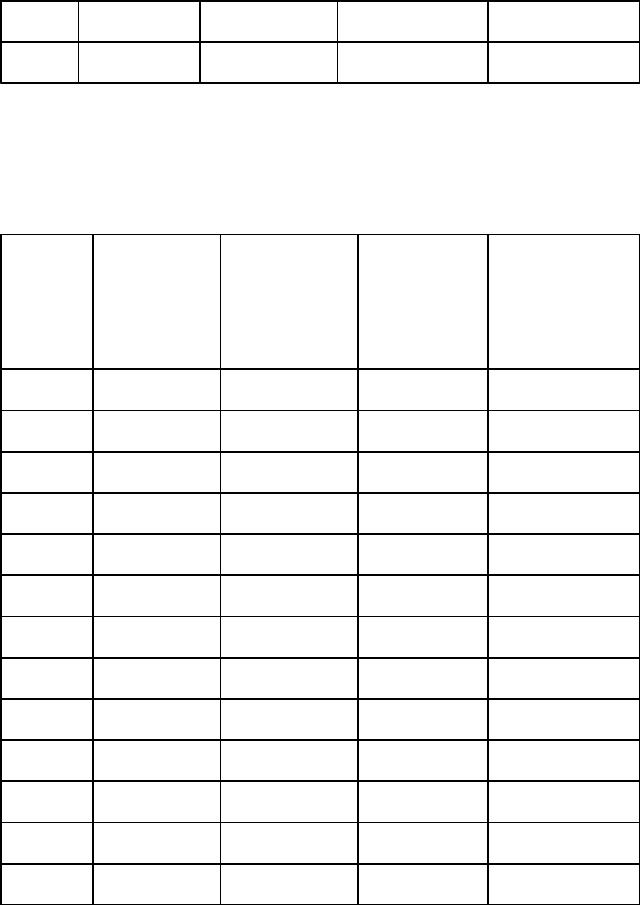
Построим 2 рабочих таблицы: Таблица для группы №1 (n=20).
Время, |
Число |
Наблюдалось |
Доля |
Выживаемость |
мес. |
увольнени |
к началу |
переживших |
S1 (t) |
|
й в месяц t |
месяца |
месяц t |
|
|
|
d1t |
n1t |
f1t |
|
3 |
2 |
20 |
0,9 |
0,9 |
5 |
1 |
18 |
0,944 |
0,849 |
7 |
1 |
17 |
0,941 |
0,799 |
8 |
1 |
16 |
0,937 |
0,749 |
9+ |
1 |
15 |
|
|
11 |
2 |
14 |
0,857 |
0,642 |
13 |
1 |
12 |
0,916 |
0,588 |
15 |
1 |
11 |
0,909 |
0,534 |
16 |
1 |
10 |
0,9 |
0,481 |
20 |
2 |
9 |
0,777 |
0,373 |
21 |
1 |
7 |
0,857 |
0,32 |
24+ |
1 |
6 |
|
|
27 |
1 |
5 |
0,8 |
0,256 |
30+ |
1 |
4 |
|
|
33 |
1 |
3 |
0,666 |
0,17 |
f1t =1− d1t n1t
Таблица для группы №2 (n=17).
Время, |
Число |
Наблюдалось |
Доля |
Выживаемость |
мес. |
увольнений |
к началу |
переживших |
S2 (t) |
|
в месяц t |
месяца |
месяц t |
|
|
|
d2t |
n2t |
f2t |
|
5 |
1 |
17 |
0,941 |
0,941 |
8+ |
1 |
|
|
|
12 |
2 |
15 |
0,866 |
0,815 |
15 |
1 |
13 |
0,923 |
0,752 |
16 |
1 |
12 |
0,916 |
0,688 |
23 |
1 |
11 |
0,909 |
0,626 |
27 |
2 |
10 |
0,8 |
0,501 |
29 |
1 |
8 |
0,875 |
0,438 |
32 |
2 |
7 |
0,714 |
0,313 |
33+ |
1 |
|
|
|
35 |
2 |
4 |
0,5 |
0,157 |
39 |
1 |
2 |
0,5 |
0,07 |
40 |
1 |
1 |
|
|
Рис. Кривые выживаемости для первой и второй группы.
t |
d1t |
n1t |
d2t |
n2t |
dобt |
nобt |
|
|
|
|
|
|
|
|
3 |
2 |
20 |
0 |
17 |
2 |
37 |
|
|
|
|
|
|
|
5 |
1 |
18 |
1 |
17 |
2 |
35 |
|
|
|
|
|
|
|
7 |
1 |
17 |
0 |
17 |
1 |
34 |
|
|
|
|
|
|
|
8 |
1 |
16 |
1 |
17 |
2 |
33 |
|
|
|
|
|
|
|
9+ |
1 |
15 |
0 |
17 |
1 |
32 |
|
|
|
|
|
|
|
11 |
2 |
14 |
0 |
17 |
2 |
31 |
|
|
|
|
|
|
|
13 |
1 |
12 |
0 |
17 |
1 |
29 |
|
|
|
|
|
|
|
12 |
0 |
12 |
2 |
15 |
2 |
27 |
|
|
|
|
|
|
|
15 |
1 |
11 |
1 |
13 |
2 |
24 |
|
|
|
|
|
|
|
16 |
1 |
10 |
1 |
12 |
2 |
22 |
|
|
|
|
|
|
|
20 |
2 |
9 |
0 |
12 |
2 |
21 |
|
|
|
|
|
|
|
21 |
1 |
7 |
0 |
12 |
1 |
19 |
|
|
|
|
|
|
|
23 |
0 |
7 |
1 |
11 |
1 |
18 |
|
|
|
|
|
|
|
24+ |
1 |
6 |
0 |
11 |
1 |
17 |
|
|
|
|
|
|
|
27 |
1 |
5 |
2 |
10 |
3 |
15 |
|
|
|
|
|
|
|
29 |
0 |
5 |
1 |
8 |
1 |
13 |
|
|
|
|
|
|
|
30+ |
1 |
4 |
0 |
8 |
1 |
12 |
|
|
|
|
|
|
|
32 |
0 |
4 |
2 |
7 |
2 |
11 |
|
|
|
|
|
|
|
33 |
1 |
3 |
1 |
7 |
|
2 |
10 |
|
|
|
|
|
|
|
|
34+ |
1 |
2 |
0 |
7 |
|
1 |
9 |
|
|
|
|
|
|
|
|
35 |
0 |
2 |
2 |
4 |
2 |
|
6 |
|
|
|
|
|
|
|
|
39 |
0 |
2 |
1 |
2 |
|
1 |
4 |
|
|
|
|
|
|
|
|
40 |
1 |
1 |
1 |
1 |
|
2 |
2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
dобt |
=d1t +d2t |
|
nобt |
= n1t +n2t |
|
|
|
Слагаемые |
E1t |
d1t −Е1t |
для СТО32 |
|
|
|
1,081081 |
0,918919 |
0,482915 |
|
|
|
1,028571 |
-0,02857 |
0,484898 |
|
|
|
|
0,5 |
|
0,5 |
0,25 |
|
|
|
0,969697 |
0,030303 |
0,48393 |
|
|
|
0,46875 |
0,53125 |
0,249023 |
|
|
|
0,903226 |
1,096774 |
0,478807 |
|
|
|
0,413793 |
0,586207 |
0,242568 |
|
|
|
0,888889 |
-0,88889 |
0,474834 |
|
|
|
0,916667 |
0,083333 |
0,47494 |
|
|
|
0,909091 |
0,090909 |
0,472255 |
|
|
|
0,857143 |
1,142857 |
0,465306 |
|
|
|
0,368421 |
0,631579 |
0,232687 |
|
|
|
0,388889 |
-0,38889 |
0,237654 |
|
|
|
0,352941 |
0,647059 |
0,228374 |
|
|
|
|
1 |
|
0 |
0,571429 |
|
|
|
0,384615 |
-0,38462 |
0,236686 |
|
|
|
0,333333 |
0,666667 |
0,222222 |
|
|
|
0,727273 |
-0,72727 |
0,416529 |
|
|
|
|
0,6 |
|
0,4 |
0,373333 |
|
|
|
0,222222 |
0,777778 |
0,17284 |
|
|
|
0,666667 |
-0,66667 |
0,355556 |
|
|
|
|
0,5 |
|
-0,5 |
0,25 |
|
|
|
|
1 |
|
0 |
0 |
|
|
|
|
32 СТО – стандартное отклонение.

U L = |
S 2 |
= |
UL |
|
4,518731 |
7,856786 |
SU L =2,802996 
E1t = n1t × dnобt ; обt
N
UL = å(d1t−E1t ) ; i=1
|
|
|
|
|
|
|
|
|
|
|
|
|
|
N |
n n d |
(n |
|
− d |
|
) |
|
. |
SUL = å |
1t |
n2 |
(n −1) |
обt |
|
|
|
|
2t обt обt |
|
|
|
|
|
i=1 |
|
обt |
обt |
|
|
|
|
|
SU L = |
|
|
= 2,802996 . |
|
|
7,856786 |
|
|
Далее найдем значение: zэмп |
= U L |
= |
4,518731 |
|
=1,612 . Критическое |
|
|
|
|
SU L |
|
2,802731 |
|
|
табличное значение zтаб =1,96 |
при |
α=0,05. |
|
То есть табличное |
значение больше эмпирического. Следовательно, принимается гипотезе Н0 – об отсутствии различий между кривыми выживаемости в первой и второй группах.
Уточним данные с помощью поправки Йейтса:
zэмп = |
|
UL |
|
− 0,5 |
= |
4,518731 − 0,5 |
=1,433 |
. Как видно эмпирическое |
|
|
|
|
|
|
|
|
SU L |
2,802731 |
|
|
|
|
|
значение стало еще меньше критического. Следовательно, у нас нет оснований для отклонения нулевой гипотезы.
Критерий Гехана33 состоит в сравнении каждого наблюдаемого из первой группы с каждым наблюдаемым из второй группы. Результат сравнения оценивают как +1, если наблюдаемый из 1-й группы наверняка прожил дольше, -1, если он наверняка прожил меньше, и 0, если невозможно наверняка сказать, кто из них прожил дольше. Последнее возможно, если оба выбыли, если один выбыл до того, как умер другой, и если время наблюдения одинаково. Результаты сравнения для каждого больного суммируют, и обозначают сумму h. Сумма всех h дает величину
33 Является обобщением критерия Уилкоксона.

UW, стандартная |
|
ошибка которой вычисляется по |
формуле34: |
SUW = |
|
n1n2 åh2 |
|
|
. |
|
(n1 +n2 )(n1 +n2 1) |
|
|
|
|
− |
|
Далее |
подобно |
логранговому критерию вычисляем |
величину |
zэмп = UW , которую сравнивают с табличным значением по таблице
SUW
стандартного нормального распределения.
Поправка Йетса также применима и к критерию Гехана.
|
|
|
|
|
|
|
|
С. |
Гланц |
отмечает, |
что |
логранговый |
критерий |
предпочтительнее |
|
критерия |
Гехана, |
если |
справедливо |
предположение |
о |
постоянном |
соотношении |
смертности: |
S2 (t) = [S1(t)]ψ , где |
ψ |
– отношение |
смертности. |
Установить, |
выполняется ли это условие, можно, нарисовав графики ln[− lnS1(t)] и
ln[− lnS2(t)] - они должны быть параллельны. Во всяком случае, кривые выживаемости не должны пересекаться.
Для применения логрангового критерия следует учесть 4 условия:
1)применяется только для сравнения 2-х выборок (не более);
2)сравниваемые выборки независимы и случайны;
3)выбывание в обеих выборках одинаково;
4) функции выживаемости связаны соотношением: S2 (t) = [S1(t)]ψ , где ψ – отношение смертности. Если ψ=1, то кривые выживаемости совпадают; если ψ<1, то наблюдаемые во второй выборке умирают позже, чем в первой; если ψ>1, то наблюдаемые во второй выборке умирают раньше, чем в первой.
Чувствительность критерия и объем выборки.
34 Гланц С. Медико-биологическая статистика/С.Гланц. – Пер с англ. – М.: Практика, 1998. С. 395.

Чувствительность любого критерия (способность или сила выявления различий) зависит от трех величин: 1) величины разницы, которую нужно уловить; 2) уровня значимости (то есть на какую погрешность мы согласны: 1%, 2%...5%, 10%); 3) объема выборки (численности групп наблюдения). Соответственно и объем выборки необходимый для того, чтобы улавливать различия не менее конкретной желаемой величины, будет зависеть от уровня значимости и чувствительности критерия. Применяя логранговый критерий или критерий Гехана не следует забывать о вышесказанном. Чем меньшее различие необходимо уловить, тем с большим объемом выборки придется иметь дело.
Посмотрим, как же следует определять объем выборки. Вопервых, нужно оценить число исходов (смертей, совершения преступлений, увольнений с работы, отказов приборов и т.п.):
α |
1−β |
2 |
æ1 |
+ψ ö2 |
, где ψ – отношение |
смертности, |
α и |
−β |
) |
ç |
÷ |
d =(z |
+ z |
ç |
÷ |
|
|
z |
z1 |
|
|
|
è1 |
-ψ ø |
|
|
|
|
соответствующие α и 1-β табличные значения стандартного нормального распределения. Так как при всех значениях t соблюдается равенство S2 (t) = [S1(t)]ψ , то параметр ψ уместно
|
оценить по формуле: |
ψ = ln S2 |
(∞) |
, где |
S ( ) |
S |
( ) |
- выживаемость в |
|
ln S1 |
(∞) |
1 ∞ и |
2 |
∞ |
|
|
|
|
|
|
|
|
|
|
первой и второй группах |
в конце |
наблюдения. Отсюда имеем |
|
формулу для оценки объема каждой из групп: n = |
|
d |
. |
|
2 −S1 (∞) −S2 (∞) |
|
|
|
|
|
|
|
|
|
Задача. Пусть новая методика обеспечивает снижение текучести кадров в уголовном розыске с 40 до 20%. Разницу между старой и новой методикой мы хотим уловить с вероятностью 70% (то есть чувствительность теста 1-β=1-0,3=0,7). Приняв уровень значимости α=0,05, по таблице критических значений Стьюдента35 при бесконечном числе степеней свободы (df=∞) получим 1,96, а для t1−β =t0,7 =0,75 . Значение вероятности для любого z можно найти
35 Полезные сведения: при увеличении числа степеней свободы распределение Стьюдента стремится к нормальному, а, следовательно, критические значения z можно найти и по распределению Стьюдента, взяв его при df=∞.
в ППП Excel, задав функцию =НОРМСТРАСП(z). В появляющемся окне «Аргументы функции» нужно задать соответствующее число, и нажать клавишу «OK», после чего в ячейке появится значение вероятности для данного числа z. Так для z=0,7 получим значение вероятности 0,75.
Далее оцениваем отношение смертности:
|
ψ = ln S2 |
(∞) |
= ln 0,2 |
= |
−1,609 |
=1,756 , |
|
− 0,916 |
|
ln S1 |
(∞) |
|
ln 0,4 |
|
|
|
2 |
æ1+ψ ö2 |
, |
|
|
|
|
d =(zα + z1−β ) |
ç |
|
÷ |
|
|
|
|
|
è1-ψ ø |
|
|
|
|
d =(1,96 +0,75) |
2 |
æ1+1,756 |
ö2 |
|
×ç |
-1,756 |
÷ |
=7,344 ×13,286 =97,5 |
|
|
è1 |
ø |
|
Таким образом, каждая из групп должна включать по 98 наблюдаемых.
Медиана выживаемости.
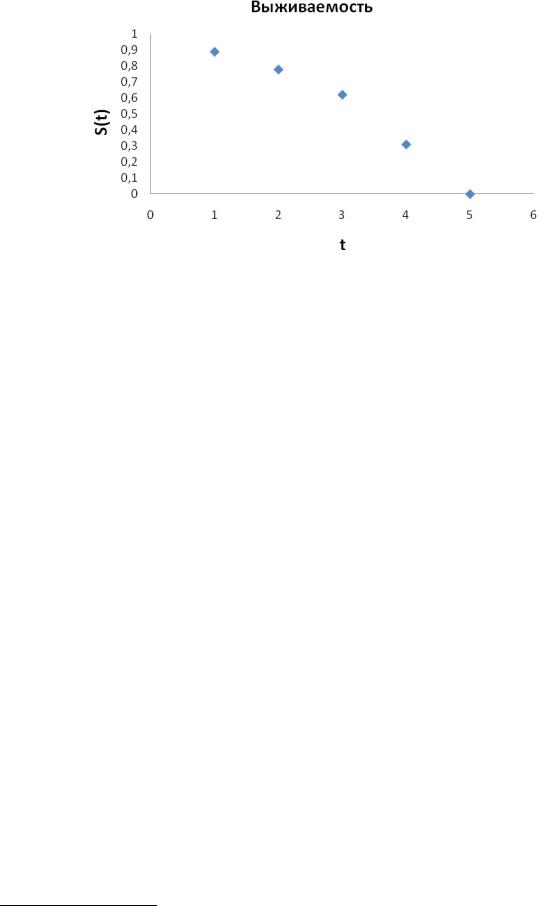
Еще одним важным понятием теории выживаемости является медиана выживаемости. Это обобщенный показатель, характеризующий выживаемость одним числом. Для выборки медиана выживаемости – это время (значение по абсциссе), для которого выживаемость принимает значение меньше 0,5. Например, для нижеследующей кривой выживаемости это t=4. Именно здесь кривая выживаемости падает за отметку 0,5.
РЕЗЮМЕ (основные определения)
Анализ выживаемости (survival analysis) – это статистический метод, нацеленный на: 1) выявление различий в тех случаях, когда мы имеем дело с неполными (цензурированными) данными36, «проблемой выбывания» объектов исследования; 2) получение полезных функций – выживаемости, смертности.
β-коэффициент риска криминологического процесса (β- coefficient of the risk criminological process) – это сравнительный показатель его изменчивости (устойчивости) на объекте S (конкретный населенный пункт (город, район), субъект РФ, страна) за период Т к средней изменчивости (риску) по всем исследуемым объектам G (всем населенным пунктам, субъектам РФ, странам). Рассчитывается как коэффициент регрессии в уравнении, где независимой переменной выступают коэффициенты криминологического процесса, например, преступности по G за период Т, а зависимой – коэффициенты данного криминологического процесса по S за тот же период. β- коэффициент риска криминологического процесса показывает, на сколько в абсолютном выражении изменяется его коэффициент по S при изменении коэффициента по G на единицу измерения. β- коэффициент риска криминологического процесса является показателем устойчивости временного ряда исследуемого
36 В анализе выживаемости используются полные (complete) и неполные, или цензурированные, наблюдения (censored).

процесса на объекте S и надежности его прогнозирования в
сравнении со средней надежностью прогнозирования по G.
Дисперсионный анализ (variance analysis) – раздел математической статистики, посвященный методам выявления влияния отдельных факторов на результат эксперимента.
Двухфакторный дисперсионный анализ – статистический метод, позволяющий выявить статистически значимое влияние на результативную переменную 2-х факторов и их взаимодействия, то есть влияния переменной X, переменной Z и взаимодействия переменных Х и Z.
Дисперсия (variance) – центральный момент второго порядка. Несмещенная выборочная дисперсия вычисляется по формуле:
|
|
1 |
n |
|
|
|
S 2 = |
å(xi − x)2 |
, где |
S2=Dвыб. – выборочная дисперсия, n – |
|
|
|
|
n −1 i 1 |
|
|
|
|
|
= |
|
|
объем выборки. В подробных курсах статистики доказано, что несмещенность обеспечивается за счет вычитания из объема выборки единицы (n-1).
Метод Тьюки-Крамера – статистический метод, позволяющий сравнивать, статистически значимо ли отличаются между собой пары сравниваемых показателей.
Общая дисперсия вычисляется по формуле: σ 2 = σ 2 + δ 2 , где σ2 - общая дисперсия ряда, σ 2 - средняя из групповых дисперсий, δ2 - межгрупповая дисперсия. Данный показатель рассчитывается, когда совокупность разбита на группы, и для каждой группы рассчитаны среднее и дисперсия.
|
m |
|
|
Межгрупповая дисперсия (variance) – δ 2 = |
å(yi - y)2 × ni |
, где δ2 - |
i=1 |
|
|
m |
|
|
åni |
|
i=1
межгрупповая дисперсия, yi - средние по каждой конкретной группе, y - объединенное среднее (среднее по всей совокупности)
|
|
m |
|
вычисляемое по формуле: |
y = |
å yi × ni |
. |
i=1 |
m |
|
|
åni |
|
|
|
i=1 |
|