

7.3. Методы доступа внешней модели (представления пользователя)
Методы доступа, описывающие логические взаимосвязи, называются методами доступа внешней модели. На основе модели данных, используемой СУБД (например, реляционной, иерархической, сетевой или какого-либо их сочетания), могут быть получены различные представления пользователя (внешние модели), описывающие взаимосвязь (взаимосвязи) между различными частями физической записи.
Методы доступа внутренней модели обеспечивают вхождение в базу данных, а методы внешней модели выполняют дальнейший поиск записей базы данных или их частей. С помощью взаимосвязей между записями методы доступа внешней модели осуществляют их хранение или поиск. Взаимосвязи между записями определяются моделью данных, используемой конкретной СУБД в качестве основной структуры данных. Для отыскания записи можно воспользоваться несколькими методами доступа внешней модели, но для хранения – только одним.
Чтобы выяснить взаимосвязи между двумя записями, рассмотрим такую ситуацию.
Предположим, имеются две записи Х и Y. Запись Х уже хранится в базе данных, а запись Y должна в ней храниться. Или другой случай: запись Х найдена, а запись Y необходимо найти. При наличии какой-либо взаимосвязи между двумя записями, Х и Y, для иерархической и сетевой моделей данных она может задаваться следующими способами:
1. Взаимосвязь полей упорядочения. Две записи связаны по полю упорядочения ключа, если поле упорядочения ключа записи Y следует за полем упорядочения ключа записи X.
2. Взаимосвязь по подчиненности. Между записями Х и Y существует взаимосвязь по подчиненности, если запись Y – подчиненная по отношению к записи X.
Иерархическая модель данных. Запись Y может быть порожденной, а запись Х – исходной.
Сетевая модель данных. Y может быть записью-членом, а Х – записью-владельцем.
3. Взаимосвязь по порождению. Это – взаимосвязь по подчиненности, здесь Х и Y меняются ролями.
Иерархическая модель данных. Найденная запись Х может быть порожденной, а запись Y, которую необходимо найти, – исходной.
Сетевая модель данных. Найденная запись Х может быть записью-членом, а запись Y, которую необходимо найти, – записью-владельцем.
4. Взаимосвязь «рядом». Эта взаимосвязь просто определяет необходимость хранения записи Y рядом с записью X.
Иерархическая модель данных. Наличие или отсутствие между записями Х и Y взаимосвязи полей упорядочения, взаимосвязи по подчиненности или взаимосвязи по порождению не играет никакой роли.
Сетевая модель данных. Наличие или отсутствие между записями Х и Y взаимосвязи полей упорядочения, взаимосвязи по подчиненности или взаимосвязи по владению не играет никакой роли.
Существуют четыре типа методов доступа внешней модели, основанных на четырех типах взаимосвязей между записями. Их следует оценивать с точки зрения организации как хранения, так и поиска. Мы рассмотрим методы доступа внешней модели для иерархической и сетевой моделей данных.
1. Метод доступа с использованием полей упорядочения. Подлежащая хранению запись Y – это запись, поле упорядочения которой следует за полем упорядочения записи X.
Иерархическая модель данных. Записи Х и Y принадлежат к одному и тому же типу узла. При отсутствии экземпляра узла, с которым можно установить взаимосвязь, понятие следующего по порядку экземпляра теряет смысл.
Сетевая модель данных. Х и Y принадлежат к одному и тому же типу записи. При отсутствии экземпляра записи, с которым можно установить взаимосвязь, понятие следующего по порядку экземпляра .теряет смысл. Перечислим методы доступа, используемые для установления взаимосвязей на основании поля упорядочения.
К предшествующему.
Иерархическая модель данных. Либо включить (хранить), либо найти экземпляр узла Y, PRIOR (ПРЕДШЕСТВУЮЩИЙ) экземпляру узла X.
Сетевая модель данных. Либо включить (хранить), либо найти экземпляр записи Y, PRIOR (ПРЕДШЕСТВУЮЩИЙ) экземпляру записи X.
К следующему.
Иерархическая модель данных. Либо включить (хранить), либо найти экземпляр узла Y, NEXT (СЛЕДУЮЩИЙ) за экземпляром узла X. Сетевая модель данных. Либо включить (хранить), либо найти экземпляр записи Y, NEXT (СЛЕДУЮЩИЙ) за экземпляром записи X.
2. Метод доступа по подчиненности. Метод доступа по подчиненности может использоваться для хранения и поиска подчиненных узлов для иерархической модели данных и записей для сетевой модели данных. Можно определить следующие условия (рис. 7.8).
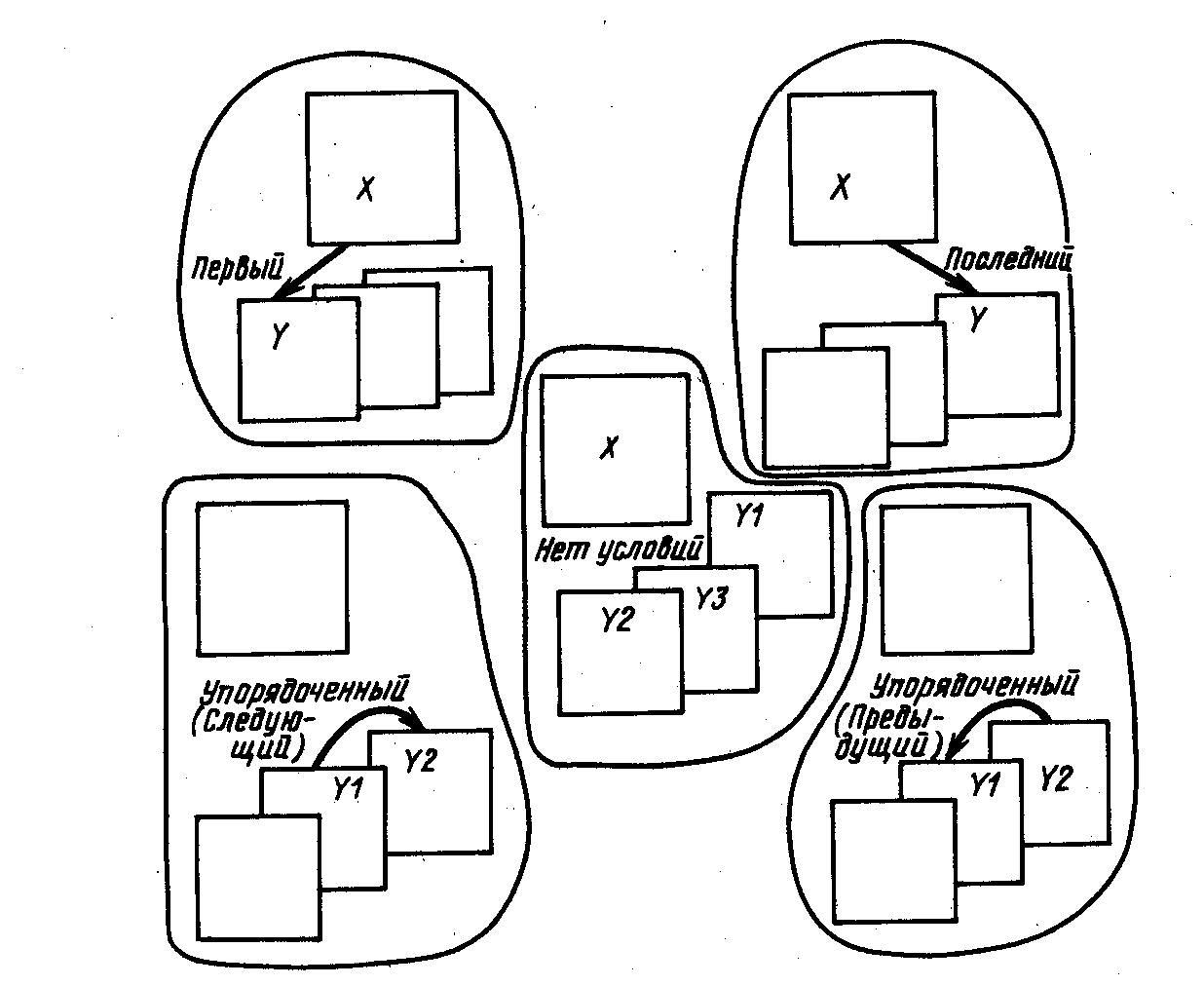
Рис. 7.8
Условия: первый, последний, упорядоченный (следующий и предыдущий), «нет условий». Методы доступа по подчиненности могут использоваться как для хранения, так и для поиска порожденных узлов иерархической модели данных и записей сетевой модели данных.
Первый.
Иерархическая модель данных. В результате включения порожденный узел Y – первый порожденный исходного узла X.
Сетевая модель данных. В результате включения запись-член Y – первый член записи-владельца X.
Последний.
Иерархическая модель данных. В результате включения порожденный узел Y – последний порожденный исходного узла X.
Сетевая модуль данных. В результате включения запись-член Y – последний член записи-владельца X.
Упорядоченный.
Иерархическая модель данных. Порожденный узел должен включаться в соответствии с положением ключа в упорядоченной последовательности ключей. Поэтому порожденный узел с наименьшим значением поля упорядочения будет логически первым.
Сетевая модель данных. Запись-член должна вводиться в соответствии с положением ключа в упорядоченной последовательности ключей. Поэтому запись-член с наименьшим значением поля упорядочения будет логически первой.
Нет условий.
Система управления базами данных не будет поддерживать порядка подчинения.
Наиболее часто методы доступа внешней модели реализуются с помощью указателей. Существуют указатели трех типов:
1. Прямой указатель (рис. 7.9), который включает действительный адрес блока на диске, содержащего «указываемую» запись Y; он хранится в записи X, «указывающей» на запись Y.
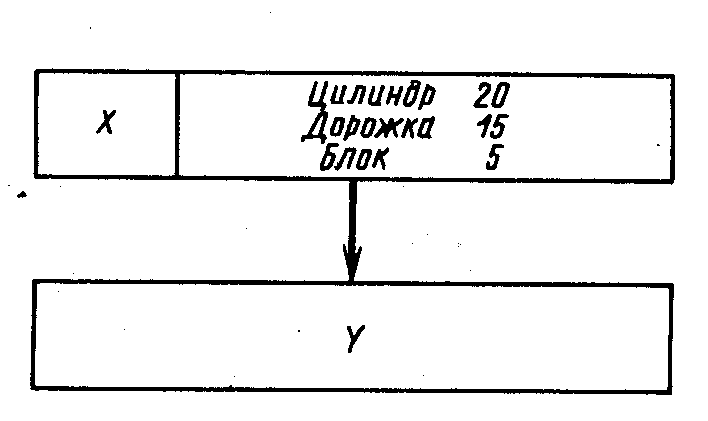
Рис. 7.9
2. Относительный указатель (рис. 7.10) представляет собой логический указатель. Это идентификатор, который может быть отображен в действительный адрес блока на диске. Первой частью указателя такого типа является номер страницы базы данных. Его можно преобразовать в значение смещения страницы относительно начала области. Вторая часть указателя содержит значение смещения относительно нижней границы страницы, определяющее действительное положение на странице.
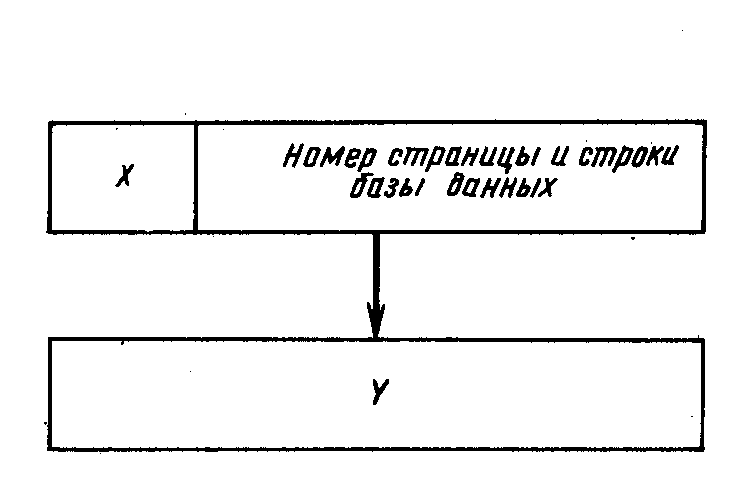
Рис. 7.10
3. Символический указатель (рис. 7.11). Ключ «указываемой» записи Y хранится в «указывающей» на нее записи X. Поиск записи осуществляется методом доступа внутренней модели.
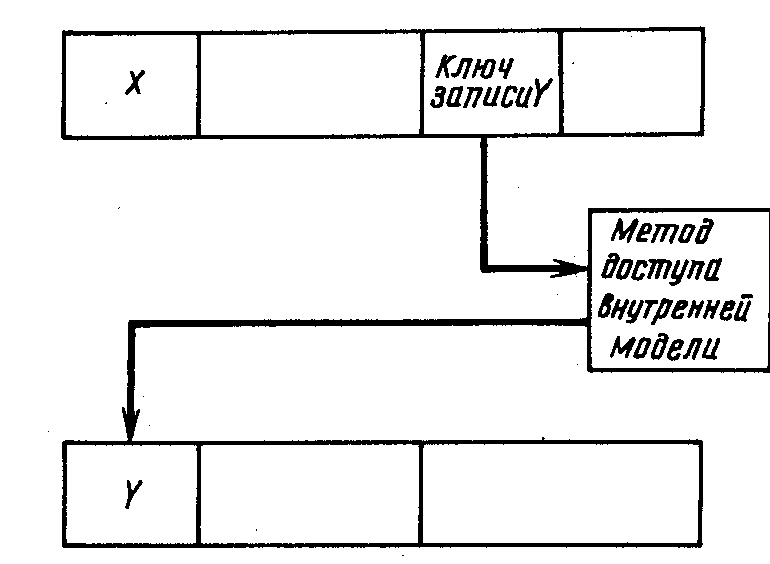
Рис. 7.11
Все эти указатели – прямой, относительный и символический – имеют свои недостатки и преимущества.
Преимущества и недостатки прямого указателя.
Преимущества. Эффективность доступа – наилучшая. Если известен прямой адрес записи, для ее поиска достаточно одного обращения. В большинстве случаев прямой указатель короче соответствующего символического адреса.
Недостатки. Прямой указатель зависит от устройства. При пересылке записи необходимо обновление всех указывающих на нее прямых указателей.
Преимущества и недостатки относительного указателя.
Преимущества. Преимущество относительного указателя перед прямым состоит в том, что при пересылке файлов с устройства (или, в данном случае, просто при копировании) единственное, что должно быть известно СУБД, это размещение начального адреса. Необходимость в изменении какой-либо другой информации отсутствует. По сравнению с символическим указателем относительный имеет двойное преимущество: преобразование ключа в указатель требует очень мало процессорного времени, и, как правило, размеры такого указателя значительно меньше. Относительный ключ представляет собой конкатенацию номера страницы базы данных и номера строк. СУБД и монитор вычисляют номер страницы относительно начала файла. После доступа к странице СУБД использует номер строки в качестве отрицательного смещения относительно нижней границы страницы. Это смещение содержит еще одно, определяющее точное размещение на странице.
Недостатки. Хотя относительный указатель и не зависит от устройства, он по-прежнему основан на заранее известной позиции. С другой стороны, в случае использования символического ключа допускается пересылка записей в любое другое место. При этом изменять следует лишь алгоритм, генерирующий адрес. Таким образом, в системе с символическими указателями нет необходимости в обновлении указывающих на пересылаемую запись символических указателей.
Преимущества и недостатки символического указателя.
Преимущества. Символический указатель не зависит от устройства. При пересылке записи нет необходимости в обновлении указывающих на нее символических указателей.
Недостатки. Эффективность доступа может и не быть наивысшей. Адрес искомой записи должен определяться из значения символического указателя. Символический указатель, как правило, длиннее прямого указателя.