

7.2.3. Индексно-произвольный метод доступа
При таком методе доступа записи хранятся в произвольном порядке и создается отдельный файл статей, включающих значения действительного ключа, и физические адреса хранимых записей. Статья, содержащая действительный ключ и адрес, называется статьей индекса, а весь файл – индексом. Каждой записи базы данных соответствует статья индекса. Существует два основных способа создания индекса и доступа к нему индексно-произвольного метода доступа. Первый способ заключается в применении для ведения индекса схемы упорядочения (например, система IMS обеспечивает так называемое вторичное индексирование, которое иллюстрируется рис. 7.4). Доступ к индексу последовательный. Последовательная организация индекса дает возможность последовательно обрабатывать записи. При втором способе индекс не упорядочивается, но к нему осуществляется произвольный доступ (например, система DMS-11 обеспечивает произвольный доступ к статьям индекса, рис. 7.5). В этом случае значение действительного ключа обрабатывается подпрограммой рандомизации (ПР), в результате чего вычисляется адрес записи в файле данных. Между вырабатываемым адресом и физической записью существует однозначное соответствие. Доступ к индексу реализуется через ПР.
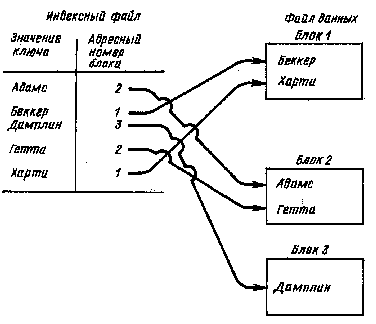
Рис. 7.4
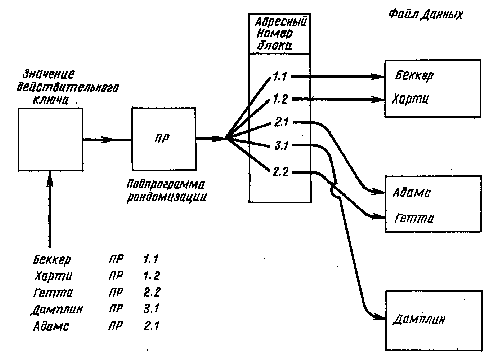
Рис. 7.5
Общим для этих двух способов является то, что записи хранятся неупорядоченно по ключу индекса. Поэтому метод и называется индексно-произвольным.
Индексно-произвольный метод доступа позволяет использовать для создания индексного файла любое поле записи, необязательно поле первичного ключа. Наличие дубликатов значений ключей может препятствовать успешному ведению файла. Этот метод доступа имеет два основных недостатка:
Если индекс не упорядочивается, то только с его помощью обработать записи последовательно в соответствии с порядком индекса невозможно.
Поскольку каждой записи соответствует статья индексного файла, последний может иметь довольно большой объем.
Эффективность доступа.
Произвольная обработка. Так как индекс содержит статью для каждой записи, эффективность доступа равна единице. Это справедливо только для действительного ключа.
Последовательная обработка. Поскольку записи базы данных хранятся в произвольном порядке и необязательно в логической последовательности, эффективность последовательной обработки предсказать невозможно. Для частичного решения этой проблемы индекс может быть организован логически последовательно.
Эффективность хранения.
Каждой записи базы данных соответствует статья индекса, поэтому индексный файл может иметь довольно большой объем, что потребует создания нескольких уровней индексации.
7.2.4. Инвертированный метод доступа
Для обеспечения возможности выборки различными прикладными программами по более чем одному типу атрибута или поля записи может возникнуть необходимость построения индексов для различных типов атрибутов. Метод доступа, в основу которого положена такая концепция, называется инвертированным.
Как правило, инвертированный метод доступа применяется только для поиска, хотя в некоторых системах им можно воспользоваться и для обновления. Хранение чаще всего осуществляется с помощью других методов доступа. Загрузка базы данных может, например, выполняться любым из описываемых в настоящей главе методов доступа внешней модели. Каждому «инвертированному» полю соответствует статья в таблице. Статья включает имя поля, его значение и адрес записи. После начальной загрузки базы данных происходит упорядочение статей по имени поля, а групп статей с общим именем поля – по значению поля. Для каждого имени поля можно построить отдельный индекс. Записи с одним и тем же значением поля группируются, а общее для всех записей группы значение используется в качестве указателя этой группы. По мере добавления новых записей создаются статьи в соответствующих индексах для соответствующих значений. При исключении записей статьи индекса в соответствующих индексах для соответствующих значений уничтожаются. На рис. 7.6 приведен пример поиска записей инвертированным методом доступа.
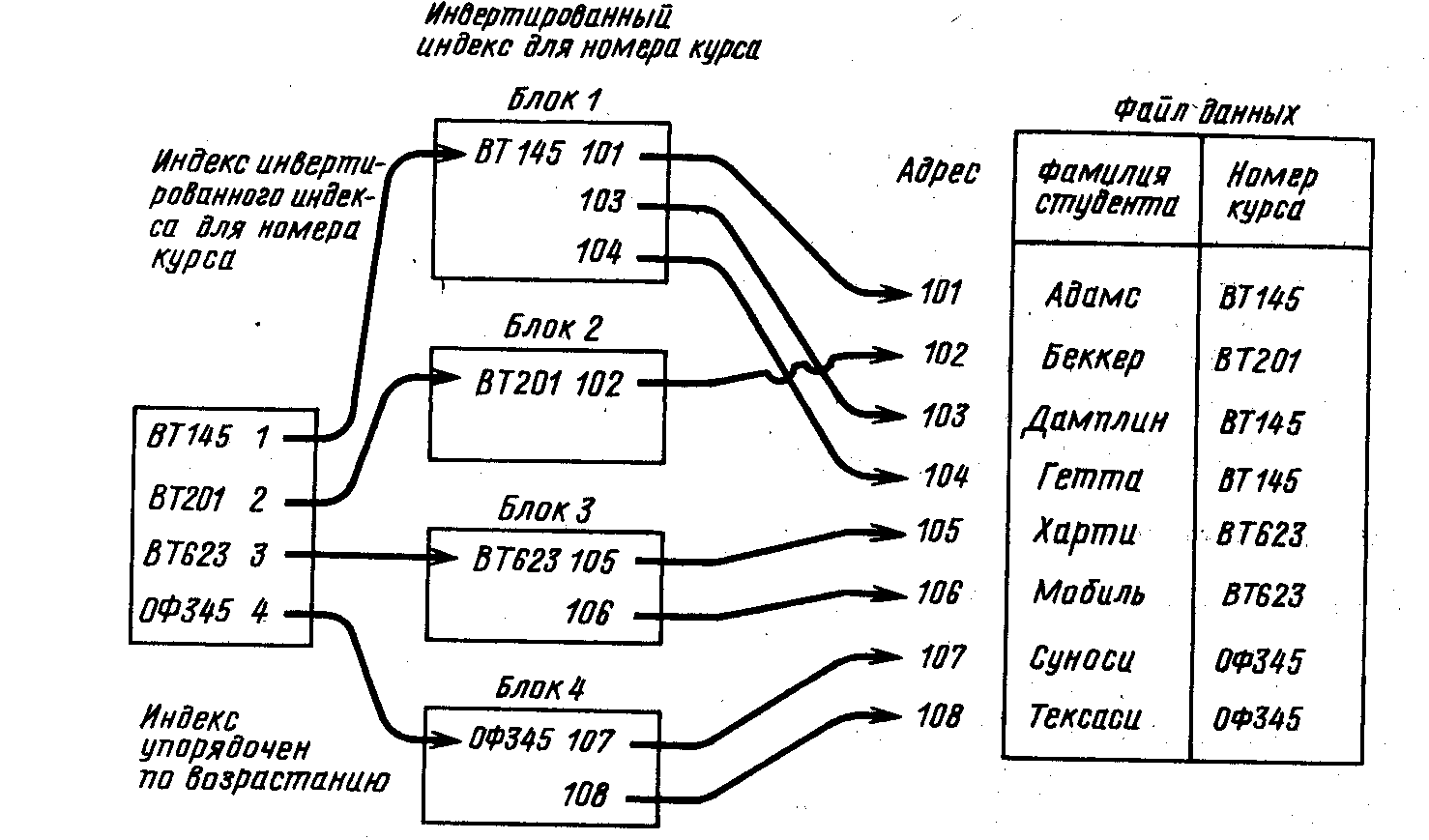
Рис. 7.6
Файл данных инвертируется относительно поля «Номер курса». Каждому инвертированному полю соответствует статья в таблице, называемая также индексом. Статья включает имя поля, его значение и адрес записи. Для любого поля можно построить отдельный индекс, т. е. инвертировать файл относительно этого поля
Эффективность доступа. Доступу к записям базы данных предшествует доступ к индексному файлу (файлам). Поэтому эффективность инвертированного метода доступа зависит от эффективности метода доступа, используемого для обращения к индексу. В любом случае необходимо по меньшей мере одно обращение к индексу и по меньшей мере одно обращение собственно к базе данных. Таким образом, эффективность доступа меньше 0,5. Для обращения к одной записи требуется осуществить минимум два физических обращения. Определение метода, с помощью которого выполняется доступ к индексному файлу, связано с проведением соответствующего анализа. Эффективность доступа значительно повышается, если во время работы базы данных инвертированный индекс постоянно находится в памяти.
Эффективность хранения. Эффективность хранения зависит от метода доступа, применяемого для хранения данных. Если инвертированный метод применяется только для поиска, то высокую эффективность хранения может обеспечить прямой метод доступа. Объем памяти, необходимый для размещения индексного файла, зависит от метода доступа, используемого для запоминания, и от числа полей, подлежащих инвертированию.