

Ольков_С_Г_Аналитическая юриспруденция
.pdfединицами, отнесенными к одной группе, должны быть меньше, чем между единицами, отнесенными к разным группам.
Диаграмма Парето (Pareto diagram) – это аналитический инструмент, содержащий в себе абсолютные и относительные величины, ранжированный от максимума к минимуму вариационный ряд исследуемого показателя, а также кумулятивную кривую, показывающую накопление процента и абсолютного значения при движении изучаемого показателя вдоль ранжированного ряда от максимума к минимуму.
Дисперсия (variance, dispersion) – показатель разброса относительно среднего (для генеральной совокупности – относительно математического ожидания), используемый для вычисления более удобной меры разброса – стандартного отклонения.
Дифференциальное исчисление – вычисления связанные с нахождением производных функций (производных от первообразных – интегральных или совокупных функций).
Изнасилование (rape)43 – половое сношение с применением насилия или с угрозой его применения к потерпевшей или к другим лицам либо с использованием беспомощного состояния потерпевшей.
Интегральное исчисление – вычисления связанные с нахождением первообразных, совокупных функций.
Кластер происходит от английского: cluster – сгусток, пучок, группа.
Кластерный анализ – группа статистических методов объединяющего (агломеративные методы) или разделяющего (дивизимные методы) типа, позволяющих проводить классификацию исследуемых объектов с учетом всех закладываемых группировочных признаков одновременно, строить наглядные карты и дендрограммы, анализировать полученные кластеры.
42Елисеева И.И., Юзбашев М.М. Общая теория статистики: Учебник/Под ред. И.И. Елисеевой. – 5-е изд., перераб. и доп. – М.: Финансы и статистика, 2004. С. 172.
43«Международное определение»: rape means sexual intercourse without valid
consent (изнасилование означает половое сношение без реального согласия).
102

Коэффициент аппроксимации – во временных рядах показывает качество аппроксимации, то есть отвечает на вопрос, насколько хорошо подобрано оценочное регрессионное уравнение. Чем ближе к единице коэффициент аппроксимации, тем точнее оценочное уравнение аппроксимирует эмпирические данные.
Коэффициент вариации (variation coefficient) – эффективная мера разброса, вычисляется путем деления стандартного отклонения на среднее временного или пространственного ряда. Обычно выражается в процентах, то есть результат деления
умножается на 100: Vσ= σy ×100 .
Коэффициент виктимизации преступлений (первой, второй и третьей степени) (victimization of crime coefficient (first
degree, second degree, third degree )): КВП = VVc , КBП – коэффициент
виктимизации конкретной демографической группы, V – доля данной демографической группы во всем населении на
исследуемой территории за исследуемый период времени: V = QQc ,
где Q – зарегистрированная абсолютная общая численность народонаселения в данное время в данном месте, Qc – зарегистрированная численность исследуемой демографической группы в то же время и в том же месте; Vc – доля зарегистрированных потерпевших от преступлений физических лиц из данной демографической группы в общем числе выявленных лиц, совершивших преступления в данное время в данном месте:
Vс = ggc , где g – абсолютное число зарегистрированных потерпевших
от преступлений физических лиц на данной территории за данное время; gc – абсолютное число зарегистрированных потерпевших из данной демографической группы за то же время в том же месте.
Коэффициент гражданско-правовой активности: КГПА = PPc
, где КГПА – коэффициент гражданско-правовой активности, P – доля данной демографической группы во всем населении исследуемого региона, Pc – доля лиц из данной демографической группы, заключившая соответствующие гражданско-правовые договоры в числе лиц, заключивших такие договоры.
103

Коэффициент криминогенной пораженности: ККП = |
Dc , |
|
D |
ККП – коэффициент криминогенной пораженности конкретной демографической группы, D – доля данной демографической группы во всем населении на исследуемой территории за
исследуемый период времени: D = QQc , где Q – абсолютная общая
численность народонаселения в данное время в данном месте, Qc – численность исследуемой демографической группы в то же время и
втом же месте; Dс – доля выявленных лиц из данной демографической группы, совершивших преступления, в общем числе выявленных лиц, совершивших преступления в данное время
вданном месте: Dс = qqc , где q – абсолютное число выявленных лиц,
совершивших преступления на данной территории за данное время; qс – абсолютное число выявленных лиц, совершивших преступления из данной демографической группы за то же время в том же месте.
Коэффициенты нагрузки экономически активного населения осужденными к лишению свободы приведенный на
1000 тыс. человек: КНО = |
RОсужд |
×1000 |
, где RОсужд |
– число |
|
|
|
|
|
|
R15 −54 (59 ) |
|
|
|
осужденных к лишению свободы; R15-59 – численность населения в возрасте от 15 до 59 лет.
Коэффициент опережения – показывает отношение текущих
и предшествовавших им темпов роста |
Тр ц |
i |
. |
|
Тр ц |
|
|
||
|
|
i −1 |
||
Коэффициент осцилляции – мера разброса (менее эффективная чем коэффициент вариации). Вычисляется путем
деления размаха на среднее значение вариационного ряда: VR= Ry ×100
.
Коэффициент преступности (crime coefficient) или её структурной составляющей – вычисляется по формуле: КП= Nу ×100000 ,
где КП – коэффициент преступности, у – число преступлений за определенный временной период на данной территории, шт., N – численность населения на той же территории за то же время –
104
количество человек (можно брать все население на данной территории или какую-то его часть, скажем, достигшую возраста, с которого наступает уголовная ответственность).
Коэффициент регрессии (regression coefficient) – первая производная или коэффициент при независимой переменной в оценочном регрессионном уравнении, по сути, показывает отношение абсолютных приростов и отвечает на вопрос, насколько в абсолютном выражении изменится зависимая переменная при изменении независимой на единицу измерения.
Коэффициент эластичности (elasticity coefficient) – отвечает на вопрос, насколько процентов изменится независимая переменная при изменении независимой на 1%.
Математическое ожидание (еxpected value) – среднее в генеральной совокупности.
Медиана (median) – число, разделяющее ранжированную выборку или ГС пополам. То есть 50% выборочных данных меньше медианного значения, и 50% - больше медианы.
Меры центральной тенденции показывают центр тяжести исследуемого вариационного ряда, «центростремительность» его элементов. Сюда относятся различные виды математических ожиданий и средних, мода, медиана.
Меры разброса (вариации) – демонстрируют силу центробежных процессов, степень удаления элементов от центра. Сюда относятся размах, дисперсия, среднее квадратическое отклонение, коэффициент осцилляции, коэффициент вариации.
Мода (mode) – число (для количественных данных) или категория (для качественных данных), которые наиболее часто встречается в наборе данных.
Мошенничество (fraud) – хищение чужого имущества или приобретение права на чужое имущество путем обмана или злоупотребления доверием.
Относительная плотность распределения – это частость,
приходящаяся на единицу длины интервала: yi = whi , где yi –
i
относительная плотность распределения, wi – частоcть, hi – длина интервала.
105

Оценочное регрессионное уравнение (regression equation) – это линейное или нелинейное уравнение, от одной или нескольких независимых переменных, аппроксимирующие исходные эмпирические данные. Обычно используется для прогнозирования значений зависимой (управляемой) переменной.
Полигон (polygon) распределения частот (частостей) – это график, на котором в качестве независимой переменной (абсцисса) представлены значения случайной переменной X, а в качестве зависимой (ордината) – значения соответствующих им частот или частостей.
Приведение рядов к одному основанию – это, во-первых, перевод уровней ряда соответствующих вариационных рядов в относительные величины (проценты, доли или коэффициенты); вовторых, их приведение к единой базе, то есть к уровню какого-либо периода (или иного основания) принятого за базовый.
Производная (derivative) (первая) – в простой линейной функции отвечает на вопрос, насколько в абсолютном выражении изменится зависимая переменная при изменении независимой на единицу измерения. derivation
Пространственный вариационный ряд – это вариационный ряд какой-либо переменной взятой по различным наблюдаемым объектам за один и тот же фиксированный отрезок времени.
Разбой (assault)44 – нападение в целях хищения чужого имущества, совершенное с применением насилия, опасного для жизни или здоровья, либо с угрозой применения такого насилия.
Размах вариационного ряда (range) – разница между максимальным и минимальным значениями вариационного ряда.
Свободный член (intercept) оценочного регрессионного уравнения – показывает значение функции (зависимой переменной)
44 «Международное определение»: assault means physical attack against body of another person resulting in serious injury, excluding indecent/sexual assault; threat and slapping/punching. Assault leading to death should also excluded (разбой означает физическое насилие против физического лица, влекущее серьезный физический вред за исключением случаев непристойного поведения, сексуального насилия; угрозы и избиения. Разбой, влекущий смерть, также не включается.
106

при значении независимой переменной в точке нуль. То есть, если независимая переменная равна нулю, то зависимая равна величине свободного члена.
Смыкание временных рядов – это создание единого ряда из нескольких более мелких рядов (двух и более), уровни которых имеют специфику. При этом нужно, чтобы данные переходного периода (один период) были исчислены по двум методологиям – принятым для первого и второго смыкаемых рядов.
Среднее взвешенное (weighted average):
X = N1 |
åxi fi |
|
|
|
|
|||
|
|
|
|
N |
|
|
|
|
|
|
|
|
i=1 |
, где |
|
|
- средняя взвешенная (weighted |
|
|
|
å fi |
|
|
|||
|
|
|
|
|
|
|
X |
|
|
|
|
i=1 |
|
|
|
|
|
average), хi – конкретные значения переменной Х, fi – частоты повторяющихся значений, например, переменная хi встречается n раз.
N
X = åwi xi , где X - средняя взвешенная, wi – доли (веса)
i=1
соответствующих значений переменной Х, сумма долей равна единице. Простое среднее арифметическое также можно рассматривать, как среднее взвешенное с равными весами 1/N.
|
|
|
|
|
|
|
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
Среднее гармоническое |
простое – |
X гарм = |
|
|
|
, где |
|
|
гарм - |
|||||||||||
n |
1 |
|
|
|||||||||||||||||
X |
||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
å |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
i=1 |
i |
|
|
|
||||
среднее гармоническое. |
|
|
|
|
|
|
|
|
||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
Среднее гармоническое взвешенное: |
|
|
|
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
åwi |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
X |
гармВз = |
i=1 |
|
, где |
|
гармВз - средняя гармоническая взвешенная, |
|||||||||||||
|
|
X |
||||||||||||||||||
|
n |
w |
||||||||||||||||||
å |
i |
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
i=1 |
xi |
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
wi =xi∙fi , где f - |
частота встречаемости. |
mean) |
|
|
|
|
|
|
|
|
|
|||||||||
Среднее геометрическое |
(geometric |
простое |
– это |
|||||||||||||||||
корень энной степени из произведения n величин. Вычисляется по
формуле: Х |
= (x × x |
×...× x )n |
= n x × x |
×...× x . |
|||||
|
|
|
|
|
1 |
|
|
|
|
|
|
Г |
1 2 |
n |
|
1 2 |
n |
||
Среднее геометрическое (weighted geometric mean) взвешенное:
|
|
æ |
n |
w |
|
∏xi |
|||
Х Гвз = ç |
i |
|||
|
|
è i=1 |
|
|
1
ö÷åin=1 wi .
ø
107
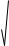
Среднее геометрическое значение нормы прибыли –
вычисляется по формуле:
|
|
|
|
|
1 |
|
|
|
|
||||
|
|
|
= [(1+ R )×(1+ R ) + ...+ (1+ R )]n |
-1, где R – |
норма прибыли за i-й |
||||||||
R |
Г |
||||||||||||
|
|
1 |
2 |
|
|
|
n |
|
|
|
|
||
период времени. |
|
|
|
|
n |
|
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
= |
åхi |
= |
x1 + x2 + ... + xk |
|
|
|
Среднее простое – |
|
Х |
i=1 |
|
|
, где n – объем выборки. |
|||||||
|
n |
n |
|||||||||||
|
|
|
|
||||||||||
Если вычисления проводятся по генеральной совокупности (ГС), то вместо n, берется N – объем генеральной совокупности и вместо выборочного среднего арифметического получается среднее арифметическое для ГС, которое называют математическим ожиданием.
Среднее квадратическое отклонение (стандартное отклонение) (standard deviation (SD)) – корень квадратный из дисперсии, эффективная мера разброса.
Средняя |
ошибка |
аппроксимации (mean error of |
||||||||||
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
= |
1 |
× å |
|
|
yi - yi |
|
|
×100 |
|
|
|
A |
|
||||||||||
|
|
|
|
|||||||||
approximation): |
|
|
n |
i =1 |
|
|
yi |
|
|
|
|
. Показывает качество оценочного |
|
|
|
|
|
|
|
|
|||||
уравнения, насколько оно хорошо подходит к эмпирическим данным. Выражается в процентах, и указывает, насколько процентов в среднем ошибочна оценка. Допустимая средняя ошибка аппроксимации в пределах 8-10%, но, в принципе, чем меньше величина этой ошибки, тем точнее теоретическая кривая подходит к эмпирической, и тем точнее прогноз, полученный на основе оценочного уравнения.
Стандартная ошибка (standard error (SE)) – стандартное отклонение делится на корень квадратный из объема выборки.
Стандартное отклонение ГС (population standard) вычисляется путем извлечения квадратного корня из дисперсии генеральной совокупности.
Степенные средние – обобщающие показатели вариационных рядов, показывающие их «центр тяжести». Средняя степенная
|
|
|
|
n x k |
|
|
|
|
|
|
|
|
|
|
|
||
простая: |
Х = k |
å |
i |
|
, где |
k – показатель степени, изменяющийся в |
||
|
||||||||
|
|
|
|
i=1 n |
|
|
|
|
пределах |
[-1; |
+∞], хi |
– варианты, n – число вариант (число |
|||||
наблюдений или рабочих строк в таблице). Простая средняя
108

степенная применяется, когда веса вариант равны, например, в случае, когда каждая варианта встречается только один раз.
|
|
|
n |
x k × f |
|
|
|
|
|
Средняя степенная взвешенная: Х = k å |
i |
|
, где |
k – показатель |
|||||
i |
|
|
|||||||
|
n |
|
|||||||
|
|
|
i=1 |
|
|
|
|
|
|
степени, хi – варианты, n – число вариант (число наблюдений или рабочих строк в таблице), fi – частота, вес (показатель повторяемости вариант в вариационном ряду). Применяется, когда веса вариант различны по сгруппированным рядам.
Поскольку k – показатель степени, изменяется в пределах [-1; +∞], постольку выделяют среднюю гармоническую, где k=-1, среднюю геометрическую, где k=0, среднюю арифметическую, где k=1, среднюю квадратическую, где k=2, среднюю кубическую, где k=3, среднюю биквадратическую, где k=4.
Существует правило мажорантности: величина степенной средней более высокой степени всегда больше или равна величине средней рассчитанной по формуле с меньшей степенью. То есть средняя гармоническая меньше или равна средней геометрической,
средняя |
геометрическая |
меньше |
или |
равна |
средней |
арифметической и т.д.
Структурные средние используются для исследования внутреннего строения рядов распределения изучаемого признака. Сюда относят: моду, медиану, квартили (делят ранжированный ряд на 4 равные части), децили (делят ранжированный ряд на 10 равных частей), квинтили (делят ранжированный ряд на 5 равных частей), перцентили (делят ранжированный ряд на 100 равных частей).
Темп роста (growth rate) (к базе) – |
бk |
= |
yi |
, где |
у0 |
– значение |
y0 |
принятое за базу.
Темп роста (цепной) – цk = yyi , где yi – каждое последующее
i−1
значение переменной y, yi-1 – каждое предыдущее значение переменной y. В данном случае сравниваемая база принимается равной единице, и мы имеем дело с кратным отношением, отвечающим на вопрос: во сколько раз? База сравнения может быть принята за 100 единиц (темп роста, выраженный в процентах).
109

Соответственно, каждый уровень ряда можно выразить через предыдущий или базисный: yi=бk∙y0 и т.п.
Темп прироста (к базе) – бg= yi y− y0 ×100 .
0
Темп прироста (цепной) – цg= yi y− yi−1 ×100 .
i−1
Тенденция (от лат. tendentia – направленность) – отличное от стационарного течение какого либо процесса.
Тренд (trend) – уравнение, описывающее тенденцию.
Убийство (killing, murder, homicide, assassination) – умышленное причинение смерти другому человеку.
Хулиганство (hooliganism) – грубое нарушение общественного порядка, выражающее явное неуважение к обществу.
Частотный вариационный ряд или ряд распределения – это вариационный ряд, в котором значениям случайной величины, например, преступности, осужденным и т.д. поставлены в соответствие частоты или частости встречаемости.
Эмпирической функцией распределения выборки называется кумулятивная кривая, полученная по частотам (f) или частостям (относительным частотам) (w). Статистическим распределением случайной величины X (распределением изучаемого признака по частотам встречаемости) считаем таблицу значений признака (х), расположенного в возрастающем порядке и соответствующих им значений частот (абсолютная частота) или частостей (относительная частота). То есть статистическое распределение
отвечает на вопрос, как часто встречаются соответствующие значения исследуемого признака расположенного в ранжированном порядке.
Эксцесс (крутость) (kurtosis) – центральный момент четвертого порядка, представляет интерес при изучении частотных вариационных рядов, когда проводится проверка соответствия данного эмпирического распределения теоретическому нормальному распределению (распределению Гаусса). При наличии нормального распределения значение эксцесса равно нулю или близко к нулю. На графике нет вертикального сдвига.
Юридический процесс (juridical process) (от лат. processus –
продвижение) – это движение, изменение, последовательность
110
юридических явлений (событий), их развертывание во времени и пространстве. То есть всякий юридический процесс складывается из юридических явлений, представляет собой их поток, течение во времени и пространстве.
Юридическое явление (юридический феномен) (juridical phenomenon) – это диагностируемое (распознаваемое) как государственно-правовое явление (событие) социального мира.
ОСНОВНЫЕ ТЕРМИНЫ:
Абсолютный прирост, аналитическая криминология (analytical criminology), аналитическая юриспруденция (analytical jurisprudence); асимметрия (скос) (skewness), временной ряд (time series), выброс (outliner), генеральная совокупность (population), гистограмма (histogram), грабеж (robbery), диаграмма Парето (Pareto diagram), дисперсия (variance, dispersion), дифференциальное исчисление, изнасилование (rape) , интегральное исчисление, кластер (cluster), коэффициент аппроксимации, коэффициент вариации, коэффициент виктимизации преступлений первой степени (victimization of crime coefficient (first degree, second degree, third degree)), коэффициент гражданско-правовой активности, коэффициент криминогенной пораженности, коэффициент опережения, коэффициент осцилляции, коэффициент преступности (crime coefficient), коэффициент регрессии (regression coefficient), коэффициент эластичности (elasticity coefficient), математическое ожидание (еxpected value), медиана (median), меры центральной тенденции, меры разброса (вариации), мода (mode), мошенничество (swindling), метод наименьших квадратов (МНК) (ordinary least squares (OLS)), набор данных (data set), одномерный (univariate), оценочное регрессионное уравнение (regression equation), первичные данные (primary data), полигон распределения частот (частостей), производная (derivative), пространственный вариационный ряд (об одном временном срезе) (cross-sectional), разбой (assault), размах вариационного ряда (range) – разница между максимальным и минимальным значениями вариационного
111