

\Нвт
во
сстановление состояния процессор^
Сброс
флажка О.
Выполнение
прерывающей программы (передача банных
для устройства О)
Сброс
флажка 1.
Выполнение
прерывающей программы (передача данных
для устройства 1)
Сброс
флажка 2. Выполнение прерывающей
программы (передачи данных для устройства
2)
Сброс
флажка к.
Выполнение
прерывающей программы (передачи данных
для устройства к)
Запоминание состояния процессора (программы)
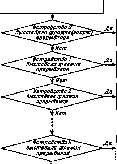
а)
Разрешениеf
прерывания
j
>i
Д
Компаратор
М В)
Одщий
сигнал прерывания
_
*-pv
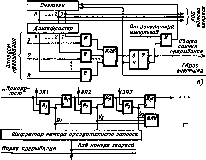
разрядов регистра запросов прерывания) производится последовательно (циклически) с помощью /г-разрядного счетчика (2Л^ на который с некоторой частотой поступают импульсы от генератора. Поиск приоритетного запроса прерывания начинается со сброса сГЧетчика и одновременно триггера Т в нулевое состояние, при этом импульсы генератора начинают поступать на вход счетчика. При помощи дешифратора и элементов И в каждом такте поиска проверяется наличие запроса прерывания, номер которого совпадает с кодом счетчика. Если на данном входе нет запроса прерывания, то после прибавления 1 к счетчику проверяется следующий по порядку вход. Если имеется запрос, триггер Т перебрасывается в 1, при этом в процессор посылается общий сигнал прерывания ОСП и прекращается поступление импульсов на вход счетчика, т. е. завершается цикл просмотра входов системы прерывания. Содержимое счетчика — код номера старшего по приоритету выставленного запроса — используется для формирования начального адреса прерывающей программы. После передачи управления прерывающей программе счетчик (и триггер Т) сбрасывается в 0, и процедура опроса запросов возобновляется, начиная с первого входа.
Циклический (последовательный) опрос входов системы прерывания в аппаратурном отношении сравнительно прост, однако время реакции и при этом методе все-таки велико, особенно при большом числе источников запросов. Поэтому во многих случаях, например в ряде микропроцессоров, предназначенных для использования при работе в реальном времени, применяют схемы, позволяющие определять номер выставленного запроса или уровня прерывания старшего приоритета за один такт.
Цепочечная однотактная схема определения приоритетного зйпроса («дейзи-цепочка») представлена на рис. 9.27, в. Как и в предыдущих случаях, приоритет запросов прерывания возрастает с уменьшением их номера.
Процедура определения приоритетного запроса инициируется сигналом Приоритет, поступающим на цепочку последовательно включенных схем И. При отсутствии запросов этот сигнал пройдет через цепочку и сигнал общего запроса прерывания не сформируется. Если среди выставленных запросов прерывания наибольший приоритет имеет i-Pi запрос, то распространение сигнала Приоритет правее схемы И с номером i блокируется. На i-м выходе цепочечной схемы будет сигнал t//= 1, на всех других
В процессор поступит общий сигнал прерывания, при этом шифратор по сигналу yL = 1 сформирует код номера i-го запроса, принятого к обслуживанию. По сигналу процессора Подтверждение прерывания (на рис. 9.27 не показан) этот код передается в процессор и используется для формирования начального адреса прерывающей программы.
Схемы, представленные на рис. 9.27, б ив, производят поиск крайней левой единицы в наборе сигналов прерывания и формируют код номера i запроса, удовлетворяющего условию
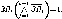
Векторное прерывание
Представленные на рис. 9.27 способы определения запроса с наибольшим приоритетом включают в себя так или иначе выполняемую процедуру опроса источников прерывания (входов системы прерывания). Эта процедура, даже если она выполняется аппаратурными средствами, требует сравнительно больших временных затрат.
Более гибким и динамичным является векторное прерывание, при котором исключается опрос источников прерывания (флажков регистра прерывания).
Прерывание называется векторным, если источник прерывания, выставляя запрос прерывания, посылает в процессор (выставляет на шины интерфейса) код адреса в памяти своего вектора прерывания.
Отметим, что если прерывание на основе опроса источников прерываний всегда сопровождается переходом по одному и тому же адресу и инициирует одну и ту же прерывающую подпрограмму, которая после идентификации источника запроса и формирования адреса начала соответствующей запросу прерывающей программы передает ей управление, то при векторном прерывании каждому запросу прерывания, или, другими словами, устройству — источнику прерывания, соответствует переход к начальному адресу соответствующей прерывающей программы, задаваемому вектором прерывания.
Программно-управляемый приоритет прерывающих программ
Относительная степень важности программ, их частота повторения, относительная степень срочности в ходе вычислительного процесса могут меняться, требуя установления новых приоритетных отношений. Поэтому во многих случаях приоритет между прерывающими программами не может быть зафиксирован раз и навсегда. Необходимо иметь возможность изменять по мере надобности приоритетные соотношения программным путем, другими словами, приоритет между прерывающими программами должен быть динамичным, т. е. программно-управляемым.
В ЭВМ широко применяются два способа реализации программно-управляемого приоритета прерывающих программ, в которых используются соответственно порог прерывания (в малых и микроЭВМ) и маски прерывания (в ЭВМ общего назначения).
Порог прерывания. Этот способ позволяет в ходе вычислительного процесса программным путем изменять уровень приоритета процессора (а следовательно, и обрабатываемой в данный момент на процессоре программы) относительно приоритетов запросов источников прерывания (в основном периферийных устройств), другими словами, задавать порог прерывания, т. е. минимальный уровень приоритета запросов, которым разрешается прерывать программу, идущую на процессоре.
Порог прерывания задается командой программы, устанавливающей в регистре порога прерывания код порога прерывания. Специальная схема выделяет наиболее приоритетный запрос прерывания, сравнивает его приоритет с порогом прерывания и, если он оказывается выше порога, вырабатывает общий сигнал прерывания, и начинается процедура прерывания (рис. 9.27, в).
В современных ЭВМ общего назначения наибольшее распространение получило программное управление приоритетом на основе маски прерывания (рис. 9.28).
Маска прерывания представляет собой двоичный код, разряды которого поставлены в соответствие запросам или классам прерывания. Маска загружается командой программы в регистр маски. Состояние 1 в данном разряде регистра маски разрешает, а состояние 0 запрещает (маскирует) прерывание текущей программы от соответствующего запроса. Таким образом, програм-
Эалросы
прерывания
А