

Гусев / Методы научных исследований
.pdfданием равным нулю и средним квадратичным отклонением
σx = −1 , то сумма квадратов x , будет распределена по закону
сплотностью вероятности который называется распределением χ2 или Пирсона:
0 |
x ≤ 0 |
|
|
|
|
|||
|
|
1 |
|
|
|
|
; |
|
f (x2 ) = |
|
x |
( f / 2)−1 |
e |
−x 2 / 2 |
|||
|
|
|
|
|
||||
2 f / 2 д( f / 2) |
|
|
|
|||||
|
|
|
n |
|
|
|
|
|
|
|
x2 |
= ∑xi2 . |
|
|
|
||
Г(x) - гамма-функция; |
|
i=1 |
|
|
|
|
||
f |
- число степеней свободы при |
|||||||
определении суммы χ2 , равно (n-1). |
|
|
|
|
||||
Распределение Пирсона зависит только от |
f и с увели- |
|||||||
чение числа степеней свободы стремится к нормальному распределению. Кривые χ2 - распределения асимметричны (рис.2.10.), но коэффициент асимметрии стремится к нулю при n → ∞ .
Рис. 2.10. Плотность распределения χ2 |
2.3.5. Распределение Стьюдента ( t - распределение) |
Если сравнивать нормированную нормальную случайную величину x с другой, независимой от x случайной величиной z , распределенной по закону Пирсона χ2 с k степенями свободы, то это отношение имеет распределение, на-
41

зываемое распределением Стьюдента - t :
t = |
x |
|
|
. |
|
z / k |
||
Плотность вероятности имеет вид:
f (t) = π1k
|
д( |
k +1 |
) |
|
t |
2 |
|
t+1 |
|||
|
|
||||||||||
|
|
2 |
|
(1+ |
|
) |
|
, −∞ < t < +∞ |
|||
|
|
|
|
2 |
|||||||
д( |
k |
k |
|||||||||
|
|
|
|
|
|||||||
|
2) |
|
|
|
|
|
|
|
|||
График плотности распределения быстро приближается к нормальной кривой с увеличением k (рис. 2.11.).
|
f(t) |
|
|
|
k=∞ |
|
|
k=2 |
-t |
0 |
+t |
|
|
Рис. 2.11. Распределение Стьюдента при различных степенях свободы
2.3.6. Распределение Фишера
Если две независимые величины x и z распределены по закону χ2 со своими степенями свободы, соответственно k1 и k2 , то величина:
F = x / k1 , z / k2
имеет распределение Фишера - F с плотностью:
42

|
д( |
k |
+k |
2 |
) |
|
|
|
|
|
|
||
|
1 |
|
|
|
|
|
F (k1 −2) / 2 |
|
|||||
f (F ) = |
|
|
2 |
|
|
k k2 / 2k k1 / 2 |
|
|
|||||
|
k1 |
|
k2 |
|
(k |
|
+ k F )(k1 +k2 ) / 2 , при F >0 |
||||||
|
д( |
д( |
1 2 |
|
|||||||||
|
2 ) |
2 |
) |
|
|
2 |
1 |
|
|||||
|
|
|
|
|
|
|
|
|
|
|
|
||
и
f (F )= 0 при F ≤ 0.
f(F)
(k1=10;k2=50)
(k1=10;k2=4)
0 |
1 |
2 |
3 |
4 |
F |
Рис. 2.12. Графики плотности F - распределения
Распределение Фишера определяется только числами степеней свободы соотносящихся величин. Графики плотностей F - распределения приведены на рис. 2.12.
3. Определение параметров функции распределения
3.1. Генеральная совокупность и случайная выборка
Из самого определения случайной величины следует, что на практике можно получить только ограниченное количество значений случайной величины, которое представляет собой некоторую выборку из генеральной совокупности всех возможных значений случайной величины. И при этом встает вопрос о том, на сколько достоверно суждение о свойствах случайной величины (генеральной совокупности) по свойствам ограниченной выборки.
43

Выборка называется репрезентативной (представительной), если она дает достаточное представление об особенностях генеральной совокупности [4]. Если о генеральной совокупности ничего не известно, то единственной гарантией репрезентативности может служить случайный отбор в определении случайной величины - рандомизация.
Любая ограниченная выборка сама по себе является случайной и из случайного характера выборок следует, что любое суждение о генеральной совокупности по какой–либо выборке случайно.
Предположим, что в результате эксперимента получена выборка x1 , x2 , x3 ......xn значений случайной величины X объемом n . Пусть x некоторая точка на числовой оси x . Если обозначить через nx число выборочных точек, расположенных левее x на той же оси, то отношение nx 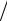 n представляет собой частоту наблюдаемых в выборке значений случайной величины X < x . Эта величина называется эмпирической или выборочной функцией распределения
n представляет собой частоту наблюдаемых в выборке значений случайной величины X < x . Эта величина называется эмпирической или выборочной функцией распределения
Fn (x)= nnx .
При n → ∞ , максимальная разность между функцией распределения случайной величины и выборочной функцией распределения стремится к нулю с вероятностью равной 1:
P( |
|
F(x)− Fn (x) |
|
→ 0)=1 |
. |
|
|
|
|||||
n → ∞ |
||||||
|
||||||
Практически это означает, что при достаточно большой выборке функцию распределения генеральной совокупности приближенно можно заменить выборочной функцией распределения.
Если x1 < x2 < x3 < .... < xn - упорядоченная по величинам выборка из генеральной совокупности случайной величины X и все элементы имеют одинаковую вероятность, равную
44

Fn (x)= 0 |
при |
x < x1 |
Fn (x)= k n |
при |
xk ≤ x ≤ xk +1 |
Fn (x)=1 |
при |
x < xn . |
Все элементы выборки являются точками разрыва этой функции.
При обработке наблюдений обычно не удается получить эмпирическую функцию распределения. Ее тип определяется на основе некоторых числовых параметров распределения.
По выборке могут быть рассчитаны выборочные статистические характеристики, являющиеся оценками соответствующих генеральных параметров. К оценкам генеральных параметров предъявляют требования состоятельности и несмещённости.
Оценка a(x1 , x2 , x3 ....xn ) называется состоятельной, если с увеличением объема выработки n она стремиться (по вероятности) к оцениваемому параметру a .
Оценка называется несмещенной, если ее математической ожидание при любом объеме выборки равно оцениваемому параметру M [a]= a .
Оценками выборки могут быть: выборочное среднее и дисперсия.
Для получения оценок применяют метод максимального правдоподобия. Его сущность заключается в нахождении таких оценок неизвестных параметров, для которых функция правдоподобия при случайной выборке объема n будет иметь максимальное значение.
3.2. Оценки математического ожидания и дисперсии
Для нормально распределенной случайной величины оценками являются:
45
- среднее арифметическое x - для математического ожидания mx :
n
x= ∑xi / n ;
i=1
ивыборочная дисперсия Sx2 - для дисперсии D[x]:
n
Sx2 = ∑(xi − x)2 / n −1.
i=1
Уменьшение знаменателя на единицу связано с тем, что величина x сама зависит от элементов выборки. Каждая величина, зависящая от элементов выборки и входящая в формулу выборочной функции, называется связью. Знаменатель выборочной дисперсии всегда равен разности между объемом выборки n и числом связей l наложенных на эту выборку. Этот параметр называется числом степеней свободы выборки f :
f= n −l .
3.3.Определение дисперсии по текущим измерениям
Математическое ожидание и дисперсия генеральной совокупности оцениваются средним и дисперсией выборки тем точнее, чем больше объем выборки.
При этом среднее характеризует результат измерения, а дисперсия - точность этого результата (называется дисперсией воспроизводимости).
Если проделано m параллельных опытов, и получена выборка y1 , y2 , y3 ...y j ...ym значений измеряемой величины y , то дисперсия воспроизводимости будет равна:
m
∑( y j − y)2
Sвоспр2 = |
j=1 |
|
, |
|
m −1 |
||
|
|
|
|
где y - воборочное средне: |
|
|
|
46

m
∑y j
y = j=1m .
Ошибка опыта (ошибка воспроизводимости):
Sвоспр =  Sвоспр2 .
Sвоспр2 .
Обычно ошибку воспроизводимости определяют по текущим измерениям. Если в результате исследований сделано n опытов, каждый опыт повторяется m раз, то общая дисперсия воспроизводимости всех опытов будет равна:
n
∑Sвоспр2 .i
Sвоспр2 = |
i=1 |
|
; |
|
n |
||
|
|
|
Таким образом, при равном числе параллельных опытов общая дисперсия воспроизводимости равна среднеарифметическому значению частных дисперсий.
Число степеней свободы общей дисперсии воспроизводимости равно:
fвоспр = n(m −1). |
|
||
И окончательно: |
|
||
|
n m |
|
|
Sвосп2 р = |
∑ ∑( yiu − yi )2 |
|
|
i =1u=1 |
. |
||
n(m −1) |
|||
|
|
||
При вычислении дисперсии воспроизводимости по текущим измерениям объединяют только значения опытов с равными дисперсиями.
3.4. Доверительные интервалы и доверительная
вероятность
Выборочные параметры являются случайными величинами, и их отклонения от соответствующих генеральных параметров так же будет случайным. Оценка этих отклонений
47

носит вероятностный характер, т.е. можно указать лишь вероятность той или иной величины отклонения или погрешности. Для этого пользуются понятием доверительного интервала и доверительной вероятности [4].
Пусть для генерального параметра A получена из опыта несмещенная оценка a . Нужно оценить возможную при этом ошибку ε с некоторой достаточно большой вероятностью β .
Значение ошибки εβ , для которой вероятность появления была бы равна β записывается следующим образом:
P(a − A ≤ εβ )= β .
При этом диапазон возможных значений ошибки будет равен ±εβ . Большие по абсолютной величине ошибки будут появляться с малой вероятностью: p =1− β . Вероятность p называется уровнем значимости, а вероятность β называется доверительной вероятностью и характеризует надежность полученной оценки, т.е. такого события, когда выполнятся условие:
(a −εβ )≤ A ≤ (a +εβ ).
Интервал Iβ = (a ±εβ ) называется доверительным интервалом, а его границы ( a = a +εβ и a = a −εβ ) - доверительными границами.
Доверительный интервал при данной доверительной вероятности определяет точность оценки. Величина доверительного интервала зависит от доверительной вероятности, с которой гарантируется нахождение параметра A внутри доверительного интервала. Чем больше β , тем шире доверительный интервал, тем больше и погрешность εβ . Иначе говоря, с чем большей надежностью хотят гарантировать полученный результат, тем в большем интервале значений он может находиться.
48
Обычно на практике задаются значением доверительной вероятности (0,9;0,95 или 0,99) и, исходя из этого, определяют доверительный интервал:
+β
P(| a − A |≤ εβ ) = p( a ≤ εβ ) = F(εβ ) − F(−εβ ) = ∫ f (x)dx = β ,
−β
(3.1)
где F(εβ ) - функция распределения ошибок εβ случайной величины a ;
- плотность распределения ошибок.
Таким образом, если известен закон распределения оценки a , то доверительный интервал определяется по уравне-
нию (3.1).
Для математического ожидания нормально распределенной случайной величины x с известным среднеквадратичным отклонением σ x , доверительный интервал определяется следующим образом.
Пусть имеется выборка объема n значений этой случай-
ной величины. Оценкой |
математического ожидания mx яв- |
||
ляется среднее выборки |
x : |
||
|
|
n |
|
|
|
∑xi |
|
|
x = |
i =1 |
. |
|
|
||
|
|
n |
|
Выборка из генеральной совокупности, распределенной нормально, так же имеет нормальной распределение. Тогда с помощью функции Лапласа, получается:
P(| x − mx |< εβ |
= β = 2Ф( |
εβ |
). |
|
|||
|
|
σ x |
|
Задаваясь доверительной вероятностью β , определяется соответствующее ей отношение εβ  σч . И доверительный интервал для математического ожидания mx примет вид:
σч . И доверительный интервал для математического ожидания mx примет вид:
49

x −( |
εβ |
)σx ≤ mx ≤ x + ( |
εβ |
)σx . |
|||||||
|
|
||||||||||
|
|
|
σx |
|
|
σx |
|
|
|||
Вводя обозначения: |
|
|
|
|
|
|
|
||||
|
εβ |
|
= kβ |
σx = |
σ 2 |
= |
σ |
x |
, |
||
σx |
n |
|
|
||||||||
|
|
|
|
|
|
n |
|
||||
получается:
x −kβσx ≤ mx ≤ x +kβσx
x − kβ |
σx |
≤ mx ≤ x + kβ |
σx |
, |
(3.2) |
|
n |
n |
|||||
|
|
|
|
где kβ - определяется по функции Лапласа.
Из (3.2) видно, что уменьшение доверительного интервала обратно пропорционально корню квадратному из числа наблюдений. И если надо уменьшить возможную ошибку в 2 раза, необходимо увеличить число опытов в 4 раза.
3.5. Проверка статистических гипотез
Как уже говорилось, закон распределения генеральной совокупности в большинстве случаев неизвестен заранее. О его виде можно сделать только предположение по отдельным признакам или просто принять некую гипотезу о характере распределения.
Под статистической гипотезой понимают некоторое предположение относительно распределения генеральной совокупности случайной величины.
Проверка гипотезы заключается в сопоставлении «критериев проверки» (критериев значимости), вычисляемых по выборке, со значениями этих показателей, определенными в предположении, что гипотеза верна.
При проверке гипотез подвергается испытанию некоторая гипотеза Н0 в сравнении с альтернативной гипотезой Н, которая формулируется.
50