

д
ассоциативную память (БбП)
Адреса
начала страничных тадлиц
*8
Физический
адрес
Страничная
тадлица s-го
сегмента
Номера
физических страниц
РгФА
Номер
байта
Номер
физической
страницы
В
ассоциативною память (ВВП f
P(nt$,p)
Сегментная таблица п-й программы
й<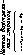
Pfas.p)а)
Номер
программы
Рис.
14.9. Преобразование адресов при
сегментно-страничной организации
памяти:
а—
с использованием таблиц в ОП; б—
с использованием ассоциативной памяти
(блока быстрой переадресации)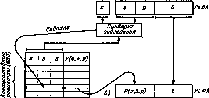
зом страничную таблицу, находящуюся в оперативной памяти. В старшие разряды регистра физического адреса передается новый номер физической страницы, а в младшие — номер байта. Физический адрес сформирован.
Выполняется запрошенное программой обращение к ОП. Одновременно информация о текущей странице (номерах программы, сегмента, виртуальной и соответствующей физической страницы) помещается в сверхоперативную ассоциативную память [или в блок быстрой переадресации (ББП)] небольшой емкости.
Ассоциативная память (ББП) хранит указанные данные для небольшого числа недавно использовавшихся страниц. Так, в ЭВМ ЕС-1045 ББП представляет собой память на интегральных микросхемах емкостью 128 слов с временем выборки 25—30 не [67]. Блок быстрой переадресации может обслуживать одновременно до 3 программ, другими словами, до трех виртуальных памятей.
При наличии ассоциативной памяти (ББП) значительно ускоряется процесс преобразования адресов, так как на каждом участке вычислительного процесса обращения к ОП сосредоточиваются на небольшом числе страниц, и поэтому имеется большая вероятность, что текущее обращение произойдет к странице, информация о которой уже имеется в ассоциативной памяти (ББП), а следовательно, возможно быстрое преобразование адресов без дополнительных обращений к ОП.
Преобразование адресов всегда начинается с просмотра ассоциативной памяти (ББП), и если оказывается, что в одной из ее строк (ассоциативном регистре) хранится информация о странице, к которой должно произойти обращение, то из этой строки непосредственно выбирается номер физической страницы и дополнительные обращения к ОП (к сегментной и страничной таблицам) не производятся (рис. 14.9,6).
Если нужной информации нет в ассоциативной памяти (ББП), то делается попытка сократить время преобразования путем исключения одного дополнительного обращения к ОП (первый этап на рис. 14.9, а). Может оказаться, что страница, к которой происходит обращение, принадлежит сегменту предыдущего обращения к ОП. В аппаратуре преобразования адресов сохраняются номер сегмента и адрес начала его страничной таблицы для предыдущего обращения. Если совпадают номера сегментов текущего и предыдущего обращений, первый этап преобразования исключается, используется сохраненный адрес начала сегментной таблицы и выполняется только второй этап преобразования, т. е. производится только одно дополнительное обращение к ОП. Если номера сегментов не совпадут, реализует - ся полная процедура преобразования адресов, показанная на рис. 14.9, а.
Дополнительные обращения к ОП сопровождаются зане* сением информации о текущей странице в ассоциативную память (ББП). Если в ассоциативной памяти (ББП) не оказывается свободного регистра (строки), данные о новой странице записываются на место данных, которые дольше других не использовались в процессе преобразования адресов.
Алгоритмы управления многоуровневой памятью
Будем рассматривать двухуровневую память со страничной организацией, состоящую из оперативной (верхний уровень) и внешней (нижний уровень) памятей.
Если при выполнении программы обнаруживается, что страница с нужными данными (операндами, куском программы) отсутствует в памяти верхнего уровня, она передается туда из памяти нижнего уровня. Если при этом в памяти верхнего уровня нет для нее свободного места, то она замещает одну из страниц, находящихся в ОП. При этом, если в замещаемую страницу во время ее пребывания в ОП производилась запись, она должна быть передана в память нижнего уровня (заменит там свою устаревшую копию).
Эти операции передачи информации между уровнями памяти вызывают простои процессора и, следовательно, потери производительности вычислительной системы. Поэтому следует стремиться уменьшить число таких операций в процессе выполнения программы. Очевидно, что число этих операций обмена информацией зависит от того, какая информация отсылается из памяти верхнего уровня, так как к этой информации возможно обращение в процессе дальнейшего выполнения программы.
Приведем формализованную модель процесса обмена информацией между верхним и нижним уровнями памяти [10].
Пусть программа вместе с исходными данными состоит из к страниц, которым присвоены номера 1, 2, ..., k, тогда программу можно рассматривать как множество страниц
Q —П. 2,к].
Все страницы программы постоянно хранятся в памяти нижнего уровня, а кроме того, г из них могут находиться в памяти верхнего уровня (оперативной памяти), при этом
1 < г<k.
Выполнение программы порождает последовательность обращений к страницам памяти. Рассматриваем эту последовательность как реализацию некоторого случайного процесса
<7о> Я\у <72» • • •» Qt* где qt — случайная дискретная величина, принимающая в момент времени t значение одного из номеров страниц программы (<7<seQ).
Если St — совокупность страниц в памяти верхнего уровня в момент t, причем в любой момент в этой памяти присутствует г страниц программы, то изменение состояния памяти верхнего уровня после обращения qt описывается следующими соотношениями:
_/S„ если qt<=S,\
'+• \S, — vt + qt, если q^S,.
В первом случае обращение производится к странице, которая находится в памяти верхнего уровня, и поэтому состояние этой памяти не меняется.
Во втором случае происходит обращение к странице, отсутствующей в памяти верхнего уровня. Эта ситуация называется страничным сбоем, так как программа не может дальше выполняться, пока нужная страница qt не будет переписана из памяти нижнего уровня в память верхнего уровня, что сопряжено с потерями времени. Поскольку в памяти верхнего уровня нет свободного места, из нее приходится удалять некоторую страницу гн> с тем чтобы на ее место можно было поместить страницу qt. Если во время пребывания страницы vt в памяти верхнего уровня в нее производилась запись, эта страница при замещении должна переписываться в память нижнего уровня. Такая процедура называется процессом замещения страниц, а правило, по которому при возникновении страничного сбоя выбирается страница Vt^St для удаления из памяти верхнего уровня,— алгоритмом замещения.
Для данной программы, порождающей некоторый поток обращений к памяти, существует по крайней мере одна такая последовательность замещений страниц, которая дает минимальное для этой программы число^траничных сбоев — минимально возможную последовательность замещений. При конструировании алгоритма замещений стремятся приблизить реализуемую этим алгоритмом последовательность замещений к минимальной.
Оптимизация процесса замещений страниц упрощается, если известно, в каком порядке в будущем будут происходить обращения к памяти или, по крайней мере, вероятности обращений в будущем к отдельным страницам программы. Ясно, например, что в первую очередь из памяти верхнего уровня следует удалить страницу, к которой обращений больше не будет (вероятность обращений в будущем равна 0).
Трудность состоит в том, что, как правило, при выполнении программы отсутствуют информация о потоке обращений или сколько-нибудь достоверные сведения о вероятности обращений к отдельным страницам в будущие моменты времени.
Алгоритмы замещения можно разделить на две группы:
физически нереализуемые, использующие информацию (реально отсутствующую) о потоке обращений в будущие моменты времени;
физически реализуемые или эвристические, использующие только информацию об обращениях к памяти в прошедшие моменты времени, т. е. только историю процесса.
Хотя алгоритмы первой группы на практике применить нельзя, они играют важную роль в теории алгоритмов замещения, позволяя производить оценки (в том числе экспериментальные), в какой степени характеристики эвристических алгоритмов приближаются к предельно возможным оптимальным.
Физичёрки нереализуемые алгоритмы. Алгоритм Михновско- го — Шора *. При каждом замещении страницы из памяти верхнего уровня отсылается в память нижнего уровня страница, очередное обращение к которой произойдет позже, чем к любой другой странице в памяти верхнего уровня.
Справедливо следующее предложение. Число замещений страниц в памяти верхнего уровня (число страничных сбоев) при выполнении замещений по алгоритму Михновского — Шора является минимальным для заданных потока обращений и исходного распределения памяти.
Доказательство справедливости предложения можно найти в [39].
Таким образом, алгоритм Михновского — Шора реализует минимально возможную для данной программы последовательность замещений. Поэтому этот алгоритм называют МИ [[-алгоритмом.
Если условиться, что известна вероятность обращений к отдельным страницам программы, то оптимальным в смысле минимума среднего числа страничных сбоев является ОПТ-алгоритм: при каждом замещении страницы из памяти верхнего уровня
1Алгоритм и доказательство его оптимальности впервые опубликованы С. Д. Михневским и Н. 3. Шором в 1965 г. [39]. В литературе часто этот алгоритм приписывают американскому автору Беледина основании его статьи, опубликованной в 1966 г.
отсылается страница, вероятность обращения к которой не больше, чем к любой другой странице в этой памяти.
Физически реализуемые (эвристические) алгоритмы замещения. Был предложен ряд алгоритмов этого класса.
Алгоритм случайного замещения (СЗ-алгоритм). При возникновении страничного сбоя из памяти верхнего уровня с равной вероятностью отсылается любая из находящихся там страниц.
ИДИ-алгоритм. Из памяти верхнего уровня отсылается страница, наиболее давно использовавшаяся.
Алгоритм «первый пришел — первый ушел» (ПППУ-алго- ритм). Отсылается страница, дольше других находившаяся в памяти верхнего уровня.
Алгоритм «последний пришел — первый ушел». Отсылается страница, позже других поступившая в память верхнего уровня.
Следующие два алгоритма обладают определенными свойствами адаптации к потоку обращений к памяти.
Алгоритм «карабкающаяся страница» (КС-алгоритм). Страницы в памяти верхнего уровня образуют последовательность (рис^ 14.10)
$t = j1» 7*2» * * *•» /т —1» /т»7т+1* •**» /г»
которая при очередном обращении qt к памяти изменяется по правилу
{S, при ?,=/,;
/р /2. •••. /». /т-1/гПРИ4t=L'
/р /2 /V— I• я, при qt<£St.
При обращении к странице /ш, присутствующей в памяти верхнего уровня, последняя меняется местами с соседней слева страницей, другими словами, «карабкается» к началу последова-
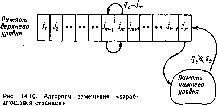
тельности, подальше от ее конца, куда происходит замещение при страничном сбое.
Алгоритм «рабочий комплект» (РК-алгоритм). Страницы в памяти верхнего уровня, использовавшиеся в течение заданно* го интервала времени, образуют «рабочий комплект». Страницы из этой памяти, не вошедшие в «рабочий комплект», формируют две очереди кандидатов на замещение: 1) очередь страниц, в которые не вносились изменения,, пока они присутствовали в памяти верхнего уровня; 2) очередь страниц, в которые вносились изменения. Замещение при страничном сбое производится по правилу: первый пришел из рабочего комплекта — первый ушел из памяти верхнего уровня, при этом сначала подлежат замещению страницы из первой очереди.
Формирование указанных очередей производится с использованием ключа защиты, расширенного дополнительными разрядами Об и Из (см. рис. 14.4), устанавливаемыми в 1, если соответственно происходит любое обращение к данному блоку (странице) и если в него произведена запись. Описанный алгоритм применен в ЕС ЭВМ.
Предположим, что последовательность обращений qi, qi, ..., qt соответс+вует последовательности независимых случайных дискретных величин, таких, что
k
P{4,=i)=pr К/<*. Y.pi=i‘
/=i
Примем за состояние процесса замещения набор (а в некоторых случаях упорядоченную последовательность) страниц, находящихся в памяти верхнего уровня. Тогда для ряда алгоритмов замещения (СЗ, ИДИ, ПППУ и некоторых других) процесс изменения состояния верхнего уровня описывается однородной конечной эргодической цепью Маркова, что указывает на существование стационарных вероятностей пребывания процесса в определенных состояниях и, как следствие этого, стационарных вероятностей страничных сбоев.
В качестве критерия эффективности Wr,k алгоритма замещения А примем стационарную вероятность страничных сбоев
Wf'k{A)= hm P[qt<£S').
/—► оо
Можно для ряда алгоритмов замещения найти зависимость Wr,k от р\, р2, ..Pk и сравнить алгоритмы между собой и также с физически нереализуемым ОПТ-алгоритм ом. Определить Wr,k для ряда алгоритмов можно, использовав метод, основанный на однородных эргодических цепях Маркова [10J.
Быстрое развитие микропроцессорных средств и форсированное улучшение характеристик основанных на их использовании персональных компьютеров, микроЭВМ, супермини- и супермикроЭВМ заставляет задуматься о будущем машин общего назначения и возможных тенденциях их развития.
Обусловленные в значительной степени универсальностью назначения сложность программного обеспечения основных моделей ЕС ЭВМ, их громоздкость, сложность технического обслуживания стимулируют переориентацию пользователя (если его задачи это позволяют) на использование профессиональных персональных компьютеров, мини- и микроЭВМ.
Однако непрерывное усложнение подлежащих решению задач, возрастание требований к производительности машин, точности вычислений, объемам хранимой и обрабатываемой информации диктуют необходимость развития ЭВМ общего назначения в направлении создания предназначенных для широкого использования мощных ЭВМ общего назначения (суперЭВМ общего назначения) с-производительностью 50—100 млн. операций/с, реализующих эффективные режимы общения с пользователем, обладающих многочисленным и разнообразным периферийным оборудованием и системой ввода-вывода большой пропускной способности. Эти машины должны иметь повышенную надежность и живучесть, содержать в своем составе эффективные средства поддержки эксплуатационного обслуживания.
Имеется существенное обстоятельство, которое, с одной стороны, поддерживает ориентацию пользователя на машины общего назначения, а другой — вносит ограничения на решения, направленные на их развитие.
Этим обстоятельством является огромное накопленное в стране программное обеспечение для этих машин, оцениваемое суммой в несколько миллиардов рублей. Поэтому при развитии машин общего назначения ЕС ЭВМ приходится учитывать необходимость сохранения возможности использования имеющегося программного обеспечения, т. е. необходимость обеспечивать архитектурную, в том числе программную совместимость новых моделей с предыдущими моделями этих машин.
В архитектуре машин общего назначения достигнут высокий уровень международной унификации, который в дальнейшем следует сохранить, так как это создает условия для международного сотрудничества в создании программных продуктов.
Сказанное диктует, по меньшей мере на ближайший период, эволюционный путь развития архитектуры машин общего на
значения, но не ставит ограничений в отношении самой технологии реализации их архитектурных свойств.
При значительном росте производительности затрудняется сбалансирование пропускных способностей процессорной части, памяти, системы ввода-вывода и самих внешних ЗУ. Наряду с увеличением быстродействия потребуется значительное увеличение емкости физической ОП и виртуальной памяти, а следовательно, и разрядности адреса. Увеличение длины адреса, например, до 31 разряда позволит увеличить виртуальное адресное пространство машины до 231 байт (2 Гбайт). В структуре памяти может появиться больше уровней с увеличением размера информационных единиц, используемых при обменах между промежуточными уровнями ОП. Должны увеличиться емкость и быстродействие различных буферных памятей/
Для увеличения пропускной способности системы ввода- вывода придется увеличить число каналов ввода-вывода до нескольких десятков. Д;Гя полного освобождения средств процессора от управления операциями ввода-вывода и от использования его аппаратуры в рабочих процедурах каналов понадобится создать функционально развитые процессоры ввода-вывода («директора каналов»).
Для достижения указанной выше производительности следует продолжать уменьшать продолжительность такта процессора, применяя более быстродействующие БИС, искать конструктивные решения по отводу тепла от электронной аппаратуры. Но одно это не решит проблему повышения производительности машины. Будущие ЭВМ общего назначения будут представлять собой вычислительные системы, содержащие несколько взаимодействующих процессоров универсального и специализированного (для определенных типов вычислений) назначений.^
В процессорах будет широко использоваться конвейеризация обработки команд и операций над операндами. Их аппаратура будет включать в себя средства для выполнения векторных операций, а система команд пополнится векторными командами.
ЭВМ общего'назначения приобретут много черт, которые недавно приписывались лишь вычислительным системам сверхвысокой производительности (см. гл. 15).
Развитие ЭВМ общего назначения, конечно, не может пройти мимо существующей тенденции интеллектуализации средств вычислительной техники, которая связана с реализацией средствами ЭВМ все более сложных функций и процессов обработки информации и существенного упрощения общения человека с машиной при подготовке и решении задач.
Все в большей степени функции операционных систем будут «погружаться» в аппаратуру, машины будут снабжаться программно-аппаратурными средствами поддержки крупных баз данных, организации баз знаний, реализации на их основе крупных экспертных систем.
Что касается облегчения общения человека с машиной, то реализация таких средств и функций, как речевой ввод и вывод, системы общения на естественном языке, обучающие и поддерживающие работу пользователя на машине, по-видимому, будет возложена на интеллектуальные терминалы машин общего назначения, построенные на основе персональных компьютеров.
В качестве иллюстрации к высказанным выше соображениям рассмотрим новую модель машины общего назначения — систему 3090/400 фирмы IBM, являющейся в мировой технике ведущей в области машин рассматриваемого класса [86].
В машине IBM 3090 использованы или получили развитие некоторые схемные и архитектурные решения, впервые осуществленные в непосредственно ей предшествующих моделях ЭВМ фирмыIBM. Так, организация каналов ввода-вывода заимствована из ЭВМIBM 370 ХАI[70], организация векторных операций является развитием векторных средств, использованных вIBM 370 ХА иIBM 3033, в организации кэш-памяти критически осмыслен опыт, полученный при разработкеIBM 3080.
Схемотехника ЭВМ IBM 3090основана на применении специализированных БИС, содержащих до 704 вентильных схем ЭСЛ. По сравнению с использовавшимися вIBM 3080 БИС примерно с подобным же числом схем ТТЛ БИСIBM 3090 не только обладают большим быстродействием, но и, что важно, имеют парафазные сигналы на выходах, позволяющие отказаться от дополнительных схем инвертирования сигналов. На этих же кристаллах удается разместить умощнители выходных сигналов, для которых вIBM 3080 требовались отдельные интегральные микросхемы.
В результате схемотехника IBM 3090 позволила снизить продолжительность такта до 18,5 не, в то время как вIBM 3080 она составляла 26—24 не, а вIBM 3033, построенной на фиксированном наборе кристаллов, достигала 57 не.
Увеличение степени интеграции и компактности оборудования машины достигнуто конструкторскими решениями, основанными на использовании теплопроводящих модулей (ТСМ), содержащих до 100 БИС. В свою очередь, модули по 6 и 9 шт. располагаются на панелях. Таким образом, исключается существовавший в предыдущих моделях ЭВМ Платовым (ТЭЗовый) уровень конструкции. Значительные трудности представляет отвод тепла от электронной аппаратуры. МодульIBM 3090 потребляет около 500 Вт. В теплопроводящем модуле это решается применением прилегающей к корпусам кристаллов наполненной гелием металлической камеры в сочетании с водяным охлаждением.
Общее число электронных схем в IBM 3090 достигает 300 тыс. Разработка такой машины потребовала использования мощной системы автоматизации проектирования, включая систему потактового моделирования.
Структура машины IBM 3090/400представлена на рис. 14.11. Модель 3090/400 состоит из двух двухпроцессорных машинIBM 3090/200, имеющих каждая свою центральную (оперативную) и расширенную памяти, свою канальную систему.
Взаимодействием основных устройств каждой из машин 3090/200 управляют их блоки управления системой (БУС). Связь между машинами 3090/200 осуществляется по шинам, соединяющим их блоки управления системой и их расширенные памяти.
Новый эффективный структурный элемент — расширенная память емкостью несколько сотен мегабайт и более — не является дополнительной центральной памятью. Ее основное назначение — служить буферной памятью между ОП и дисковыми ЗУ для компенсации большого времени доступа и сравнительно низкой скорости передачи данных в этих устройствах, могущих вызвать значительные простои в работе процессора. Благодаря расширенной памяти пропускная способность внешних ЗУ увеличивается (виртуально по отношению к процессору) в несколько сотен раз. В расширенной памяти адресуемой и участвующей под управлением операционной системы в обмене с центральной памятью единицей информации является 4-килобайтная страница. Это облегчает адресацию памяти большой емкости.
ОП
Центральная 0П Раси1иренная память Центральная