

4.4. Генотип-средовое взаимодействие
Существующие в популяции генетические различия могут не превращаться в фенотипические, если среда не способствует этому.
Генотип-средовое статистическое взаимодействие увеличивает фенотипическую дисперсию в популяции.
Генотип-средовое взаимодействие является компонентом фенотипической дисперсии.
Следует различать генотип-средовое взаимодействие как статистический компонент дисперсии и реальное взаимодействие генотипа и среды при формированиии конкретного фенотипа.
Явление неслучайного распределения генотипов по средам носит название генотип-средовой ковариации (корреляции).
Генотип-средовая ковариация может быть положительной, если и генотип и среда варьируют в одном направлении (чем хуже генотип, тем хуже среда; чем лучше генотип, тем лучше среда) и отрицательной, если генотип и среда варьируют в противоположных направлениях (чем хуже генотип, тем лучше среда и наоборот).
Положительная ковариация увеличивает популяционную дисперсию, отрицательная - уменьшает.
Различают три вида генотип-средовой ковариации: пассивную, реактивную и активную.
Генотип-средовое взаимодействие и генотип-средовая ковариация могут влиять на величины оценок наследуемости.
Словарь терминов
Дисперсия
Мода
Медиана
Стандартное отклонение
Решетка Пеннета
Эпистаз
Локус
Аллель
Полимерные гены
Наследуемость
Норма реакции
Инбридинг
Клон
Генотип-средовое взаимодействие
Генотип-средовая ковариация
Вопросы для самопроверки
Какие статистические величины существуют для описания частотных распределений?
Почему тесты, применяемые для измерений в психогенетике, должны отличаться надежностью и валидностью?
Что такое дисперсия и по какой формуле она вычисляется?
Какие статистические величины используются для характеристики групповых и индивидуальных различий?
Может ли возникать нормальное распределение признака в популяции при отсутствии генетической изменчивости?
В каких группах может отсутствовать генетическая изменчивость?
Какие группы организмов называются клонами?
Существуют ли клоны в человеческой популяции?
Что в генетике называется нормой реакции?
Почему нежелательно в определении нормы реакции пользоваться такими понятиями как предел, предельные возможности генотипа и т.п.?
Приведите примеры нормы реакции у животных и растений.
Почему говорят, что наследуется не признак, а норма реакции?
Почему невозможно получить нормы реакции для человека?
Графики каких гипотетических норм реакции для психологических признаков человека можно построить?
Что является критическим для нормального развития интеллекта у человека?
Почему психогенетика работает в основном с дисперсиями?
От каких факторов зависит количественная изменчивость признаков?
Что такое генотип и фенотип? Приведите примеры поведенческих фенотипов.
Объясните разницу между понятиями генотип, геном и генофонд.
Как можно объяснить, что генотипические и средовые факторы влияют на количественную изменчивость в популяции?
Как можно представить взаимодействие генотипа и среды в индивидуальном развитии человека?
Почему в психогенетике следует различать взаимодействие генотипических и средовых факторов при формировании популяционного разнообразия и при формировании индивидуального фенотипа?
Почему в психологии и генетике ведутся дискуссии по проблеме соотношения наследственного и средового в человеке?
Какие генотипы будут представлены в популяции, если ген имеет три аллельные формы?
Каковы будут фенотипы, если эти аллели определяют разную количественную выраженность признака, а эффекты доминирования отсутствуют?
Равномерно ли распределены генотипы в популяции? Покажите это на модели.
Что доказывает разную чувствительность генотипов к среде? Продемонстрируйте на модели.
От чего зависит количественная изменчивость в пределах одного генотипа?
От чего зависит фенотипическая изменчивость во всей популяции?
Почему дисперсия в пределах одного генотипа является чисто средовой?
Из чего слагается генетическая дисперсия в популяции?
Какие дисперсии в приведенной модели могут быть вычислены непосредственно?
Каким образом может быть вычислена генетическая составляющая дисперсии?
Тема 5. Фенотипическая структура популяции и математическое моделирование в психогенетике
5.1. Введение
5.2. Компоненты генетической дисперсии
5.3. Компоненты средовой дисперсии и эффекты генотип-средового взаимодействия
5.4. Ассортативность как фактор, влияющий на фенотипическую дисперсию
5.5. Математическое моделирование в психогенетике
5.1. Введение
В предыдущем разделе мы познакомились с тем, что такое количественная изменчивость в популяции, как она измеряется, за счет каких причин возникает. На моделях простейших популяций с ограниченным числом генотипов мы продемонстрировали, как генетическая и средовая вариативности создают вариативность фенотипическую, и выразили это основной формулой: VP = VG + VE. Кроме того, мы выяснили, что помимо двух основных факторов -генетического и средового - на фенотипическую дисперсию влияют также факторы, обусловленные особенностями их взаимодействия (напоминаем, что имеются в виду статистические компоненты, а не реальное взаимодействие генотипа и среды в индивидуальном развитии). К компонентам, указывающим на взаимодействие генотипа и среды, относятся генотип-средовое взаимодействие и генотип-средовая ковариация (корреляция). Когда мы записываем формулу фенотипической структуры популяции в виде суммы лишь двух компонентов - генетического и средового, - мы принимаем, что значения компонентов взаимодействия равны нулю. Если на самом деле это не так, то оценки VG и VE будут несколько искаженными. Соответственно это отразится и на значении коэффициента наследуемости, который, как мы помним, вычисляется по формуле:
h2 = VG/VF.
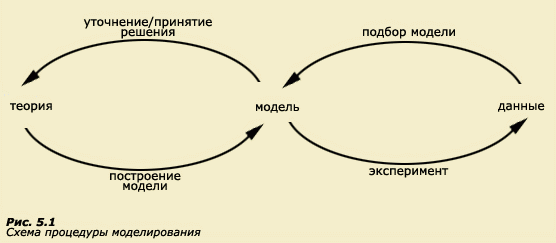
В реальных популяциях, где присутствуют тысячи обладателей разных генотипов, где среда постоянно варьирует, а каждый генотип реагирует на эти изменения в соответствии со своей уникальной нормой реакции, естественно, невозможно бывает непосредственно измерить такие параметры, как VG (генетическая дисперсия) и VE (средовая дисперсия). Измерению доступны лишь фенотипические особенности. Следовательно, лишь фенотипическая дисперсия (VP) может быть оценена непосредственно путем статистической обработки эмпирического материала. Необходимо помнить, что фенотипическая дисперсия в популяции возникает в силу многих причин, каждая из которых вносит свой вклад в наблюдаемое разнообразие признаков. На какие же компоненты может быть в результате разложена фенотипическая дисперсия и как количественно оценить каждый из них? В биометрической генетике разработаны специальные математические методы количественной оценки отдельных составляющих фенотипической дисперсии. Все они основаны на математическом моделировании и требуют основательной подготовки в области теории вероятностей, математической статистики и других разделов математики. Современному специалисту, работающему в области психогенетики, требуется также обладать достаточными знаниями и умениями в сфере компьютерных технологий, поскольку приходится иметь дело с весьма сложными пакетами программ, специально разработанными для этих целей (например, уже упоминавшийся нами ранее LISREL). В данном учебнике мы не ставим задачу научить читателей всем тонкостям математического моделирования. Постараемся объяснить лишь главные принципы. Для более глубокого знакомства с количественными методами генетики поведения можно обратиться к другим изданиям (Мазер К., Джинкс Дж., 1985; Рокицкий П.Ф., 1978; Ли Ч., 1978; Роль среды и наследственности, 1988. Гл. 1; Малых С.Б. и др., 1998. Гл. 6; Равич-Щербо И.В. и др., 1999. Гл. 8). Основы для развития биометрической генетики были заложены еще в конце XIX в. работами Ф. Гальтона, К. Пирсона и их учеников, однако они не могли дать плодотворных результатов до той поры, пока биометрический гальтоновский подход не был соединен с генетическим - менделевским. Напомним, что в начале XX в. оба направления в генетике постоянно враждовали. Лишь после появления в 1909 г. учения В. Иогансена о чистых линиях (Хрестомат. 5.1) и публикаций в том же году работ Г. Нильсона-Эле о наследовании интенсивности окраски зерен у овса и пшеницы (Хрестомат. 5.2), стало ясно, что непрерывная количественная изменчивость может возникать за счет суммации эффектов полигенов, для каждого из которых справедливо наследование по Менделю. Дальнейшая интеграция биометрии и генетики произошла в 1918 г., когда Р. Фишер продемонстрировал, что корреляции между родственниками у человека могут объясняться в рамках менделевской концепции. Р. Фишер же предпринял первую попытку разложить непрерывную изменчивость на компоненты. Методы математического моделирования применяются в количественной (биометрической) генетике с целью выделения непосредственно не измеряемых компонентов дисперсии. Построение любой модели обязательно включает два этапа: создание системы уравнений, формально описывающих предполагаемые соотношения между переменными, и решение этой системы уравнений, в результате чего выбирается модель, наилучшим образом соответствующая наблюдаемым данным (на английском языке этот процесс носит название model-fitting). На рис. 5.1 процесс подбора модели представлен в виде диаграммы.
Простейшая генотип-средовая модель описывается уравнением: VP = VG + VE. В этой модели и генетическая, и средовая дисперсии также могут быть разложены на субкомпоненты.
5.2. Компоненты генетической дисперсии
Как уже упоминалось, в полигенных системах существуют различные эффекты взаимодействия между генами (аддитивный, доминирование, эпистаз). Рассмотрим простейший случай. Предположим, что вариативность признака определяется всего одним геном, который имеет два аллеля А и а. Следовательно, в популяции будут представлены три генотипа: гомозиготы АА и аа и гетерозиготы Аа. Пусть аллель А является усилителем, а аллель а - ослабителем. Предположим, что взаимодействие указанных аллелей носит чисто аддитивный характер. В таком случае гетерозиготы будут занимать строго промежуточное положение между гетерозиготами. Мы можем все это выразить графически (рис. 5.2).
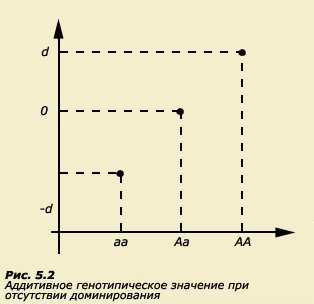
Таким образом, при чисто аддитивном взаимодействии зависимость фенотипа от генотипа будет линейной. Если наблюдается полное доминирование, то график будет выглядеть иначе (рис. 5.3).

При доминировании не наблюдается линейной зависимости. Если присутствуют оба типа эффектов (аддитивный и доминирование), то наблюдаемые значения признака будут отличаться от теоретически ожидаемых (рис. 5.4).
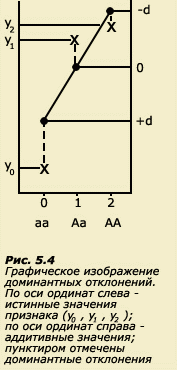
Пунктиром показаны доминантные отклонения от теоретически ожидаемых значений при чисто аддитивном эффекте. Если y1= y2, то мы имеем дело с полным доминированием; если у1<y2, то имеет место неполное доминирование; если у1>у2 или у1<у0, то говорят о сверхдоминировании. Таким образом, фенотипическое значение каждого из трех генотипов можно представить как сумму двух слагаемых, первое из которых является линейной оценкой по генотипу и находится на линии регрессии, а второе представляет собой отклонение, вызванное доминированием. Аддитивному и доминантному компонентам генотипического отклонения соответствуют и два компонента генетической дисперсии: VG = VА + VD. Таким образом, формула фенотипической структуры популяции для модели, предполагающей наличие как аддитивных эффектов, так и эффектов доминирования, может быть записана так: VP = VА + VD + VE. Доминирование возникает при взаимодействии генов одного локуса. Если подобные эффекты имеют место для разных локусов, то говорят об эпистазе. Тогда помимо аддитивного и доминантного компонентов в предыдущую формулу можно добавить дисперсию, обусловленную эффектами эпистаза (VI), и она примет вид: VP = VА + VD + VI + VE , где VА , VD и VI есть субкомпоненты генетической дисперсии VG.
5.3. Компоненты средовой дисперсии и эффекты генотип-средового взаимодействия
Поскольку в психогенетике основным источником информации для математического моделирования является анализ сходства и различия между родственниками, в рамках генотип-средовой модели чаще всего выделяют два основных типа средовой дисперсии. Один из них связан с возникновением различий между родственниками, другой - с формированием сходства. Эти компоненты имеют различные названия и часто по-разному обозначаются. В таблице 5.1 приведены наиболее часто встречающиеся названия и обозначения.
Таблица 5.1.
Средовые компоненты фенотипической дисперсии |
|||
Среда, формирующая различия |
Среда, формирующая сходство |
||
Название |
Обозначение компонента дисперсии |
Название |
Обозначение компонента дисперсии |
Случайная |
VW |
Систематическая |
VB |
Неразделенная (nonshared) |
Ensh |
Разделенная (shared) |
Esh |
Различающаяся (индивидуальная, специфическая, уникальная) |
VEN VN e e2 |
Общая (общесемейная) |
VEC VC c c2 |
Внутрисемейная |
EW, VW |
Межсемейная |
EB, VB |
Большая часть психогенетических исследований имеет дело с семейными сравнениями, т.е. изучает сходство и различия между родственниками. Сходство и различия между родственниками могут возникать как в силу генетических причин, поскольку родственники имеют как общие, так и различающиеся гены (кроме однояйцовых близнецов, у которых все гены совпадают), так и в силу средовых причин, если они проживают совместно. Поэтому доступные для анализа факторы средовой дисперсии так или иначе связаны с условиями семейной и внесемейной среды, влияющей на возникновения сходства и различия родственников различных степеней родства. Каждая семья имеет свои особенности, которые отличают ее от других семей, но являются общими для всех ее членов. Эти особенности семьи приводят к возникновению сходных черт у родственников, которые разделяют условия семейной среды. Отсюда и возникают такие названия, как общая, общесемейная, разделенная среда. Менее понятно обозначение "межсемейная", но оно означает, что это среда, которая формирует различия между семьями, но является общей для членов одной семьи. Эта среда систематически влияет на родственников, поэтому ее иногда называют систематической. К общесемейным факторам среды можно отнести все то, что С. Скарр предлагает называть различиями в возможностях (социально-экономический статус семьи): уровень достатка, жилищные условия, образование родителей, культурные традиции, особенности питания, отдыха и т.п. Например, достаток семьи определяет полноценность питания, образования, медицинского обслуживания всех членов семьи. Понятно, что чем выше экономический статус семьи, тем более обогащенную среду будут разделять дети: это различные дополнительные занятия, развивающие игры, большее количество книг в доме, компьютер, спортивный инвентарь, возможность выбора более престижного образовательного учреждения и т.д. Общая среда может разделяться родственниками не только в условиях семьи. Если дети посещают одну и ту же школу или внешкольные занятия, то там они тоже попадают в сходные средовые условия. Любые сходные ситуации, в которых оказываются члены одной семьи, могут способствовать возникновению у них сходных особенностей. Все это и относится к общей, или разделенной, среде. До середины 80-х гг. считалось, что общая среда вносит значительный вклад в средовую изменчивость. Например, для коэффициента интеллекта вклад общей среды оценивался в 30%. Однако впоследствии выяснилось, что такая оценка характерна лишь для детского возраста и начиная с 10-11 лет постоянно уменьшается, а к 18-20 годам практически приближается к нулю. Еще меньшие значения общесемейного компонента изменчивости были получены для личностных характеристик. Как ни странно, оказалось, что у детей, растущих в одной семье, среда формирует гораздо больше различий, чем сходства (Plomin R., Daniels D., 1987). Понятия "разделенная среда" и "семейная среда" не тождественны. В одной и той же семье родственники часто испытывают абсолютно различные средовые влияния. Дети часто отмечают, что родители по-разному относятся к каждому из них. В том числе и монозиготные близнецы, для которых более характерно совпадение оценок среды, чувствуют разное отношение к ним родителей. Даже общее экономическое положение семьи, которое определяет ее возможности, не означает полного совпадения средовых воздействий для всех членов семьи. Представим себе, что в какой-то семье собрана богатая библиотека. Корешки книг на полках, возможно, сходным образом воздействуют на зрительное восприятие родственников, но содержание книг будет одним из совпадающих средовых условий для членов семьи только в том случае, если одна и та же книга будет ими прочитана. Однако и в этом случае полного совпадения невозможно ожидать, поскольку каждый из родственников может особо обращать внимание на разные аспекты содержания. Только те элементы содержания, которые будут восприняты сходным образом каждым из родственников, могут быть отнесены к разделенной среде. Родственники могут разделять средовые условия и вне семьи. Например, если близнецы учатся в одном и том же классе, встречаются с общими друзьями, посещают вместе внешкольные занятия, ходят в театры и на концерты, то там они тоже разделяют многие средовые условия, которые могут формировать их сходство, но эти условия нельзя назвать семейной средой. Это внесемейная разделенная среда. К сожалению, современные статистические подходы не позволяют дифференцировать общие семейные и внесемейные факторы. Поэтому понятие общая (разделенная) среда не должно приравниваться к понятию семейная среда. Иногда, помимо двух основных средовых компонентов, в генетико-математические модели включают более специфические: общая среда, определяемая принадлежностью к одному поколению, специфическая среда сибсов, среда близнецов (разделяемая только сибсами или только близнецами) и т.п. Теперь несколько слов о компоненте средовой дисперсии, который называется различающейся (неразделенной, индивидуальной и т.п.) средой. К этому компоненту относятся все факторы, приводящие к различиям между родственниками. Если пару десятилетий назад считалось, что родственники, живущие в одной семье, испытывают скорее сходные средовые влияния, то в последнее время эта уверенность сильно поколебалась и даже почти исчезла, поскольку появляется все больше свидетельств противоположного рода. Говоря о различающейся среде как компоненте фенотипической дисперсии, нельзя не упомянуть, что сюда же входят различия между родственниками, возникающие за счет ошибок измерений: отсюда одно из обозначений - е или е2 (от английского error - ошибка). Теперь, познакомившись с субкомпонентами генетической и средовой дисперсии, мы можем записать исходную формулу разложения фенотипической дисперсии в более подробном виде: VP= VG + VE = ( VА + VD + VI ) + ( VB + VW ). Это уравнение справедливо для модели, предполагающей эффекты аддитивного взаимодействия генотипа и среды. В природе гораздо чаще существуют взаимодействия гораздо более сложные. Вполне вероятно, что количественные значения признака будут меняться неравномерно при переходе из одной среды в другую, причем отдельные генотипы будут по-разному реагировать на одни и те же изменения среды. Тогда, как мы уже знаем, на фенотипическую дисперсию признака будет влиять еще один компонент - генотип-средовое взаимодействие ( VGЕ ), и уравнение разложения фенотипической дисперсии примет вид VP = ( VА + VD + VI ) + ( VB + VW ) + VGЕ. Кроме того, при неравномерном распределении генотипов по средам имеет место генотип-средовая ковариация. Если индивиды подвергаются средовым воздействиям в соответствии со своими наследственными предрасположенностями, ковариация будет положительной и фенотипическая дисперсия увеличится. Если же среда будет действовать против наследственной предрасположенности, то появится отрицательная ковариация и фенотипическая дисперсия уменьшится. Добавим в уравнение фенотипической дисперсии компонент, соответствующий генотип-средовой ковариации, и тогда оно примет вид: VP = ( VА + VD + VI ) + ( VB + VW ) + VGЕ + 2covGE.
5.4. Ассортативность как фактор, влияющий на фенотипическую дисперсию
Приведенное только что уравнение не учитывает еще один фактор, влияющий на дисперсию фенотипов в популяции. Речь идет об ассортативности (избирательности браков), которой не всегда можно пренебречь. По некоторым признакам, по-видимому, браки заключаются совершенно случайно. Вряд ли кому-либо придет в голову искать себе партнера со сходным характером электроэнцефалограммы или отпечатков пальцев, хотя и по этим признакам, в принципе, ассортативность возможна. Однако в этом случае она будет вторичным следствием корреляции психофизиологических или морфологических особенностей с какими-либо социально-значимыми характеристиками, на которые и обращают внимание будущие супруги. Более вероятно обнаружить ассортативность, т.е. корреляцию между супругами, для некоторых важных психологических характеристик, например таких, как интеллект. В среднем корреляция супругов по коэффициенту интеллекта составляет 0,3-0,4. Однако на концах распределения - и со стороны низких, и со стороны высоких значений - уровень ассортативности повышается. Например, по данным Т.А. Думитрашку (Думитрашку Т.А., 1996; Думитрашку Т.А. и др., 1996), в группе с низким образованием и интеллектом наблюдается очень высокая ассортативность - около 0,7. При ассортативности первичной является фенотипическая корреляция супругов, корреляция же между их генотипами вторична. Высокая положительная ассортативность приводит к тому, что у потомков супругов с высокими или низкими значениями признака выше вероятность получить двойную дозу генов-усилителей или ослабителей. При положительной ассортативности генетическая дисперсия возрастает. Это является результатом вторичной (генетической) корреляции между супругами, если признак находится под контролем генов. Можно ожидать высокой ассортативности и для признаков, которые формируются в большей степени под влиянием социального окружения. Например, высокая положительная ассортативность обнаруживается для таких признаков, как религиозные убеждения, политические установки, уровень образования, социально-экономическое положение. Теоретически можно представить себе и отрицательную ассортативность, т.е. подбор супругов по противоположным качествам. Например, можно предположить, что мужчины, склонные к полноте, будут выбирать себе худеньких спутниц жизни, и наоборот. Отрицательная ассортативность приводит к уменьшению генетической дисперсии. Однако большинство исследований указывает на то, что браки чаще всего заключаются между людьми, похожими по многим фенотипическим признакам, что означает, что исследователи чаще имеют дело с положительной ассортативностью. Ассортативность нарушает принцип панмиксии (свободного и случайного скрещивания), лежащий в основе многих генетико-математических моделей, поэтому, если известно, что ассортативность по какому-либо признаку имеет место, в формулы фенотипических корреляций в парах родитель-ребенок добавляют определенные коэффициенты, вносящие соответствующие поправки на ассортативность (Хрестомат. 5.3). Статистически контролировать ассортативность возможно только в сложных психогенетических моделях, объединяющих несколько методов исследования, например, близнецовый и семейный.
5.5. Математическое моделирование в психогенетике
Метод подбора моделей. Чтобы выбрать подходящую модель, адекватно описывающую изменчивость изучаемого признака в популяции, необходимо оценить соответствие модели наблюдаемым данным. В качестве эмпирических данных в психогенетике используются фенотипические значения признака у различных типов родственников. Соответствие модели проверяется с помощью статистических критериев. Если одна из моделей отвергается, проверяется следующая и т.д., пока не будет обнаружена модель, дающая наименьшее расхождение с наблюдаемыми данными. Это так называемый метод перебора моделей. Существуют различные методы получения оценок соответствия: метод невзвешенных наименьших квадратов, метод взвешенных наименьших квадратов, метод максимального правдоподобия. Более подробно познакомиться с этими методами можно в соответствующих руководствах (см. список литературы к теме). Для неспециалистов не имеет смысла погружаться в дебри математических формул - достаточно понять общую идею. На выбор основной гипотезы о структуре фенотипической дисперсии влияют соображения простоты, здравый смысл и уже имеющиеся данные. Оптимальной считается ситуация, когда количество неизвестных меньше общего количества уравнений - избыточные уравнения дают больше степеней свободы для проверки приемлемости исходных допущений. Следует иметь в виду, что при однообразной выборке, где рассматриваются родственники одного-двух типов (например, только близнецы), сложные модели вряд ли смогут быть рассмотрены. Кроме того, важны и размеры самой выборки: чем она больше, тем легче сделать выбор между несколькими равно удовлетворительными моделями. Чем больше различных типов родственников включено в анализ, и чем больше их общее количество (размеры выборок), тем более сложные модели могут рассматриваться и уточняться. Например, исследование обычных семей, в которых представлены только пары родителей и детей или пары сибсов, не позволяет решить основной вопрос о разделении наследственного и средового компонентов фенотипической дисперсии, поскольку семейное сходство родственников может с равным успехом возникать как за счет общих генов, так и за счет общей среды. Исследование приемных детей и разлученных родственников более перспективно, поскольку можно предположить, что среда родственников не коррелирует. Это позволяет дифференцировать наследственные и средовые компоненты. Классическое исследование пар однояйцевых и двуяйцевых близнецов также может быть использовано для разделения наследственной и средовой составляющей фенотипической изменчивости, поскольку здесь предполагается равное сходство среды при различной степени генетического сходства. Основные экспериментальные схемы психогенетики будут более подробно рассматриваться в следующей теме. Сейчас же важно понять, что соответствующие модели подбираются на основании конкретных исследований различных типов родственников, и в каждом случае имеются свои возможности и ограничения в зависимости от категорий родственников, включенных в эксперимент. Например, близнецовый метод не позволяет оценить вклад доминирования в фенотипическую дисперсию, т.е. полную модель VP = VА + VD + VB + VW , однако трех- и двухкомпонентные модели при использовании метода близнецов вполне доступны для анализа.
Это:
средовая модель VP = VB + VW ,
простая генетическая модель VP = VА + VW,
генотип-культуральная модель VP = VА + VB + VW,
аддитивно-доминантная модель, где оба генетических эффекта (аддитивный и доминантный) оцениваются суммарно VP = (VА + VD) + VB + VW.
Анализ путей. Одним из современных методов моделирования в психогенетике является анализ путей. Сам метод был предложен еще в 30-х гг. ХХ в. С. Райтом. Метод основан на графическом представлении причинных и корреляционных связей, или путей, между переменными, включенными в описание модели. Как правило, на диаграмме путей квадратами и кружками с прописными буквенными символами внутри обозначают наблюдаемые переменные (т.е. доступные непосредственному измерению), например фенотипические значения изучаемого признака, и так называемые латентные переменные (недоступные измерению): генотипические значения, параметры общей и различающейся среды и т.п. (рис. 5.5).
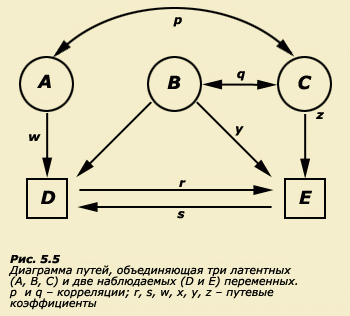
Кружки и квадраты соединяются между собой стрелками, которые обозначают предполагаемые связи между переменными. Если связь причинная, то стрелка имеет направление в одну сторону (от причины к следствию), если корреляционная - то в обе стороны, поскольку при корреляционных зависимостях не предполагается наличие причинно-следственных отношений, а лишь однонаправленность отклонений переменной от среднего. Рядом со стрелками, обозначающими пути от причины к следствию, располагаются путевые коэффициенты, а рядом со стрелками, предполагающими наличие корреляций - коэффициенты корреляции. Эти коэффициенты обозначаются соответствующими величинами (если они известны) или строчными буквами. В диаграмме путей зависимыми переменными являются те, которые подлежат объяснению (например, фенотипические характеристики), а независимыми - те, действием которых объясняются зависимые переменные и их связи (в психогенетике это чаще всего генетические и средовые параметры). Различные варианты диаграмм путей для близнецов приведены на рисунке 5.6 (а, б, в).
|
|
Рис. 5.6 |

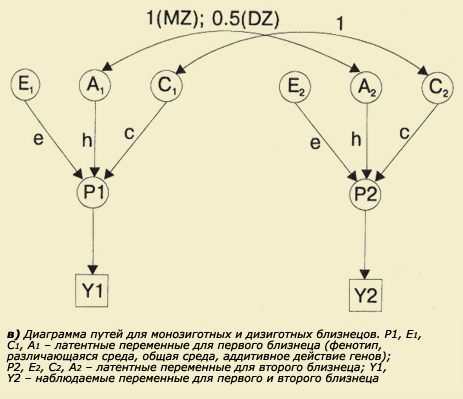
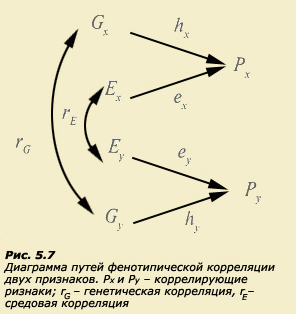
Существуют определенные правила построения и движения по путевым диаграммам, которые базируются на соответствующих статистических зависимостях. Все зависимости, выявленные с помощью метода коэффициентов путей, могут быть получены и при использовании традиционных (неграфических) статистических методов. Таким образом, метод путевого анализа, по существу, является представлением статистических зависимостей в виде диаграмм и позволяет получить такие же результаты, как и обычные методы (Хрестомат. 5.4). Моделирование сопряженной вариативности. Генетические и средовые корреляции. В психогенетике часто возникает задача одновременного изучения не одного, а нескольких признаков, подобно тому, как это делал Г. Мендель при дигибридном скрещивании. Однако Г. Мендель имел дело с альтернативными (качественными) признаками, нас же больше интересуют количественные мультифакториальные, к которым относятся почти все психологические характеристики. Известно, что многие психические особенности человека коррелируют между собой: это показатели вербального и невербального интеллекта, различные когнитивные характеристики и школьная успеваемость, особенности темперамента и личности и т.д. Возникает вопрос, не лежат ли за этими статистическими зависимостями зависимости причинные, определяемые сходными генетическими или средовыми механизмами реализации тех или иных психологических признаков. Например, можно представить себе, что существуют гены, которые контролируют синтез продуктов, влияющих на скоростные процессы передачи информации в центральной нервной системе. Естественно, уровень активности таких генов будет определять множество параметров работы мозга, что неизбежно должно сказаться и на всевозможных когнитивных характеристиках. В природе широко распространено явление плейотропии, т.е. множественного действия одного и того же гена. Вполне вероятно, что эффект плейотропии является основой возникновения корреляций между признаками. Возможно, существуют и средовые причины корреляций. Например, психическая депривация в раннем детстве может послужить причиной сопряженных изменений когнитивной и личностной сферы. Фенотипическая корреляция двух признаков может быть представлена в виде соответствующей диаграммы путей (рис. 5.7), на которой символами rG и rE обозначены соответственно генетические и средовые корреляции. Для оценки генетических и средовых корреляций в психогенетике разрабатываются соответствующие схемы исследований. Это одно из перспективных направлений в современной психогенетике, поскольку оно позволяет продвинуться в понимании происхождения не только вариативности самих фенотипов, но и их корреляции.
Структурное моделирование. Структурное моделирование представляет собой один из наиболее сложных современных методов. Применение этого метода требует соответствующей квалификации исследователя и наличия компьютерных программ, специально разработанных для этих целей (LISREL, EQS). Метод используется для анализа большого количества зависимых и независимых переменных, включенных в различные гипотезы исследования. Оценка и тестирование моделей при этом требует наличия больших выборок и современного компьютерного обеспечения. Более подробное знакомство с этим методом выходит за рамки данного учебника. Таким образом, чтобы приступить к построению модели и ее экспериментальной проверке, необходимо иметь гипотезу об участии тех или иных факторов в формировании изменчивости изучаемого признака в популяции и спланировать эксперимент таким образом, чтобы выборки изучаемых категорий родственников соответствовали возможностям проверки адекватности предполагаемой модели. Естественно, что экспериментаторы часто не располагают достаточными ресурсами для реализации сложных экспериментальных схем, включающих многие категории родственников и рассчитанные на тысячные выборки или длительное прослеживание (лонгитюды). Например, в России в связи с существованием законов о тайне усыновления практически невозможно пользоваться методом приемных детей. Поэтому, планируя исследование, научные коллективы, - а в современной психогенетике практически невозможно выполнить исследование в одиночку, - исходят из своих возможностей, соображений здравого смысла, простоты и руководствуются требованиями, предъявляемыми математической статистикой к доказательности результатов (Хрестомат. 5.5).
Выводы
В реальных популяциях лишь фенотипическая дисперсия может быть оценена непосредственно путем обработки эмпирического материала.
Для оценки непосредственно не измеряемых генетических и средовых компонентов дисперсии в количественной генетике применяются методы математического моделирования.
Простейшая генотип-средовая модель описывается уравнением: VP = VG + VE.
Генетическая дисперсия может быть представлена в виде субкомпонентов, включающих аддитивные эффекты, эффекты доминирования и эпистаза.
В рамках генотип-средовой модели чаще всего выделяют два основных типа средовой дисперсии. Один из них связан с возникновением различий между родственниками, другой - с формированием сходства.
Любые сходные ситуации внутри или вне семьи, в которой оказываются родственники, могут способствовать формированию их сходства. Такие средовые воздействия относятся к общей, или разделенной среде.
Любые элементы среды, которые не являются общими для родственников, способствуют формированию их различий и относятся к различающейся, или неразделенной среде.
Ассортативность (избирательность браков) по какому-либо признаку может влиять на оценки дисперсии. При положительной ассортативности, предполагающей сходство супругов, генетическая дисперсия возрастает.
При применении математического моделирования на выбор основной гипотезы о структуре фенотипической дисперсии влияют соображения простоты, здравый смысл и уже имеющиеся данные. Чем больше различных типов родственников включены в анализ, тем более сложные модели могут рассматриваться и уточняться.
Одним из современных методов моделирования в психогенетике является метод анализа путей. Этот метод является представлением статистических зависимостей в виде диаграмм.
Для анализа большого количества зависимых и независимых переменных, включенных в различные гипотезы исследования, используется структурное моделирование. Метод требует наличия больших выборок и современного компьютерного обеспечения.
Словарь терминов
Математическая модель
Построение модели
Метод подбора моделей
Анализ путей
Диаграмма путей
Коэффициент пути
Структурное моделирование
Общая и различающаяся среда
Генотип-средовое взаимодействие
Генотип-средовая ковариация (пассивная, реактивная, активная)
Ассортативность
Вариативность
Генетические корреляции
Средовые корреляции
Фенотипические корреляции
Фенотипическая структура популяции
Дисперсия
Аддитивное взаимодействие
Аддитивный компонент генетической дисперсии
Доминантный компонент генетической дисперсии
Эпистатический компонент генетической дисперсии
Общая среда
Различающаяся среда
Семейная среда
Разделенная среда
Неразделенная среда
Плейотропия
Мультифакториальные признаки
Структурное моделирование
Вопросы для самопроверки
Что такое биометрический (Гальтоновский) и генетический (Менделевский) подходы в генетике?
Какие генетические компоненты фенотипической дисперсии вам известны?
Что входит в понятие среды как компонента фенотипической изменчивости?
Почему межсемейный и внутрисемейный компоненты средовой дисперсии в настоящее время заменены общей и различающейся средой (shared and nonshared environment)?
Как вы представляете общую и различающуюся среду у родственников, живущих в одной семье? Приведите примеры.
Какие еще понятия употребляются для обозначения среды, формирующей сходство и различия между родственниками?
Каковы возможности психогенетики для изучения различных аспектов средовых влияний, формирующих психологические особенности?
Что такое генотип-средовое взаимодействие и какие его варианты вы можете назвать? Приведите примеры.
Что такое генотип-средовая ковариация и какие ее виды вы знаете? Приведите примеры.
Почему генотип-средовая корреляция может быть и положительной, и отрицательной? Приведите примеры.
Какие факторы могут приводить к увеличению и уменьшению сходства между родственниками? Приведите примеры.
Что такое ассортативность и как она может влиять на фенотипическую дисперсию?
Для чего в психогенетике используется математическое моделирование?
Из каких этапов слагается процесс моделирования?
Как в общем виде выглядит простейшая модель фенотипической структуры популяции?
На какие компоненты могут быть разложены генетическая и средовая изменчивость?
Какие варианты моделей могут быть построены на основе общей модели?
Что такое метод подбора моделей?
Представьте основную схему метода путей.
Что такое диаграмма путей?
Как путевой анализ может использоваться в психогенетике? Приведите простой пример.
Что такое фенотипические, генетические и средовые корреляции?
Что такое структурное моделирование (общее представление)?
Почему современная психогенетика требует работы с большими выборками и родственниками разной степени родства?
Раздел IV. Экспериментальные методы психогенетики
Основной целью психогенетических исследований является объяснение происхождения индивидуальных различий в психических и психофизиологических характеристиках человека. Для этого, во-первых, необходимо выяснить, какой вклад в изменчивость вносят наследственные и средовые факторы, и, во-вторых, по возможности попытаться объяснить механизмы влияния наследственности и среды на изучаемые характеристики. Какими методами пользуется современная психогенетика для ответа на эти вопросы? До недавнего времени в распоряжении психогенетики имелись лишь генетико-эпидемиологические подходы, позволяющие работать на уровне популяций. При этом возможности для поиска механизмов наследственности были весьма ограниченными. Сейчас в связи со стремительным прогрессом молекулярно-генетических технологий генетика человека, и психогенетика в том числе, обогатились множеством новых методических приемов, открывающих широкие перспективы для проникновения в природу наследственных механизмов, участвующих в формировании психических особенностей человека. В этом разделе будут рассматриваться, прежде всего, методы, традиционно используемые психогенетикой в рамках генетико-эпидемиологического подхода (близнецовый, семейный, метод приемных детей). Современные молекулярно-генетические методы будут рассмотрены менее подробно.
Тема 6. Измерение сходства и различий между родственниками
6.1. Семейное и генетическое сходство
6.2. Общие гены у родственников. Понятие о вероятности. Коэффициент родства
6.3. Способы количественной оценки фенотипического сходства между родственниками
6.4. Условия соответствия коэффициента корреляции коэффициенту родства
6.1. Семейное и генетическое сходство
Одним из основных методических приемов генетики является семейное сравнение, т.е. сравнение организмов, объединенных родством. Г. Мендель, проводя опыты с горохом, изучал поколения родителей и потомков. Ф. Гальтон, анализируя родословные знаменитостей, сравнивал людей, связанных родственными узами. Из предыдущего изложения понятно, что основные экспериментальные подходы психогенетики также связаны с изучением различных категорий родственников. Прежде чем начать знакомство с конкретными экспериментальными методами психогенетики, рассмотрим, что лежит в основе сходства и различий между родственниками, и остановимся на некоторых особенностях измерения сходства. Если мы предполагаем, что в основе изменчивости какого-либо признака лежит генетический компонент, то можно ожидать, что родственники будут более похожи по данному признаку, поскольку у них, скорее всего, имеются какие-то одинаковые гены, унаследованные от общего предка. У членов одной и той же семьи, помимо общих генов, как правило, имеются и общие средовые условия. Если признак небезразличен к влиянию среды, то на сходство родственников по этому признаку будут оказывать влияние не только общие гены, но и общая среда. Таким образом, семейное сходство включает в себя наследственный и средовой компоненты. Это создает определенные методические трудности в определении роли генов в формировании семейного сходства. Когда мы имеем дело с растениями или экспериментальными животными, мы легко можем нейтрализовать те воздействия, которые приводят к средовому сходству, поскольку имеем возможность выращивать потомство в любых необходимых условиях среды. Но мы не можем так поступить с семьями людей. Поэтому на формирование сходства между родителями и детьми, братьями и сестрами, близнецами и т.д. неизбежно будет влиять общая среда. Необходимо различать сходство семейное и сходство генетическое. Многие черты являются семейными, не будучи наследственными. Например, в религиозных семьях чаще всего и родители, и дети исповедуют определенную религию, посещают храм и совершают религиозные обряды, но вряд ли кто решится утверждать, что такого рода поведение наследуемо, поскольку наблюдается у членов одной семьи. Это типичный случай семейного, но не генетического сходства. Классическим стал пример семейного сходства, которое долгое время считалось генетическим, но при более детальном рассмотрении оказалось чисто средовым - это болезнь куру. Она представляет собой прогрессирующее нервное расстройство со смертельным исходом. До недавнего времени заболевание часто встречалось в одной из областей Новой Гвинеи. Болезнью чаще всего поражались члены одной семьи, причем основную часть пораженных составляли женщины. Данные статистики заболевания вполне соответствовали модели наследственной болезни с половыми различиями в экспрессивности (т.е. различной степени выраженности действия гена) у гетерозигот. Позднее выяснилось, что эта болезнь вызывается вирусом, поражающим мозг, а семейный характер заболевания объяснялся существованием в этих племенах традиций каннибализма: родственники умершего человека съедали кусочки его мозга и таким образом заражались вирусом куру. После введения законов, запрещающих каннибализм, заболевание было почти полностью ликвидировано (Хрестомат. 6.1). Семейное сходство очень часто интерпретируют как наследственное, не имея к тому достаточных оснований. Причиной этого являются предвзятые социальные установки. Например, семейное сходство по степени религиозности или политическим убеждениям обычно не считается наследственной чертой, но вместе с тем многие уверены, что сходство между родителями и детьми в музыкальных способностях является следствием влияния общих генов, хотя в последнем случае, в принципе, возможно и иное, чисто средовое, объяснение. Как правило, в музыкальных семьях дети воспитываются в определенных традициях, которые предполагают раннее приобщение детей к музыке и стимулируют развитие музыкальности. Таким образом, семейное сходство - это лишь то, что мы наблюдаем; объяснить же происхождение этого сходства мы сможем лишь тогда, когда нам удастся разделить генетическую и средовую общность родственников. Для этого в генетике человека применяют ряд экспериментальных схем, позволяющих разводить наследственное и средовое сходство и тем самым осуществлять количественную оценку наследуемости. Прежде чем подробно познакомиться с этими экспериментальными методами, рассмотрим, что лежит в основе генетического сходства между родственниками.
6.2. Общие гены у родственников. Понятие о вероятности. Коэффициент родства
Мы знаем, что при оплодотворении и образовании зиготы происходит объединение хромосом и генов, находившихся в материнской и отцовской гаметах. В результате каждый ген индивида оказывается представленным двумя аллелями - одним материнским и одним отцовским. Таким образом, половина аллелей потомка получена им от матери и половина - от отца. Если в этой же семье рождается второй ребенок, то он также получает половину аллелей от матери и половину от отца, однако вследствие процессов рекомбинации, которые имеют место при образовании гамет, в зиготу попадает уже иной наследственный материал, другое сочетание аллелей, и второй ребенок практически никогда не обладает таким же генотипом, что и первый. Все же оба потомка одних и тех же родителей будут нести какую-то часть одинаковых генов. Число общих генов у потомков одних и тех же родителей определяется чистой случайностью, поскольку, как мы уже знаем, при образовании гамет в первом делении мейоза гомологичные хромосомы распределяются по гаметам случайным образом. Однако случайность не есть нечто неопределенное. Мерой случайности является вероятность. Все мы сталкиваемся в жизни со случайными событиями. Подбрасывая монетку, мы знаем, что сторона, на которую она упадет, определяется случайностью, но если продолжить опыт с монеткой много раз, то мы заметим, что примерно в половине случаев выпадет "орел", а в половине - "решка". В случае с монеткой вероятность того, что выпадет орел, равняется одному шансу из двух возможных. Говорят, что в этом случае вероятность события составляет 1/2. Если бросать игральный кубик, то вероятность того, что выпадет одна из граней, например "шесть", составит 1/6. Вообще вероятность какого-либо события выражается в виде дроби, в числителе которой стоит число благоприятных шансов, а в знаменателе - общее число шансов всех исходов события. При образовании гамет также происходят вероятностные события. Когда мы рассматривали дигибридное скрещивание в опытах Г. Менделя, то видели, что с равной вероятностью могут образовываться четыре типа гамет (см. табл 3.3 из темы 3). Иными словами, вероятность образования гамет с аллелями АВ, так же как и с остальными тремя сочетаниями аллелей (Ab, aB, ab), будет равна 1/4. В результате вероятностных событий, происходящих при образовании гамет, родные братья и сестры (сибсы) получают какое-то количество одинаковых аллелей. Поясним это на примере. Предположим, родители обладают различными аллелями одного и того же гена. Пусть у отца имеются аллели АВ, а у матери - СD. Гаметы отца могут нести либо аллель А, либо аллель В. Каждый из сибсов с равной вероятностью может получить как аллель А, так и аллель В. Понятно, что в среднем половина потомков будут нести аллель А и половина - аллель В. Соответственно вероятность того, что оба сибса будут обладать одним и тем же аллелем, составит 1/2. То же самое справедливо и для материнских аллелей - С и D (табл.6.1).
Таблица 6.1
Сочетание материнских и отцовских аллелей у потомков

Вероятность того, что двое людей обладают одинаковыми аллелями, называется коэффициентом родства. Коэффициент родства соответствует доле идентичных аллелей, имеющихся у двух индивидов, благодаря их происхождению от общего предка. Коэффициенты родства рассчитываются теоретически на основе теории вероятностей и математической статистики. Приведенный пример является лишь наглядной иллюстрацией. Коэффициент родства для сибсов, как мы видели, составляет 1/2, т.е. в среднем у сибсов 1/2 генов идентичны и получены от одного общего предка. Такой же коэффициент родства характерен и для пар родитель-потомок. Приведенный пример может служить иллюстрацией и в этом случае. Понятно, что только половина потомков будут нести тот же аллель, что и у одного из родителей. В нашем примере коэффициент родства родителей равен 0, т.к. аллели матери и отца не совпадают. В реальной жизни, особенно при близкородственных браках (например, между двоюродными сибсами), родители также могут обладать одинаковыми аллелями. Так, коэффициент родства между двоюродными сибсами составляет 1/8. Это означает, что в среднем 1/8 генов получены ими от общего предка. Чем отдаленнее родство, тем меньше общих генов можно обнаружить в парах родственников. В таблице 6.2 приведены теоретически рассчитанные коэффициенты родства для различных пар родственников.
Таблица 6.2.
Теоретически рассчитанные коэффициенты родства для различных пар родственников
Типы родственников |
Теоретически рассчитанные коэффициенты родства |
Монозиготные близнецы |
1 |
Дизиготные близнецы, сибсы (братья и сестры), родители-дети |
1/2 |
Деды /бабушки-внуки, дяди /тети-племянники, полусибсы* |
1/4 |
Двоюродные сибсы |
1/8 |
В большинстве культур браки между близкими родственниками запрещаются. Это связано с тем, что при близкородственных браках выше вероятность встречи рецессивных аллелей, связанных с различными аномалиями. В гомозиготном состоянии такие аллели приводят к возникновению патологических отклонений. При неродственных браках вероятность проявления патологических аллелей гораздо ниже (Хрестомат. 6.2 и 6.3).
6.3. Способы количественной оценки фенотипического сходства между родственниками
6.3.1. Конкордантность
6.3.2. Корреляция
6.3.3. Регрессия
Итак, сходство между родственниками возникает, с одной стороны, за счет общих генов, а с другой стороны, за счет общей среды. Чтобы количественно оценить степень сходства в парах родственников, чаще всего используют конкордантность и корреляцию. В некоторых случаях пользуются также регрессией.
6.3.1. Конкордантность
При анализе сходства/различия альтернативных признаков используют оценки конкордантности. Чаще всего оценки конкордантности используются в клинической психогенетике при изучении причин различных психических заболеваний или отклонений в развитии. Пары родственников называются конкордантными, если оба имеют или не имеют данный признак. Соответственно, дискордантными называются пары, в которых один обладает данным признаком, а другой - нет. Для оценки конкордантности подсчитывается процент совпадения альтернативных признаков в парах родственников. Те индивиды, которые обладают интересующим нас признаком, называются пробандами. Исследованию подлежат пробанды и их родственники различной степени родства (близнецы, сибсы, родители, дети и т.п.). Например, при изучении наследственности шизофрении в качестве пробандов могут подбираться больные близнецы, как монозиготные (МЗ), так и дизиготные (ДЗ). Предположим, в таком исследовании было получено, что для 20 пробандов (МЗ близнецов), больных шизофренией, в 15 случаях был болен и партнер пробанда, т.е. пары оказались конкордантными по шизофрении, тогда как в оставшихся 5 парах (дискордантных по шизофрении) партнеры оказались здоровыми. В данном случае конкордантность (С) равна: СМЗ = (15/20)100 = 75%. В то же время из 20 пробандов ДЗ близнецов лишь у 10 оказался болен и другой член пары, т.е. на 10 конкордантных пришлось столько же дискордантных пар. В этом случае конкордантность ДЗ близнецов равна: СДЗ = (10/20)100 = 50%. В результате такого исследования можно сделать вывод, что риск заболевания шизофренией выше для родственников, связанных более тесным родством, т.е. имеющих больше общих генов. Если результаты подобных исследований оказываются статистически достоверными, можно предполагать наличие наследственной обусловленности заболевания. Коэффициенты конкордантности помогают определить риск заболеваемости для различных категорий родственников. Например, если для сибсов конкордантность по шизофрении составляет 10%, можно считать, что риск заболевания шизофренией у человека, имеющего брата или сестру, страдающих этим заболеванием, составит 1 на 10 случаев. Как правило, конкордантность для родственников сравнивается с встречаемостью болезни в популяции. Например, если было обнаружено, что заболеваемость шизофренией для родственников первой степени родства составляет 10%, а в популяции встречаемость этой болезни всего 1%, можно говорить о более высоком риске заболевания у родственников. В таблице 6.3. приведены частоты заболеваемости шизофренией для различных категорий родственников.
Таблица 6.3
Риск заболевания шизофренией у родственников больных
Родство с больным |
Коэффициент родства |
Частота* заболеваемости шизофренией (%) |
Неродственники |
0,00 |
0,85 |
Сводные сибсы** |
0,00 |
1,80 |
Полусибсы |
0,25 |
3,20 |
Сибсы |
0,50 |
7,0-15,0 |
Родители |
0,50 |
5,0-10,3 |
Дети*** |
0,50 |
7,0-16,4 |
Внуки |
0,25 |
3,0-4,3 |
Племянники или племянницы |
0,25 |
1,8-3,9 |
Двоюродные братья или сестры |
0,125 |
1,8-2,0 |
Сопоставление оценок конкордантности МЗ и ДЗ близнецов дает возможность оценить долю влияния наследственных факторов на вариативность исследуемого признака, т.е. коэффициент наследуемости h2. Для этого можно воспользоваться формулой Хольцингера: h2=(СМЗ - СДЗ) / (100 - СДЗ) = (75 - 50) / (100 - 50) = 0,5. Итак, в приведенном примере коэффициент наследуемости (в широком смысле слова) равен 0,5.
6.3.2. Корреляция
При анализе количественных признаков сходство между родственниками оценивается с помощью корреляции. Мы уже упоминали об этом, когда обсуждали проблему ассортативности. Сейчас поговорим о корреляциях более подробно. В статистике коэффициент корреляции обычно используется для оценки меры связи между двумя величинами. Так, можно, например, задать вопрос, существует ли связь между двумя количественными признаками у человека, например, между густотой волос и ростом. Здесь возможны три варианта: 1) чем гуще волосы, тем выше рост, 2) чем гуще волосы, тем рост ниже, 3) эти признаки никак не связаны между собой. Если верно последнее утверждение, то мы бы сказали, что эти признаки не коррелируют. В первом случае можно говорить о положительной корреляции, во втором - об отрицательной. Основной принцип подсчета корреляции заключается в следующем. Возьмем, например, такие признаки, как рост человека и его вес. Предположим, что у группы индивидов мы провели соответствующие измерения и занесли данные в таблицу (табл. 6.4 ).
Таблица 6.4
Пример данных для вычисления коэффициента корреляции между ростом и весом
Индивид |
Рост(см) |
Отклонение от среднего |
Вес (кг) |
Отклонение от среднего |
А |
165 |
-7 |
58 |
-14 |
Б |
168 |
-4 |
64 |
-8 |
В |
170 |
-2 |
68 |
-4 |
Г |
174 |
+2 |
76 |
+4 |
Д |
176 |
+4 |
80 |
+8 |
Е |
179 |
+7 |
86 |
+14 |
Среднее |
172 |
|
72 |
|
Рассматривая
таблицу, мы можем заметить, что отклонение
роста каждого человека от средней
величины прямо пропорционально таким
же отклонениям, относящимся к его весу.
В этом примере рост и вес демонстрируют
максимальную положительную корреляцию,
величина которой равна +1,0. Если мы
расположим значения в одном из столбцов
в обратном порядке, то получим отрицательную
корреляцию с величиной коэффициента,
равной -1,0. Если мы в случайном порядке
перемешаем все цифры, то корреляция
будет близка к 0.
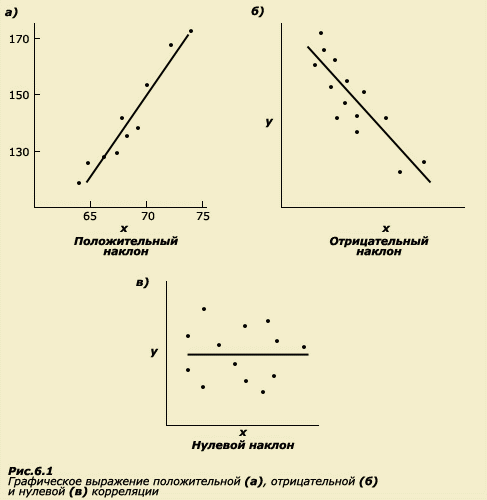 Графически
положительная корреляция между двумя
величинами может быть представлена в
виде линии с положительным наклоном
(рис. 6.1а), при этом на осях Х и Y откладываются
значения коррелируемых признаков;
отрицательная корреляция может быть
представлена в виде линии с отрицательным
наклоном (рис. 6.1б), отсутствие корреляции
выражается в отсутствии наклона
соответствующей линии (рис. 6.1в). Таким
образом, величина корреляции говорит
нам о том, насколько отклонения от
средней одной величины совпадают с
отклонениями другой. (Напомним, что все,
что связано с отклонениями от средних
величин - это область, близкая к проблемам
вариативности и измерениям дисперсии.)
Однонаправленный характер отклонений
приводит к возникновению высокой
положительной корреляции. Вместе с тем
величина коэффициента корреляции не
несет никакой информации об абсолютных
величинах двух признаков. Взглянув на
таблицу, мы убедимся, что в колонках
цифр абсолютные значения роста и веса
отличаются примерно на сто единиц. Две
переменные могут идеально коррелировать
друг с другом, даже если каждое значение
одной значительно больше, чем каждое
значение другой. Это обстоятельство
имеет непосредственное отношение к
пониманию значений корреляций в оценке
сходства между родственниками.
Графически
положительная корреляция между двумя
величинами может быть представлена в
виде линии с положительным наклоном
(рис. 6.1а), при этом на осях Х и Y откладываются
значения коррелируемых признаков;
отрицательная корреляция может быть
представлена в виде линии с отрицательным
наклоном (рис. 6.1б), отсутствие корреляции
выражается в отсутствии наклона
соответствующей линии (рис. 6.1в). Таким
образом, величина корреляции говорит
нам о том, насколько отклонения от
средней одной величины совпадают с
отклонениями другой. (Напомним, что все,
что связано с отклонениями от средних
величин - это область, близкая к проблемам
вариативности и измерениям дисперсии.)
Однонаправленный характер отклонений
приводит к возникновению высокой
положительной корреляции. Вместе с тем
величина коэффициента корреляции не
несет никакой информации об абсолютных
величинах двух признаков. Взглянув на
таблицу, мы убедимся, что в колонках
цифр абсолютные значения роста и веса
отличаются примерно на сто единиц. Две
переменные могут идеально коррелировать
друг с другом, даже если каждое значение
одной значительно больше, чем каждое
значение другой. Это обстоятельство
имеет непосредственное отношение к
пониманию значений корреляций в оценке
сходства между родственниками.
При оценке сходства между родственниками измеряют не два признака у одних и тех же людей, а один и тот же признак в парах родственных индивидов. Ими могут быть близнецы, сибсы, родители и дети и даже неродственники, живущие в одной семье (имеются в виду семьи с приемными детьми) и т.д. Принцип же подсчета корреляций такой же. Важны не абсолютные величины признака, а отклонения от средней. Если отклонения однонаправленны, то и корреляция между родственниками будет высокой (Хрестомат. 6.4). В зависимости от типа родственников используется тот или иной тип коэффициента корреляции. В тех случаях, когда оценивается сходство между парами родственников, принадлежащих разным поколениям (родитель-ребенок, дед-внук и т.д.), используют межклассовый коэффициент корреляции, предложенный Карлом Пирсоном. Для оценки степени сходства между близнецами и сибсами используется внутриклассовый коэффициент корреляции
![]() .
.
Так же как и в случае с конкордантностью, сопоставление коэффициентов корреляции МЗ и ДЗ близнецов дает возможность вычислить коэффициент наследуемости и соответственно оценить долю наследуемости в общей вариативности признака. Для оценки коэффициента наследуемости можно воспользоваться формулой Игнатьева: h2=2(rМЗ - rДЗ). |
Итак, в генетике поведения мерой сходства между родственниками чаще всего является корреляция, которая не предполагает сходства в абсолютных величинах признака. Однако нередко в обыденном понимании сходство между родственниками отождествляется со сходством в абсолютных или средних величинах. Такое понимание сходства может приводить к неверной интерпретации получаемых результатов. Рассмотрим гипотетический пример, который иллюстрирует возможность возникновения некоторых заблуждений по поводу роли наследственных и средовых факторов в возникновении индивидуальных различий. Предположим, что группа детей из бедных семей была усыновлена группой родителей из средних или состоятельных слоев общества. Приемные родители по своему интеллектуальному потенциалу и материальным возможностям смогли обеспечить детям идеальные возможности для развития. Допустим, что, когда дети выросли, было произведено измерение коэффициента интеллекта у самих детей, а также у их биологических и приемных матерей. Предположим, что данные этого измерения оказались следующими (табл. 6.5).
Таблица 6.5
Показатели интеллекта у приемных детей и их родителей
Семья |
Дети |
Биологические матери |
Матери-усыновители |
А |
105 (-2) |
95 (-2) |
107 (0) |
Б |
106 (-1) |
96 (-1) |
105 (-2) |
В |
107 (0) |
97 (0) |
109 (+2) |
Г |
108 (+1) |
98 (+1) |
106 (-1) |
Д |
109 (+2) |
99 (+2) |
108 (+1) |
|
среднее x=107 |
среднее x=97 |
среднее x=107 |
Примечание. Величины в скобках есть отклонения от среднего.
В настоящем примере получается идеально высокая положительная корреляция (равная +1) между детьми и их биологическими матерями, поскольку в обеих этих группах наблюдается однонаправленность отклонений от среднего, что и создает высокую положительную корреляцию. Корреляция с матерями-усыновителями будет гораздо ниже. Однако если мы взглянем на абсолютные величины IQ, то легко можем заметить, что приемные дети как группа гораздо ближе к группе их матерей-усыновителей. Действительно, средние величины интеллекта в этих группах совпадают, тогда как в группе биологических матерей они гораздо ниже. Поскольку приемные дети имеют общую среду с усыновившими их матерями и не имеют таковой с их биологическими матерями, а по абсолютным величинам IQ оказываются гораздо ближе к матерям-усыновителям, сам собой напрашивается вывод о средовой детерминации интеллекта. Вместе с тем высокая корреляция между биологическими родственниками и отсутствие таковой у людей, не связанных генетическим родством, свидетельствуют о высокой наследуемости признака. В этом примере содержится основной парадокс данных количественной генетики: высокая наследуемость вполне может сочетаться с чувствительностью конкретных генотипов к средовым изменениям. Усыновление в семьи с более благоприятной средой вполне может привести к тому, что дети будут опережать своих биологических матерей по уровню интеллекта. Вместе с тем легко заметить, что хотя дети оказались на другом уровне шкалы, они сохранили свои ранговые места в соответствии со своим биологическим происхождением. Таким образом, даже если индивидуальные особенности детей идеально коррелируют с особенностями их биологических родителей, эти дети как группа в среднем могут больше походить на родителей-усыновителей. В нашем примере данные генетики поведения говорят о том, что вариативность интеллекта в популяции в основном обусловлена вариативностью генотипов, а не вариативностью сред. Это тот вывод, который может сделать генетик. Но психолог, измерив средние величины интеллекта в группах детей и их приемных и биологических родителей, имеет полное право сказать, что наблюдаемое сходство по интеллекту между приемными детьми и их родителями-усыновителями обусловлено общей средой (общая среда в нашем примере только у приемных детей и матерей-усыновителей). Как ни странно, но выводы генетика и психолога абсолютно не противоречат друг другу, но для генетика мерой сходства является корреляция, которая указывает на то, что показатели интеллекта у родственников в популяции ковариируют, а для психолога такой мерой является сходство в абсолютных значениях или средних величинах интеллекта в группах приемных детей и их матерей-усыновителей, которое говорит о возможности среды влиять на фенотип в индивидуальном развитии. Среда, влияя на индивидуальное развитие каждого конкретного ребенка, приводит к увеличению сходства в абсолютных величинах признака между детьми и родителями-усыновителями. Однако наблюдаемые межиндивидуальные различия по интеллекту в данном примере должны быть объяснены генетическими различиями между индивидами. Основанием для этого и является высокая корреляция между биологическими родственниками.
6.3.3. Регрессия
Коэффициент корреляции не предполагает наличия какой-либо причинно-следственной зависимости между переменными. Если с увеличением переменной х наблюдается рост переменной y, то мы констатируем наличие положительной корреляции между этими переменными, однако на этом основании мы еще не можем утверждать, что увеличение у является следствием увеличения х. Например, в городах мы можем обнаружить, что количество кафе и столовых положительно коррелирует с количеством больниц и поликлиник. Естественно, из этого не следует, что общественное питание является причиной высокой заболеваемости населения, что и приводит к появлению новых лечебных учреждений. Просто количество тех и других заведений определяется численностью населения города: чем больше жителей, тем больше необходимо как кафе, так и поликлиник. Отсюда и высокая положительная корреляция. Таким образом, коэффициент корреляции позволяет определить лишь наличие статистической связи между переменными, но не позволяет установить причину этой связи. В статистике существует и другой метод измерения связи, который предполагает оценку зависимости одной переменной от другой. Это метод линейной регрессии. Метод регрессии позволяет предсказать, какую величину будет иметь зависимая переменная у при любых значениях независимой переменной х. Речь фактически идет об уравнении регрессии уi = a + b( xi - x ), в котором нам необходимо определить величины а и b соответствующей линии регрессии. Независимая переменная (xi - x) представляет собой отклонение признака данного индивида от среднепопуляционной величины. Линия регрессии строится таким образом, чтобы квадраты расстояний между ней и всеми точками на графике были минимальными (рис. 6.2 и 6.3а, б.). Коэффициент b называется коэффициентом регрессии у на х. Если коэффициент регрессии достоверно выше 0, то говорят о зависимости переменной у от переменной х. В количественной генетике регрессия применяется в основном в исследованиях родителей и детей. Часто используют одновременно и регрессию, и корреляцию. Регрессия имеет ряд преимуществ по сравнению с корреляцией, применение которой ограничено рядом условий, о которых речь пойдет в следующем разделе. Регрессия менее чувствительна к этим условиям.
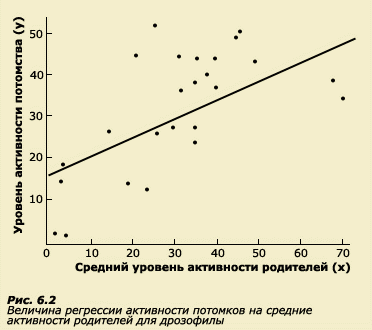
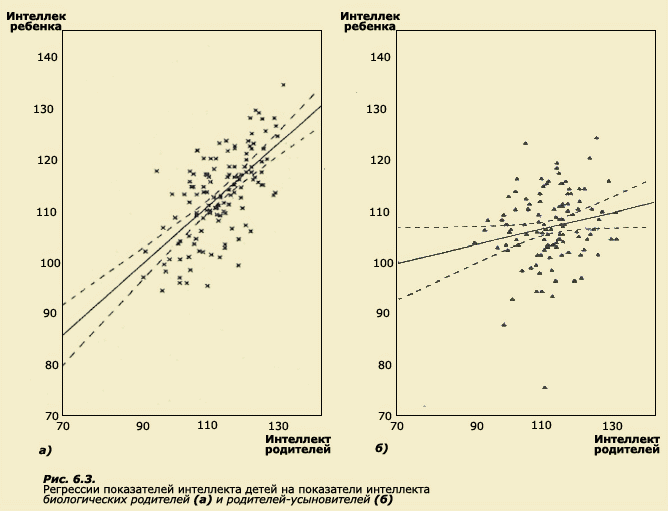
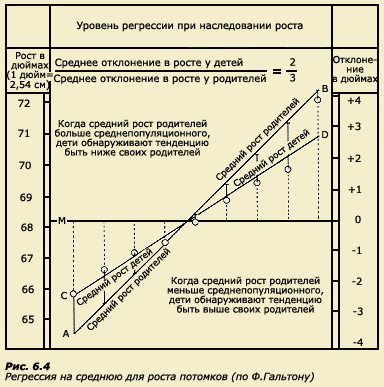
Термин регрессия был введен Ф. Гальтоном при исследовании роста у родителей и детей. В этой работе Ф. Гальтон отметил, что у более высоких отцов сыновья также отличаются высоким ростом, но все же они несколько ниже своих отцов. У отцов небольшого роста сыновья так же невысоки, но они обычно выше своих отцов. Таким образом, рост детей как бы стремится к популяционной средней (рис. 6.4). Это явление Ф. Гальтон назвал регрессией на среднюю.
6.4. Условия соответствия коэффициента корреляции коэффициенту родства
Как мы уже говорили,
выявление степени внутрисемейного
сходства является основным методом
количественной генетики. Основоположники
биометрической
генетики, начиная с Ф.
Гальтона, ввели этот метод в обиход
генетических исследований, практически
ничего не зная о механизмах, приводящих
к появлению сходства между родственниками.
Сейчас мы знаем, что в основе фенотипического
сходства лежит сходство генетическое,
обусловленное общностью генов, полученных
от одного предка (если, конечно, признак
не целиком обусловлен средой, а все же
зависит от действия генов). В 1918 г.
английский генетик и статистик Р.
Фишер показал, что результаты,
полученные основоположниками
биометрической генетики, могут быть
объяснены именно с позиций менделевской
генетики. Можно сказать,
что в этом году две независимо развивавшиеся
ветви генетики - менделевская и
гальтоновская - наконец нашли путь к
объединению. Заслуга Р. Фишера в том,
что он показал, что ожидаемая степень
сходства между родственниками объясняется
полигенным наследованием, т.е. детерминацией
признака не одним, а многими генами, и
при определенных допущениях, о которых
речь пойдет ниже, она соответствует
коэффициентам родства. В основе этого
лежат вероятностные процессы, происходящие
при расщеплении и рекомбинации аллелей,
открытые Г.
Менделем. Оказалось, что
регрессия (напомним, что это термин Ф.
Гальтона) родителя к ребенку или ребенка
к родителю, или сибса к сибсу, или других
пар родственников соответствует доле
общих генов у этих родственников, т.е.
коэффициенту родства. Коэффициент
корреляции равен корню квадратному из
произведения двух регрессий, т.е.
регрессии первой величины по второй и
второй величины по первой
![]() .
Коэффициент корреляции будет эквивалентен
регрессии, когда две регрессии (например,
ребенка к родителю и родителя к ребенку)
равны. Таким образом, при определенных
условиях коэффициент корреляции в парах
родственников должен соответствовать
доле общих генов, или коэффициенту
родства.
.
Коэффициент корреляции будет эквивалентен
регрессии, когда две регрессии (например,
ребенка к родителю и родителя к ребенку)
равны. Таким образом, при определенных
условиях коэффициент корреляции в парах
родственников должен соответствовать
доле общих генов, или коэффициенту
родства.
Каковы же эти условия, или допущения, при которых реально наблюдаемое внутрисемейное сходство должно соответствовать теоретически рассчитанному? Условия эти сводятся к следующему:
исследуемый признак детерминирован исключительно генотипом, условия среды никак не сказываются на фенотипе;
гены обладают чисто аддитивным эффектом, отношения доминантности и рецессивности, эффекты эпистаза не имеют места;
у мужа и жены отсутствует корреляция по изучаемому признаку, т.е. брак является случайным в отношении изучаемого признака. Иначе говоря, не наблюдается ассортативности по исследуемому признаку.
Итак, существует три условия, при точном соблюдении которых реально получаемые корреляции между родственниками должны совпадать с теоретически рассчитанными коэффициентами родства. Из всех количественных признаков человека лучше всего удовлетворяют этим условиям дерматоглифические узоры на пальцах. Каждый человек имеет свой индивидуально специфический характер дерматоглифических борозд (рис. 6.5). Этот рисунок закладывается на ранних этапах эмбриогенеза и впоследствии не претерпевает никаких изменений, т.е. не испытывает средовых модификаций. Распределение индивидов по числу борозд соответствует нормальному, гауссову, следовательно, мы можем предположить, что здесь имеет место чисто аддитивное наследование. Браки по такому признаку, естественно, не могут быть избирательными.

В отличие от корреляции, регрессия менее чувствительна к ассортативности, поэтому регрессией можно пользоваться в семейных исследованиях, когда предполагается избирательность браков по изучаемому признаку. Регрессия позволяет также выявлять так называемый материнский эффект, т.е. влияние фенотипа матерей на фенотип потомства. При материнском эффекте регрессия потомков к матерям значительно больше, чем регрессия к отцам. По регрессии можно судить и о наличии эффектов доминирования. Обычно для изучения наследуемости стараются применять различные методы: вычисление коэффициентов корреляции между различными группами родственников (родители-потомки, сибсы, полусибсы, матери-дочери и т.д.) и вычисление коэффициентов регрессии тем или иным способом.
Выводы
Сходство между родственниками, проживающими вместе, возникает за счет общих генов и общей среды и, следовательно, включает в себя наследственный и средовой компоненты. Необходимо различать сходство семейное и сходство генетическое.
У родственников всегда имеются общие гены, полученные ими в силу происхождения от общих предков.
Число общих генов у потомков одних и тех же родителей определяется чистой случайностью. Мерой случайности является вероятность.
При образовании половых клеток (гамет) происходят вероятностные события. В результате родные братья и сестры получают какое-то количество одинаковых аллелей.
Вероятность того, что двое людей обладают одинаковыми аллелями, называется коэффициентом родства. Коэффициенты родства для различных категорий родственников рассчитываются теоретически на основе теории вероятностей и математической статистики.
В психогенетических исследованиях для количественной оценки сходства между родственниками пользуются коэффициентами конкордантности, корреляции и регрессии.
Коэффициент конкордантности используют при анализе сходства и различий между родственниками по альтернативным признакам, например по наличию или отсутствию какого-либо заболевания или отклонения. По коэффициентам конкордантности родственников разной степени родства можно судить о возможной наследуемости признака и риске заболевания для родственников.
Коэффициент корреляции используют при анализе сходства и различий между родственниками по количественным признакам. Высокая корреляция указывает на преобладание однонаправленных отклонений значения изучаемого признака у родственников от выборочной средней. Это не предполагает обязательного сходства в абсолютных величинах признака в парах родственников.
Коэффициент регрессии чаще всего применяется при исследованиях родителей и детей и, в отличие от коэффициента корреляции, может служить мерой причинно-следственной зависимости между переменными. Регрессия при определенных условиях соответствует доле общих генов у родственников, т.е. коэффициенту родства.
Если регрессии родителя к ребенку и ребенка к родителю совпадают, то коэффициент регрессии будет эквивалентен коэффициенту корреляции.
При определенных условиях теоретически рассчитанное сходство между родственниками (коэффициенты родства) совпадает с эмпирически полученными коэффициентами корреляции и регрессии. Эти условия таковы:
исследуемый признак является количественным и в его детерминации принимают участие только полигены, условия среды не влияют на признак;
гены обладают чисто аддитивным (суммирующимся) эффектом;
по данному признаку отсутствует ассортативность (избирательность браков).