

7. Физическая модель данных
Одним из основных факторов, влияющих на производительность программ, которые взаимодействуют с базой данных, является способ хранения и доступа к данным. Обычно в дополнение к специализированным методам доступа в рамках внешней модели СУБД использует несколько методов доступа внутренней модели. Внутренняя модель – это модель физическая, внешняя же отражает представление пользователя (о базе данных). Некоторые методы доступа внутренней модели совпадают с методами доступа операционной системы. Большинство СУБД позволяют проектировщику базы данных варьировать параметры физической организации. Для того чтобы база данных обеспечивала эффективное хранение и доступ к данным, проектировщик должен хорошо знать методы доступа как внутренней модели (физической), так и внешней (представления пользователя) [1], [3], [4].
7.1. Интерфейсы между пользователем и базой данных
На практике увеличение числа операций физического ввода-вывода, выполняемых при выборке данных для удовлетворения запроса пользователя, приводит к снижению производительности.
В процессе выполнения запроса пользователя система проходит несколько интерфейсов (рис. 7.1).
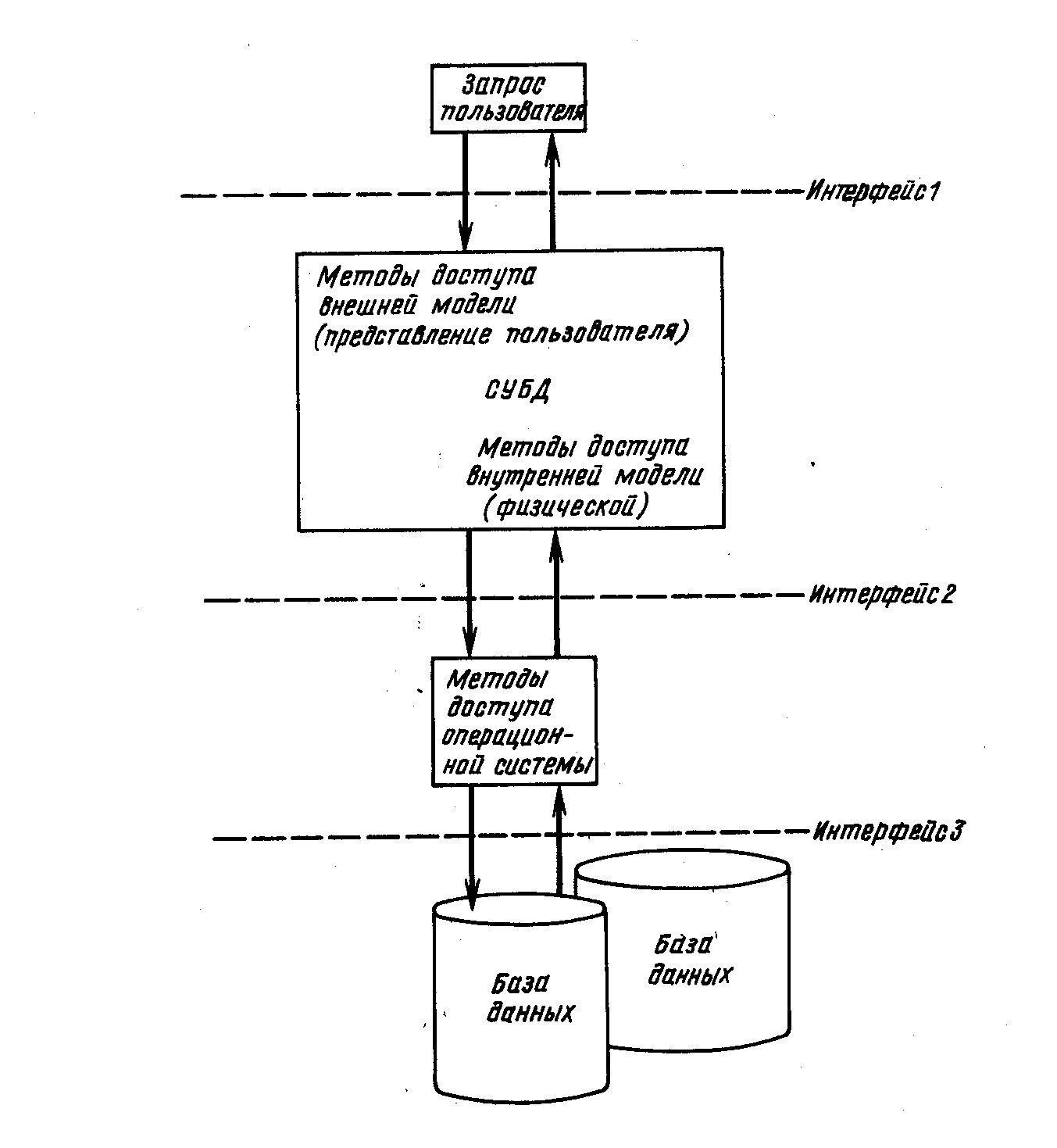
Рис. 7.1
Выполнение запроса пользователя обеспечивают СУБД, методы доступа внешней и внутренней моделей, а также методы доступа операционной системы.
Интерфейс 1.При получении запроса СУБД «известно» описание представления пользователя и прикладной программы, а также условия безопасности и секретности. На основании представления пользователя определяется, к какой физической базе (базам) данных может осуществляться доступ. Кроме того, из описания физической базы (баз) данных известен используемый метод (методы) доступа внутренней модели. Разные реализации предоставляют различные возможности, однако в большинстве из них поддерживается несколько представлений пользователя о базе данных.
Интерфейс 2.В свою очередь СУБД использует методы доступа внутренней модели, которые в разных системах реализованы по-разному: либо как специализированные методы доступа, предоставляемые СУБД, либо как сформированные из обобщенных методов доступа операционной системы. Примерами могут служить ISAM (индексно-последовательный метод доступа) и BDAM (базисный прямой метод доступа).
Интерфейс 3.Методы доступа внутренней модели совместно с методами доступа операционной системы осуществляют доступ к записи (записям) физической базы данных и создают основу для нахождения нужной записи (записей) методом (методами) доступа, описывающими логические взаимосвязи между различными частями записи базы данных.
Методами доступа операционной системы, а также внешней и внутренней моделей, осуществляют выборку данных из физической базы (баз) данных и их передачу СУБД, которая определяет, какая часть данных может быть выдана пользователю, в каком формате и т. д. АБД должен описать все эти характеристики для СУБД до начала реализации базы данных.
7.2. Методы доступа внутренней модели (физической)
Различают следующие методы доступа внутренней модели: физический последовательный, индексно-последовательный, индексно-произвольный, инвертированный и посредством хеширования. Для каждого из них зададим два критерия:
Эффективность доступа – величина, обратная среднему числу физических обращений, необходимых для осуществления логического доступа, т. е. запроса конкретной записи базы данных. Физические обращения обеспечивают удовлетворение запроса. Например, если для поиска нужной записи система обращается к двум записям, то эффективность доступа равна 0,5.
Эффективность хранения – величина, обратная среднему числу байтов поля вторичной памяти, требуемого для хранения одного байта исходных данных. Кроме исходных данных, память занимают таблицы, управляющая информация, свободная область, резервируемая для расширений, и область, не используемая из-за фрагментации.
Физический последовательный.
Значения ключей физических записей находится в логической последовательности.
В основном применяется для «дампа» и «восстановления».
Может применяться как для хранения, так и для выборки данных. Эффективность использования памяти близка к 100%.
Эффективность доступа физического последовательного метода оставляет желать лучшего. Для выборки нужной записи требуется просмотреть все предшествующие ей записи базы данных.
Индексно-последовательный.
Метод доступа, при использовании которого до осуществления доступа к собственно записям базы данных проверяются значения ключей, называется индексно-последовательным.
Значения ключей физических записей находятся в логической последовательности. Может применяться как для хранения, так и для выборки данных.
В индекс значений ключей заносятся статьи наибольших значений ключей в блоках.
Наличие дубликатов значений ключей недопустимо.
Эффективность доступа зависит от числа уровней индексации, распределения памяти для размещения индекса, числа записей базы данных и уровня переполнения.
Эффективность хранения зависит от размера и изменяемости базы данных.
Индексно-произвольный.
При индексно-произвольном методе доступа записи хранятся в произвольном порядке. Создается отдельный файл из статей, содержащих значения действительного ключа и физические адреса хранимых записей.
Значения ключей физических записей необязательно находятся в логической последовательности.
Хранение и доступ к индексу могут осуществляться с помощью индексно-последовательного метода доступа.
Индекс содержит статью для каждой записи базы данных. Эти статьи упорядочены по возрастанию. Ключи индекса сохраняют логическую последовательность. Если же они эту последовательность не сохраняют, доступ к индексу осуществляется посредством алгоритма хеширования. Записи базы данных могут быть и не упорядочены по возрастанию ключа.
Может использоваться как для запоминания, так и для выборки данных.
Инвертированный.
Значения ключей физических записей необязательно находятся в логической последовательности.
Может использоваться только для выборки данных.
Индекс может быть построен для каждого инвертируемого поля.
Эффективность доступа зависит от числа записей базы данных, числа уровней индексации и распределения памяти для размещения индекса.
Как правило, инвертированный метод доступа применяется только для выборки. Запоминание осуществляется с помощью каких-либо других методов доступа.
Прямой метод доступа.
При прямом методе адреса памяти, используемые при хранении и поиске физических записей, могут быть уникальными. Каждому ключу записи соответствует уникальный адрес ячейки памяти.
Не требуется упорядоченность значений ключей физических записей.
Между ключом записи и ее физическим адресом существует взаимно однозначное соответствие.
Может применяться как для хранения, так и для поиска.
Эффективность доступа всегда равна единице.
Эффективность хранения зависит от плотности ключей.
Наличие дубликатов ключей недопустимо.
Метод доступа посредством хеширования.
Не требуется логическая упорядоченность значений ключей физических записей. Значениям нескольких ключей может соответствовать один и тот же физический адрес (блок).
Может применяться как для хранения, так и для поиска.
Эффективность доступа зависит от распределения ключей, алгоритма их преобразования и распределения памяти.
Эффективность хранения зависит от распределения ключей и алгоритма их преобразования.
При методе доступа посредством хеширования адрес физической записи алгоритмически определяется из значения ключа записи.
Как правило, разработчику базы данных приходится находить приемлемое соотношение между эффективностью доступа и эффективностью хранения. Эффективность доступа приобретает особое значение в оперативных системах. Некоторые СУБД сконструированы так, чтобы обновления (базы данных) в оперативном режиме выполнялись оптимальным образом.