

1.2.1. Ключевой элемент данных
Некоторые элементы данных обладают интересным свойством. Зная значение, которое принимает такой элемент данных объекта, мы можем идентифицировать значения, которые принимают другие элементы данных этого же объекта. Например, зная идентификационный номер клиента «123456789», мы можем определить, что это «проф. Хиггинс» и что профессор Хиггинс имеет «открытый» счет в банке. Элементы данных, по которым можно определить другие элементы данных, называются ключевыми. Иногда их называют также идентификаторами объекта.
Однозначно идентифицировать объект могут два и более элемента данных. В этом случае их называют «кандидатами» в ключевые элементы данных. Вопрос о том, какой из кандидатов использовать для доступа к объекту, решается пользователем или проектировщиком. Выбирать ключевые элементы данных следует тщательно, поскольку правильный выбор способствует созданию достоверной модели данных.
1.2.2. Запись данных
Совокупность значений связанных элементов данных образует запись данных.На рис. 1.2 такими элементами данных являются фамилия и идентификационный номер клиента, тип счета и т.д. Записи хранятся на некотором носителе, в качестве которого может выступать человеческий мозг, лист бумаги, память ЭВМ, внешнее запоминающее устройство ЭВМ и т. д.
1.2.3. Файл данных
Записи данных образуют файл данных:файл представляет собой упорядоченную совокупность записей. На рис. 1.2 показан пример файла в отпечатанном виде — отчет управляющего отделением (выдержка) с записями одного типа. Файл такого типа — с похожими записями (т. е. содержащими одинаковое число элементов)»—называется «плоским». Файл также может содержать записи различного типа. Иногда файл называют набором данных.
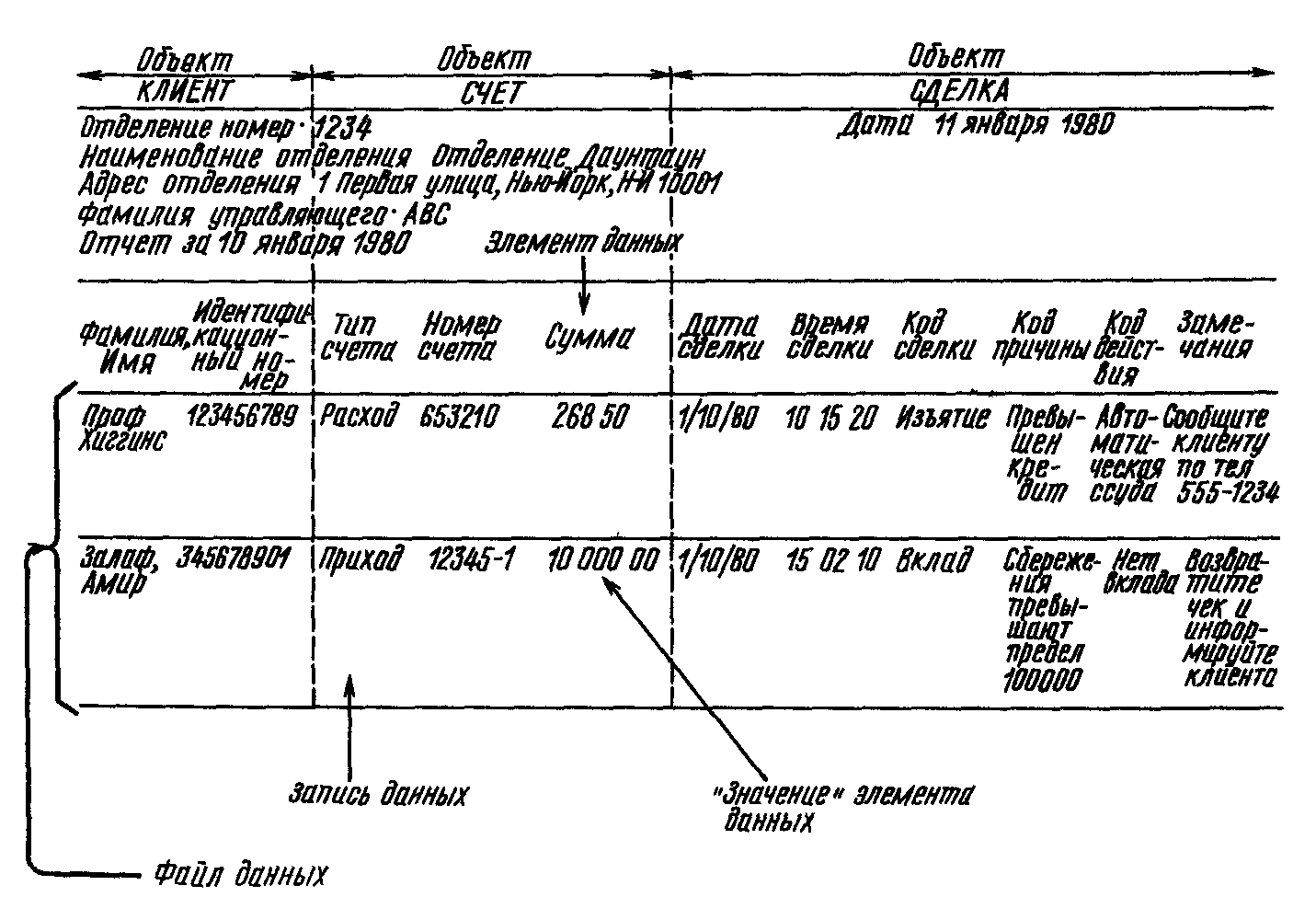
Рис. 1.2
Методы доступа, или универсальные подпрограммы доступа, гарантируют разную степень независимости от физического хранения лепных, при которой некоторые изменения физического хранения могут отражаться в методах доступа и не требовать внесения изменений в прикладные программы. В дальнейшем мы рассмотрим способы создания прикладных программ, не зависящих от физических характеристик устройств хранения данных. Однако прежде обсудим некоторые недостатки традиционной среды файлов данных.
1.3. Недостатки традиционной организации файлов данных
Рассмотрим задачи, связанные с банковскими операциями (рис. 1.1). Ниже перечисляются проблемы, с которыми приходится сталкиваться в процессе обработки данных при использовании нескольких файлов.
Избыточность данных.Некоторые элементы данных, такие, как имя, адрес и идентификационный номер клиента, неизбежно используются во многих прикладных программах. Поскольку данные требуются нескольким прикладным программам, они часто записываются в несколько файлов, т. е. одни и те же данные хранятся в разных местах. Такое положение называют «избыточностью данных». Оно делает проблематичным обеспечение непротиворечивости данных. Избыточность данных требует наличия нескольких процедур ввода, обновления и формирований отчетов.
Проблемы непротиворечивости данных.Одной из причин нарушения непротиворечивости данных является их избыточность, что связано с хранением одной и той же информации в нескольких местах. Как показано на рис. 1.3., адрес одного и того же клиента хранится в четырех различных наборах данных: в файле данных расходных счетов, в файле данных приходных счетов, в файле данных взносов по закладной и в файле данных ссуд по закладной. При смене местожительства клиента необходимо изменить его адрес в четырех местах. Зачастую по разным причинам выполнить это не удается. В результате об одном и том же объекте предметной области в разных местах хранится различная информация.
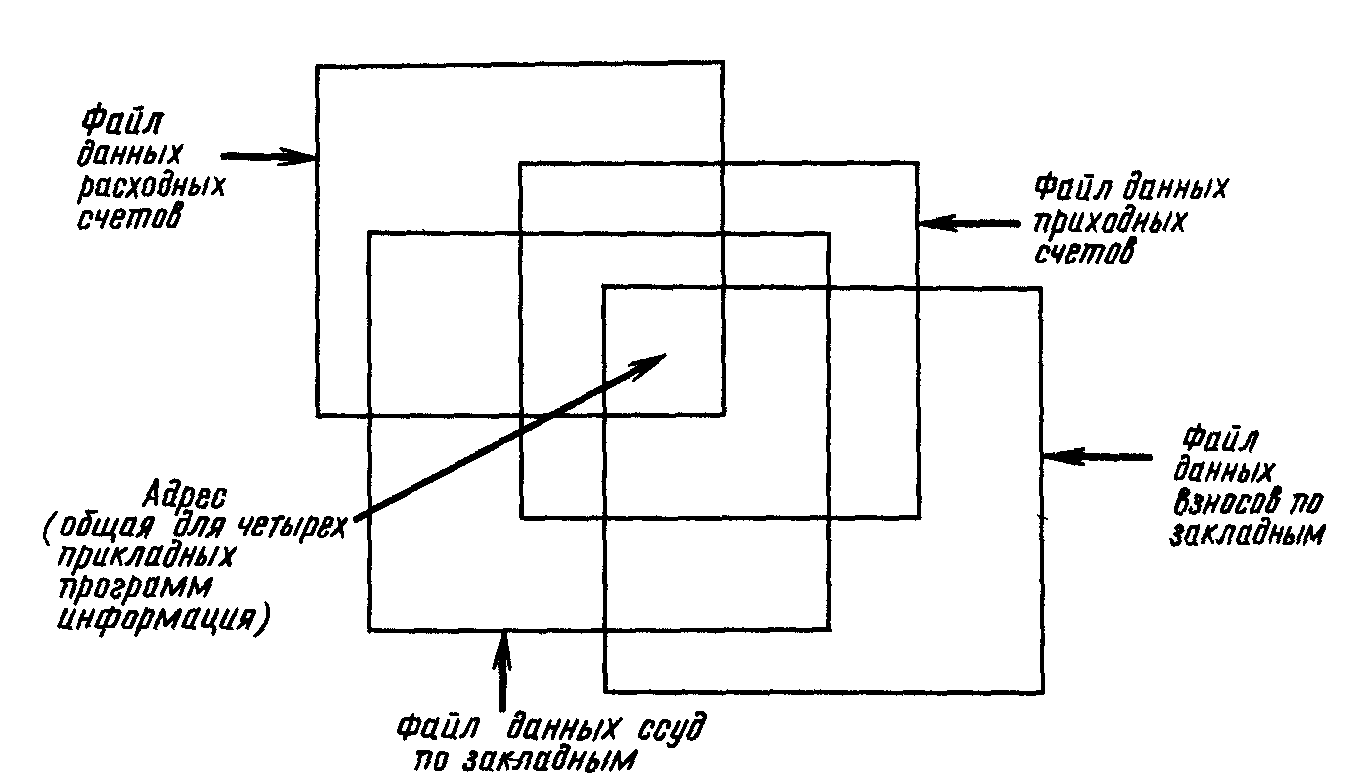
Рис. 1.3
Нарушение непротиворечивости данных может также явиться следствием недостаточного контроля их достоверности в случае внесения изменений. При попытках объединить данные до появления технологии баз данных пришлось столкнуться с целым рядом трудностей, в частности, из-за:
• недостаточности средств защиты хранимых данных;
• неадекватности процедур восстановления после возникновения отказов;
• трудностей по обеспечению ведения длинных записей;
• негибкости к изменениям;
• высокой стоимости программирования и сопровождения;
• сложности процедур управления эксплуатацией ЭВМ (небрежность и ошибки)
Ограниченное разделение данных.Поскольку в нашей задаче, связанной с банковскими операциями, прикладные программы расхода, прихода, взносов по закладной и ссуд по закладной обеспечивают обработку данных одной организации, между элементами данных различных файлов существует некоторая взаимосвязь. Однако, когда файлы реализованы в виде отдельных единиц, установление связей между элементами данных посредством прикладных программ затруднительно или вообще невозможно. Если предметная область соответствует организации, функционирующей как единое целое, необходимо разделить данные между различными файлами.
Ограничения по доступности данных.В современных условиях, когда обстановка быстро изменяется, лицо с соответствующими правами доступа необходимо иметь возможность получить данные за приемлемый отрезок времени. Если же данные разбросаны по нескольким файлам, доступность данных, комбинируемых из этих файлов, ограничена.
Сложности в управлении.Из-за избыточности данных в файлах трудно реализовать новые директивы по всей предметной области. Например, если номер социального страхования нельзя будет использовать в качестве идентификационного номера, то там, где номер социального страхования уже используется, потребуются определенные временные затраты для внесения изменений во все файлы.
Для решения вышеуказанных проблем были разработаны системы баз данных.