

7.2.5. Прямой метод доступа
Основная особенность прямого метода доступа состоит во взаимно однозначном соответствии между ключом записи и ее физическим адресом. Физическое местоположение записи определяется непосредственно из значения ключа.
Эффективность доступа. Если между значением ключа и физическим адресом существует взаимно однозначное соответствие, то при непосредственном использовании этого метода эффективность доступа всегда равна единице. В противном случае эффективность доступа при выборке записей зависит от метода выборки.
Эффективность хранения. Эффективность хранения зависит от плотности ключей. При низкой плотности память расходуется впустую, поскольку резервируются адреса, соответствующие отсутствующим ключам (табл. 7.1).
Таблица 7.1
ПРИМЕР ПРЯМОГО МЕТОДА ДОСТУПА
|
Номера студентов (исходные ключи) |
Преобразованные ключи (объектные ключи) |
Адреса хранения (относительные номера блоков) |
|
Х101 Х102 Х10З |
01 02 03 |
1 Х101 2 Х102 3 Х10З |
|
Х199 Y100 Y101 (Отсутствует) Y103 |
99 100 101 (отсутствует) 103 |
99 Х199 100 Y500 101 Y501 пустая ячейка 103 Y503 |
При построении преобразованных (объектных) ключей в основу берутся номера студентов (исходные ключи), соответствующие уникальным адресам хранения. Взаимно однозначное соответствие между ключом записи и ее физическим адресом – основная особенность этого метода доступа
На табл. 7.1 приведен пример следующего алгоритма: у всех исходных ключей, начинающихся с комбинации «X1», оставить только последние две цифры, использовать их в качестве целевого ключа и адреса хранения; у всех исходных ключей, начинающихся с символа «Y», оставить три последние цифры, которые использовать в качестве целевого ключа и адреса хранения. Заметим, что физическая запись с ключом «Y102» отсутствует, а память для этой записи резервируется. Другим недостатком этого метода доступа является обязательная уникальность ключей.
7.2.6. Метод доступа посредством хеширования
В ряде случаев можно не требовать взаимно однозначного соответствия между ключом и физическим адресом записи. Вполне достаточно, чтобы группа (ключей) записей ссылалась на один и тот же физический адрес. Такой метод доступа называется методом доступа посредством хеширования.
Как и прямой метод доступа, метод доступа посредством хеширования основан на алгоритмическом определении адреса физической записи по значению ее ключа. Различие состоит в том, что при прямом методе доступа имеет место взаимно однозначное отображение ключа в адрес, а метод доступа посредством хеширования допускает возможность отображения многих ключей в один адрес (т. е. один и тот же адрес или блок может быть идентифицирован более чем одним значением ключа).
Алгоритм преобразования ключа в адрес часто называют подпрограммой рандомизации или подпрограммой хеширования. Одинаковые ключи подпрограмма преобразует в одинаковые адреса: подпрограмма рандомизации отображает набор значений исходных ключей в набор адресов, причем число ключей превышает число адресов. Записи, ключи которых отображаются в один и тот же физический адрес, называются синонимами. Поскольку по адресу, определяемому подпрограммой рандомизации, может храниться только одна запись, синонимы должны храниться в каких-нибудь других ячейках памяти. В то же время необходимо наличие механизма поиска этих синонимов. В большинстве случаев записи-синонимы связываются в цепочку, называемую цепочкой синонимов (рис. 7.7).
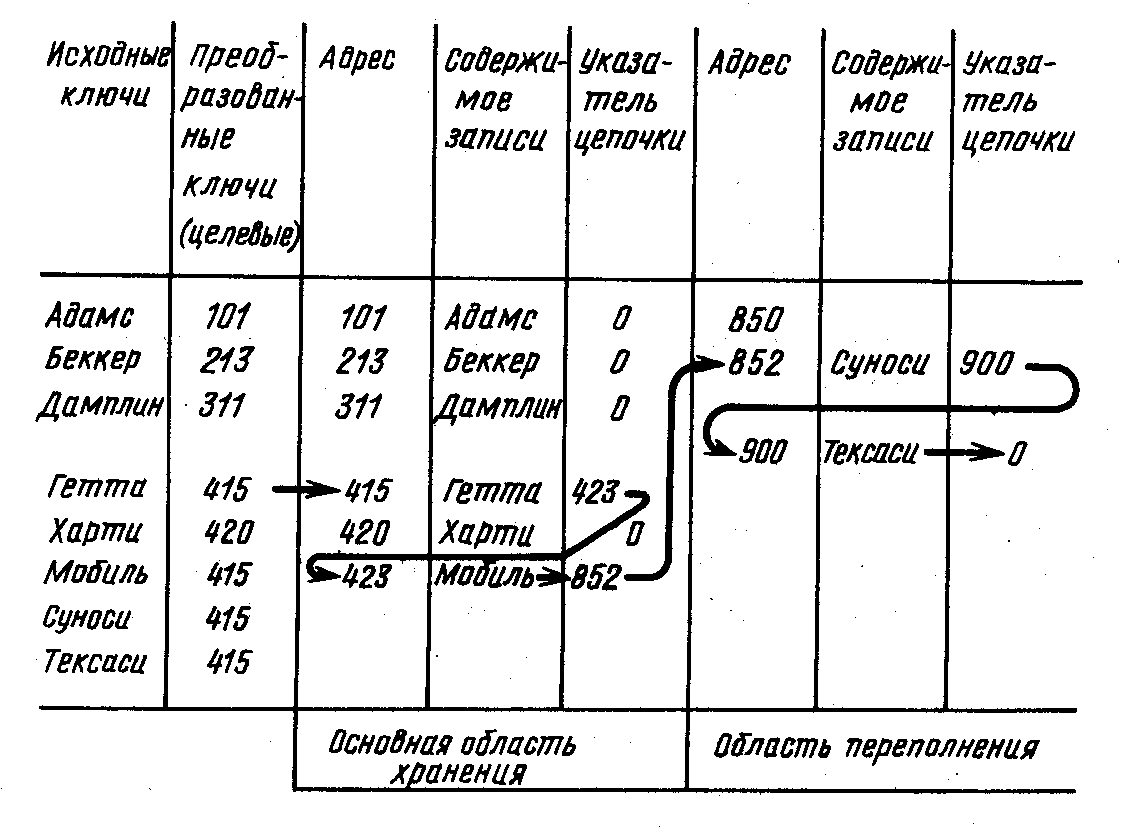
Рис. 7.7
Обратите внимание на цепочку синонимов для записей с ключами Гетта, Мобиль, Суноси и Тексаси. Значение исходного ключа Гетта преобразуется в адрес первой записи цепочки синонимов – 415. Запись Гетта содержит указатель на адрес 423, по которому размещается запись Мобиль. В свою очередь запись Мобиль содержит указатель на адрес 852, по которому размещается запись Суноси. Запись Суноси содержит указатель на адрес 900, по которому размещается запись Тексаси. Эта последняя запись в цепочке содержит нулевой указатель.
При использовании подпрограммы рандомизации необходимо иметь в виду несоответствие порядка хранения физических записей порядку исходных ключей. Это несоответствие может существенно усложнить обработку записей в порядке следования исходных ключей.
Эффективность доступа.
На эффективность доступа данного метода оказывают влияние три фактора:
Распределение исходных ключей. В большинстве случаев распределение исходных ключей отличается от чисто случайного. Чем больше разработчику известно о распределении, тем выше вероятность правильного выбора числа блоков и числа записей в блоках. Оптимальный выбор этих значений позволяет разработчику сократить среднюю длину цепочки синонимов. Эффективность метода доступа посредством хеширования в значительной степени зависит от длины цепочки синонимов.
Распределение памяти. Для эффективности доступа первостепенное значение имеет равномерность распределения действительных ключей на множестве блоков (т. е. в выделенном поле памяти). Если подпрограмма рандомизации назначает большое число ключей одной области, то число синонимов возрастает. С увеличением объема распределенной памяти увеличивается число адресов, которые могут формироваться подпрограммой рандомизации.
Подпрограмма рандомизации или хеширования (называемая также алгоритмом или модулем). Хорошая подпрограмма рандомизации должна обеспечивать равномерное распределение действительных ключей в выделенном поле памяти, снижая таким образом среднюю длину цепочки синонимов.
Эффективность хранения.
Эффективность хранения зависит от распределения памяти и подпрограммы рандомизации. При применении доступа посредством хеширования целесообразно не задавать свободную память в блоках и свободные блоки, поскольку, если подпрограмма рандомизации сформирует адрес внутри свободной памяти в блоке или адрес блока, объявленного свободным, записи будут размещены в области переполнения. Определение размера страницы также имеет первостепенное значение. Если нужная страница находится в памяти, просмотр цепочки синонимов реализуется гораздо проще, чем в ситуации, требующей выполнения физического ввода-вывода.
С помощью рассмотренных выше шести методов доступа внутренней модели можно реализовать другие, более сложные методы доступа.