конфликтов, выполнение операций в функциональных блоках и реакции на все отклонения в процессе выполнения команд, представляя вышестоящему уровню архитектуры команд через систему прерывания всю информацию для обработки этих отклонений.
В системах имеющих наработанные сложные команды ( INTEL ) пришлось для реализации конвейерной обработки «резать» свои команды на микрооперации, а для команд которые не поддаются разделке аппаратными средствами, хранить микрооперации в отдельной памяти. Но при этом во всех случаях для сохранения зависимости микроопераций одной команды вводить признаки принадлежности их к ней (биты цепочки). В принципе способ микропрограммного управления применим и для конвейерной организации и параллельной обработки. Только для этого каждый функциональный блок должен содержать свою память микропрограммы, а к тому же еще должен быть диспетчер, который отвечает (отслеживает) работу всех блоков. Примером частной реализации этой идеи можем привести архитектуру 1046, в которой был блок акселератора со своей памятью микропрограмм реализующий все операции: деление, умножения, распаковки, упаковки, преобразование десятичной в двоичную систему и наоборот с одновременным выполнением микрокоманд из основной управляющей памяти, давая возможность параллельной работе основного сумматора и другим функциональным блокам по формированию конечного результата в регистр процессора и записи его в память.
Блок микропрограммного управления
1) структура микрокоманды.
Подобно структуре машинной команд имеющих операционную и адресные части, характерные для машин модели Фон-Неймана, блоки микропрограммного управления данного направления оперируют с микрокомандами, имеющих подобную им структуру, то есть микрокоманда состоит из адресной и операционной части. В зависимости от способа кодирования микроопераций, то есть функциональных управляющих сигналов, различают структуры блоков микропрограммного управления:
а) с горизонтальным кодированием; б) с вертикальным кодированием;
в) вертикально-горизонтальным кодированием; г) горизонтально-вертикальным кодированием. 1)Структуры с горизонтальным кодированием
Где каждый разряд операционного поля указывает на наличие 1 или отсутствие 0 микрооперации. Достоинства: возможность одновременного выполнения микроопераций в одном такте. Недостаток: большая разрядность микрокоманд. 2)Вертикальное кодирование Операционное поле представляет двоичный код микрокоманды.
При количестве m разрядов общее число микроопераций =2m. Недостатоквозможно выполнение только одной микрооперации в такте
2*m микроопераций
дешифратор
Поле микроопераций m-разрядов |
Адресное поле |
|
|