

Глава 8. Введение в математическую статистику
§1. Выборочный метод
Основной целью математической статистики является разработка методов получения научно обоснованных выводов о массовых случайных явлениях и процессах на основе статистических данных. Эта цель распадается на две задачи: 1-я задача разработка способов сбора и группировки статистических данных; 2-я задача - разработка методов анализа статистических данных. Статистическими данными называются сведения о числе объектов в какой-либо обширной совокупности, обладающих теми или иными признаками. Всё множество изучаемых объектов называется генеральной совокупностью (Г.С.), число объектов в ней называется объемом и обозначается буквой N. Сплошное наблюдение часто оказывается невозможным и потому исследуется некоторая часть Г.С. Множество отобранных объектов называется выборочной совокупностью или выборкой, число объектов в выборке называется ее объемом и обозначается буквой n. При этом, если отобранный элемент после изучения возвращается в Г.С. и при отборе следующих элементов может быть выбран повторно, то выборка называется повторной; если же отобранный элемент не возвращается в Г.С., то выборка называется бесповторная.
Выборка называется репрезентативной, если она правильно представляет Г.С., т.е. процентное соотношение элементов, обладающих каким-нибудь свойством, одинаковое в Г.С. и в выборке. Выборка будет репрезентативной, если отбор ее элементов осуществляется случайно, причем каждый объект Г.С. имеет одинаковую возможность попасть в выборку. Для этого используют следующие виды отбора элементов выборки. Простой случайный отбор: все элементы Г.С. нумеруют и случайным образом выбирают номера. Типический отбор: вся Г.С. подходящим образом разбивается на несколько частей, и из каждой части случайным образом выбирается по одному элементу. Серийный отбор: вся Г.С. подходящим образом разбивается на несколько частей, случайным образом выбирается одна часть и все элементы этой части включаются в выборку. Механический отбор: все элементы Г.С. нумеруют, подбирают подходящее число m и выбирают по порядку каждый m-й ее элемент.
Пусть Х некоторый признак или свойство изучаемых объектов. Тогда Х можно считать случайной величиной, ее значения для элементов выборки объема n обозначаются малыми буквами х1, х2, ..., хn, и называются вариантами. Если вариант хi встречается в выборке mi раз, то mi называется частотой, а отношение mi : n называется относительной частотой или частостью этого варианта. Сумма частот всех различных вариантов равна объему выборки: m1 + m2 + ... + mk = n. Таблица всевозможных вариантов хi, расположенных в возрастающем ( или убывающем) порядке с указанием частот mi или относительных частот wi называется дискретным вариационным рядом частот или относительных частот данной выборки:
|
хi |
х1 |
х2 |
. . . |
хk |
|
mi |
m1 |
m2 |
. . . |
mk |
Эмпирической функцией распределения называется функция F*(х), которая каждому числу х ставит в соответствие относительную частоту nx/n cобытия Х < х : F*(х) = nx/n, где nx - число вариант, меньших х; n - объем выборки. Эта функция служит аналогом теоретической функции распределения F(х) величины Х. Для наглядного изображения вариационного ряда строят полигон, являющийся аналогом теоретической функции плотности. Полигон частот - это ломаная линия, соединяющая точки
А1(х1; m1), А2(х2; m2), ... , Аk(хk; mk); полигон относительных частот - это ломаная линия, соединяющая точки А1(х1; w1), А2(х2; w2), ..., Аk(хk; wk), в прямоугольной системе координат.
Если Х является непрерывной случайной величиной, принимающей все значения из промежутка (а; b), то используют интервальные вариационные ряды. В качестве концов промежутка (а; b) берут наименьший (а хmin ) и наибольший (b хmax ) варианты, разбивают (а; b) на интервалы (a1; b1), (a2; b2), ... , (ak; bk) такие, что a1 = а, bk = b и для остальных концов выполняется
bi = ai+1. Число интервалов k зависит от объема выборки n и обычно определяется по формуле Стерджесса: k (1+3,322lgn). Длины интервалов одинаковые hi = (b а)/k. Затем находят частоты интервалов mi - это число вариантов, входящих в i-й интервал. Интервальный вариационный ряд частот имеет вид
|
интервалы |
(a1;b1) |
(a2; b2) |
. . . |
(ak; bk) |
|
частоты |
m1 |
m2 |
. . . |
mk |
Для наглядного изображения интервального вариационного ряда строят гистограммы. Гистограмма частот - это плоская фигура в прямоугольной системе координат, составленная из прямоугольников, основаниями которых служат интервалы (ai; bi), а высоты Нi вычисляются по формулам Нi = mi/hi, где hi -длина i-го интервала. Характерная особенность гистограммы в том, что площади прямоугольников равны частотам соответствующих интервалов.
Пусть изучается некоторый признак Х, и х1, х2, ... , хn - варианты его значений для произвольной выборки объема n. Статистической оценкой признака Х называется функция (х1, х2, ... , хn) от вариантов х1, х2, ... , хn, с помощью которой вычисляется приближенное значение исследуемого признака: Х (х1, х2, ... , хn). Выборка осуществляется случайным образом, поэтому оценку (х1, х2, ... , хn) можно считать случайной величиной, тогда (х1, х2, ... , хn) может иметь математическое ожидание М() и дисперсию D(). Наилучшими считаются оценки следующих трех видов. Оценка (х1, х2, ... , хn) называется несмещенной, если ее математическое ожидание равно истинному значению изучаемого признака: М() = Х. Оценка (х1, х2, ... , хn) называется эффективной, если ее дисперсия D() является наименьшей среди дисперсий всевозможных оценок данного признака. Оценка (х1, х2, ... , хn) называется состоятельной, если ее значения стремятся к истинному значению признака при неограниченном возрастании объема выборки:
(х1, х2, ... , хn) Х при n
Пусть Х1, Х2, ..., ХN - значения признака Х для элементов Г.С. и х1, х2,..., хn - значения Х для элементов выборки. По ним определяются следующие величины:
1)
 =ХГ
- генеральная
средняя;
=ХГ
- генеральная
средняя;
2)
 =хв
- выборочная
средняя;
=хв
- выборочная
средняя;
3)
 =DГ
- генеральная
дисперсия;
=DГ
- генеральная
дисперсия;
4)
 =Dв
- выборочная
дисперсия;
=Dв
- выборочная
дисперсия;
5)
Г
= -генеральное
среднее квадратическое отклонение;
-генеральное
среднее квадратическое отклонение;
6)
в
= -выборочное
среднее квадратическое отклонение.
-выборочное
среднее квадратическое отклонение.
Если варианты х1, х2 , ... , хn имеют частоты m1 , m2, ... , mn , то указанные выше формулы принимают вид:
хв
=
 ,
,
Dв
=
 .
.
Пусть
некоторое событие А
встречается М
раз в Г.С.
объема
N, и
m раз в выборке
объема n.
Тогда величины
 =p
и
=p
и
 =w
называются соответственно генеральная
доля и
выборочная
доля события
А.
=w
называются соответственно генеральная
доля и
выборочная
доля события
А.
Теорема 1. а). Выборочная средняя является несмещенной, эффективной и состоятельной оценкой для генеральной средней:
М(хв) =ХГ ихв ХГ при n .
б). Выборочная дисперсия является смещенной оценкой для генеральной дисперсии, и выполняется равенство
М(Dв)
=
 .
.
в). Выборочная доля является несмещенной, эффективной и состоятельной оценкой генеральной доли:
М(w) = p и w p при n .
Доказательство (см. [4]).
При
достаточно больших объемах выборки
отклонение Dв
от DГ
является незначительным, но при n
< 20 это отклонение становится заметным,
и для оценки DГ
рекомендуется находть исправленную
дисперсию:S2
=
Легко доказывается, что S2 и S являются несмещенными оценками DГ и Г, соответственно. Некоторые другие понятия и методы данной темы указаны в следующих примерах.
Пример 1. Из генеральной совокупности извлечена выборка объема
|
хi |
2 |
5 |
7 |
10 |
|
mi |
16 |
12 |
8 |
14 |
Требуется: 1) найти эмпирическую функцию распределения; 2) построить полигоны частот; 3) найти выборочную среднюю, выборочную и исправленную дисперсии.
Решение. 1). Для х 2 вариант, меньших х, нет, поэтому F*(х) = 0. Для 2< х 5 число вариант, меньших х, равно 16, поэтому F*(х) =16/50 = 0,32. Для 5< х 7 число вариант, меньших х, 16 + 12 = 28, поэтому F*(х) = 28/50 = 0,56. Для 7< х 10 число вариант, меньших х, равно16+12+8 = 36, поэтому F*(х) = 36/50 = 0,72. Для х > 10 все варианты меньше х, тогда F*(х) = 1. Получена следующая эмпирическая функция распределения:
0, если x
2,
0,32, если 2 < x 5,
F*(x) = 0,56, если 5 < x 7,
0,72, если 7 < x 10,
1, если x > 10 .
2). Полигон частот - это ломаная А1(2; 16), А2(5; 12), А3(7; 8), А4(10;14); полигон относительных частот - это ломаная В1(2; 0,32), В2(5; 0,24), В3(7; 0,16), В4(10; 0,28).
Y
Y
16
А1
0,4


А4
В1

12
А2
0,3 В4

А3
В2
8
0,2
В X
X

0 1 2 3 4 5 6 7 8 9 10 0 1 2 3 4 5 6 7 8 9 10
Рис.4
3).
Выборочная средняя равна хв
=
(216+512+78+1014)/50
= 5,76. Выборочная дисперсия равна Dв
= [(2 5,76)216
+ (5
5,76)212
+ (75,76)28
+ (10
5,76)214]/50
= 9,9424. Исправленная дисперсия равна S2
=
 =
= Ответ:хв
= 5,76; Dв
= 9,9424; S2
10,145.
Ответ:хв
= 5,76; Dв
= 9,9424; S2
10,145.
Пример 2. Ниже приведены результаты измерения роста (X см) случайно отобранных 100 студентов.
|
X |
154158 |
158162 |
162166 |
166170 |
170174 |
174178 |
178182 |
|
mi |
10 |
14 |
26 |
28 |
12 |
8 |
2 |
1). Найти выборочную среднюю, выборочную и исправленную дисперсии.
2). Построить гистограмму частот.
Решение.
1). В качестве
вариантов берут середины интервалов
хi:
156, 160, 164, 168, 172, 176, 180. Они отстоят друг от
друга на одинаковых расстояниях, поэтому
можно ввести условные
варианты по
формуле
 ui
=
ui
=
 ,
гдеС
так называемый ложный
ноль, (в
качестве С
рекомендуется
выбирать вариант с наибольшей частотой),
h
– шаг, (он
равен расстоянию между вариантами).
Значениями условных вариант являются
небольшие целые числа и потому многие
вычисления существенно упрощаются. Для
условных вариантов находят среднее
значениеu
и средний квадратu2,
затем хв
и Dв
находят по формулам:
хв
=u
h
+
С; Dв
= (u2
(u
)2)h2.
Здесь
,
гдеС
так называемый ложный
ноль, (в
качестве С
рекомендуется
выбирать вариант с наибольшей частотой),
h
– шаг, (он
равен расстоянию между вариантами).
Значениями условных вариант являются
небольшие целые числа и потому многие
вычисления существенно упрощаются. Для
условных вариантов находят среднее
значениеu
и средний квадратu2,
затем хв
и Dв
находят по формулам:
хв
=u
h
+
С; Dв
= (u2
(u
)2)h2.
Здесь
С = 168, h = 4. Составляется расчетная таблица, которая заполняется по формулам, указанным в верхней строке.
|
хi |
mi |
ui |
miui |
miui2 |
|
156 |
10 |
-3 |
-30 |
90 |
|
160 |
14 |
-2 |
-28 |
56 |
|
164 |
26 |
-1 |
-26 |
26 |
|
168 |
28 |
0 |
0 |
0 |
|
172 |
12 |
1 |
12 |
12 |
|
176 |
8 |
2 |
16 |
32 |
|
180 |
2 |
3 |
6 |
18 |
|
å |
100 |
|
-50 |
234 |
В
нижней строке указаны суммы чисел по
каждому столбцу, с их помощью вычисляются
средние значения условных вариант:u=
50:100
= 0,5;
u2=234:100
= 2,34. По указанным выше формулам
находятся
искомые величины:
хв
= 0,54
+ 168 = 166; Dв
= (2,34
(0,5)2)42
= 33,44; S2
=
 33,44
33,778.
33,44
33,778.
2).
На оси ОХ
откладываются интервалы и на них
строятся прямоугольники, высоты которых
вычисляются по формуле Нi
=
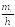 :Н1
= 2,5; Н2
= 3,5; Н3
= 6,5; Н4
= 7; Н5
= 3; Н6
= 2; Н7
= 0,5.
:Н1
= 2,5; Н2
= 3,5; Н3
= 6,5; Н4
= 7; Н5
= 3; Н6
= 2; Н7
= 0,5.
Y
7












1
X


0 154 158 162 166 170 174 178 182
Рис.5.
1. Беклемишев Д. В. Курс аналитической геометрии и линейной алгебры. – М., «Наука»., 1980. -236 с.
2. Минорский В. П. Сборник задач по высшей математике. –М.: Изд-во «Наука»., 1971.-352 с.
2. Сахарников Н. А. Высшая математика. Изд-во Ленинград. ун-та, 1973,
-473 с.
3. Фаддеев Д.К., И.С.Соминский Сборник задач по высшей алгебре, -М., «Наука», 1977
4. Кремер Н. Ш. Теория вероятностей и математическая статистика. М.: ЮНИТИ,-2000.