

6.2. Отображение на иерархическую модель данных
Преобразование концептуальной модели в логическую иерархическую модель данных сложнее, поскольку при этом существует кажущаяся свобода выбора конкретных решений и, как правило, в таких случаях единственно верного решения быть не может. Однако преобразование модели можно разбить на этапы и определить для каждого из них критерии выбора решения. Различают основные этапы:
Вывод обобщенной иерархической модели, в которой не учитываются ограничения, накладываемые используемой СУБД.
Трансформация полученной модели с учетом, ограничений, накладываемых конкретной СУБД.
Модификация трансформированной модели с учетом «очевидных» соображений, влияющих на производительность.
. Упрощение имен ключей.
. Реализация взаимосвязей, не отображенных в логической модели, но на самом деле существующих.
Устранение транзитивности.
В концептуальной модели имеется транзитивная зависимость, если удаление взаимосвязи между А и С не приводит к потере информации (рис. 6.3). Отношение между А и С может быть выведено из отношений между А и В и между В и С.

Рис. 6.1
После удаления взаимосвязи между А и С можно видоизменить рис. 6.1 так, как это показано на рис. 6.2.
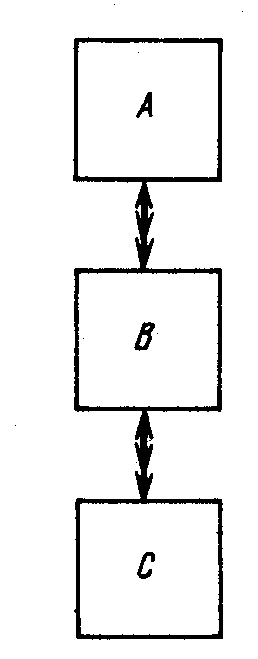
Рис. 6.2
Перед тем, как удалить какую-либо взаимосвязь, необходимо проанализировать, не приведет ли это к потере информации. Обратимся к примеру на рис. 6.3.

Рис. 6.3
Здесь взаимосвязь 1 между СТУДЕНТОМ и ПРЕПОДАВАТЕЛЕМ отражает отношение между студентами и их научными руководителями. Взаимосвязь 2 отражает отношения между студентами и преподавателями в ходе выполнения проектов. Преподаватель может одновременно быть научным руководителем у одной группы студентов и консультантом проекта у другой. В этом примере нельзя удалить первую взаимосвязь, так как это приведет к потере определенной информации.
1.2. Выявление взаимосвязей типа «исходный-порожденный».
В концептуальной модели прямоугольники представляют узлы, а стрелки – взаимосвязи между исходными и порожденными узлами. На рис. 5.9 корневые узлы изображены в виде прямоугольников, находящихся на первом уровне (СТУДЕНТ, КУРС и СЕМЕСТР). На втором уровне находится узел СЕМЕСТР+КУРС, который может быть порожденным либо для узла СЕМЕСТР, либо для узла КУРС. Здесь имеется два корневых узла, т. е. два иерархических дерева, которые соединяются между собой с помощью узла СЕМЕСТР+КУРС. Необходимо решить, какой же узел – СЕМЕСТР или КУРС – будет исходным для узла СЕМЕСТР+КУРС.
Рассмотрим ту часть рис. 5.9, где имеются узлы СЕМЕСТР, СЕМЕСТР+ КУРС и СЕМЕСТР+КУРС+СТУДЕНТ. Узел СЕМЕСТР+КУРС+СТУДЕНТ может быть порожденным либо для узла СЕМЕСТР+КУРС второго уровня, либо для узла СТУДЕНТ первого уровня.
На этом этапе выявляются возможные взаимосвязи типа «исходный- порожденный». Окончательный выбор осуществляется на следующем этапе.
1.З. Устранение множественного родительства.
При отображении концептуальной модели на иерархическую необходимо, чтобы у каждого порожденного узла остался ровно один исходный. Например, нужно решить, какой узел является исходным для узла СЕМЕСТР+КУРС,-СЕМЕСТР или КУРС.
В рассматриваемой концептуальной модели имеется два типа исходных узлов. Одни из них представляют реальные отношения в третьей нормальной форме, полученные на основе анализа требований к данным (к таким узлам относятся, например, СТУДЕНТ и СЕМЕСТР, другие же были «сгенерированы» при синтезе концептуальной модели.
Выбор исходных узлов зависит от следующих комбинаций.
1.3.1. Оба исходных узла являются отношениями в третьей нормальной форме и не были созданы искусственно.
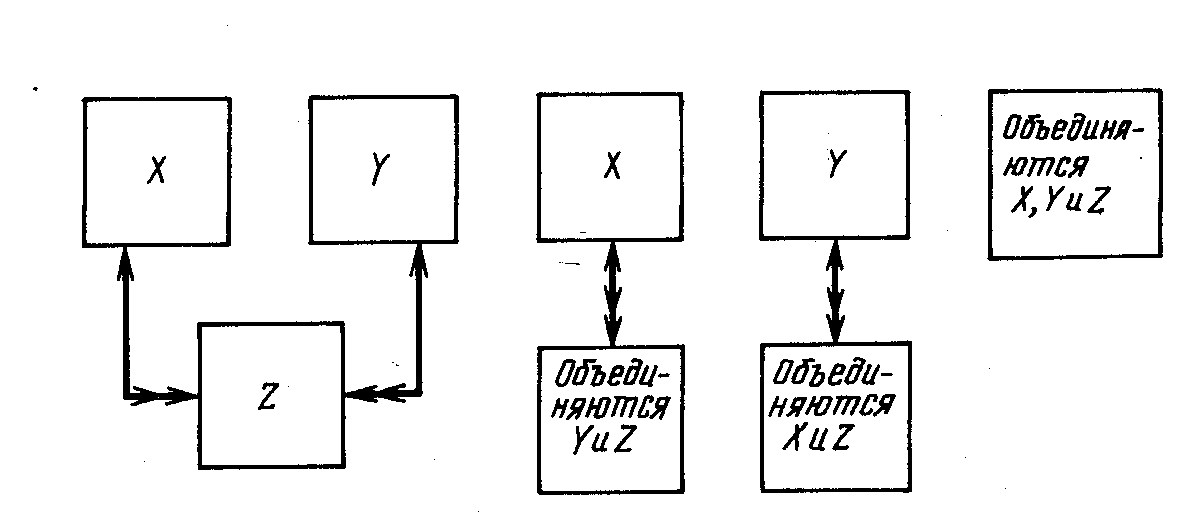
Рис. 6.4
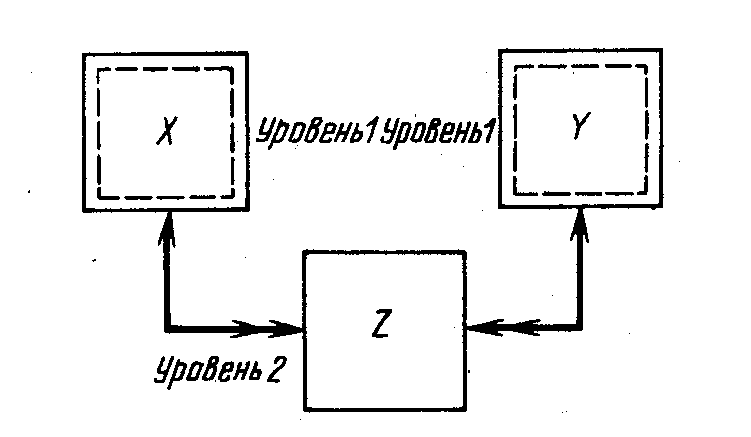
На рис. 6.4 узлы Х и Y – исходные, аZ—порожденный. Здесь возможны два варианта выбора исходного узла. Либо Х принимается за исходный узел, аYиZобъединяются и становятся порожденным узлом, либоYпринимается за исходный, аXиZобъединяются. И в том, и в другом случаях возникает избыточность данных. Поэтому, следует решить, всегда ли необходимо наличие двух исходных узлов или же ценой введения избыточности можно объединить один из предполагаемых исходных узлов с порожденным. Существует и третий вариант–объединить исходные и порожденный в один узел, например X,YиZ.
1.3.2. Один из исходных узлов – истинное отношение в третьей нормальной форме, а другой образован искусственно.
Следует удалить тот исходный узел, который был «сгенерирован» при синтезе концептуальной модели. На рис. 6.5а таким «сгенерированным» узлом является КУРС, в то время как СЕМЕСТР представляет собой результат приведения исходных отношений к третьей нормальной форме. Единственным атрибутом КУРСА служит номер курса (НОМ-КУРСА). Этот атрибут имеется также и в узле СЕМЕСТР+КУРС. Если удалить узел КУРС, как показано на рис. 6.5,6, то никакая информация не теряется. При этом единственным исходным для узла СЕМЕСТР+КУРС остается узел СЕМЕСТР. Удаляя узел, не следует упускать из виду его связи с остальными узлами модели.
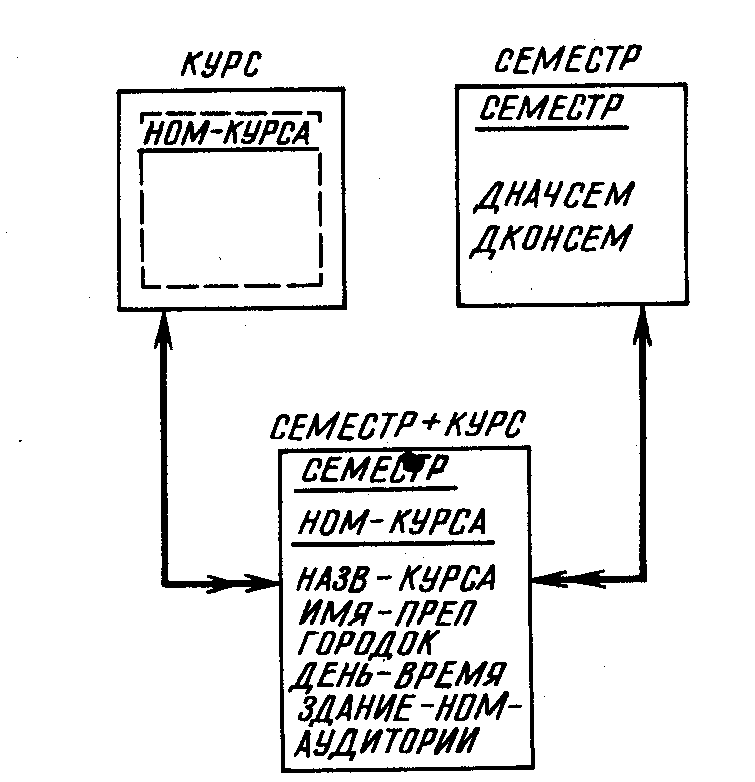
а
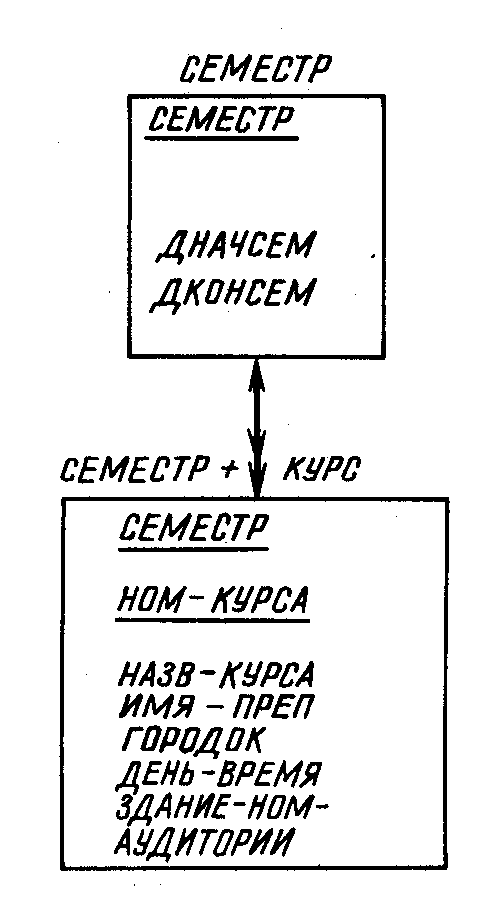
б
Рис. 6.5
1.З.З. Оба исходных узла образованы искусственно.
Исходные узлы Х и Y«сгенерированы». Оба они могут быть удалены при устранении ситуации «несколько исходных».
а
Рис. 6.6
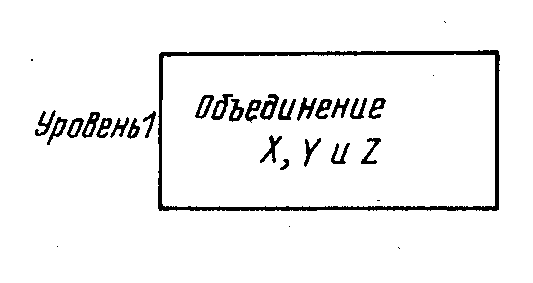
б
Окончание рис. 6.6
На рис. 6.6а узлы Х иY«сгенерированы» и являются исходными. Порожденный узел–Z. Можно объединить X,YиZв один новый тип узла. Поскольку и X, иYудаляются, можно переместить объединенный узел, X,YиZна более высокий уровень иерархии, как это показано на рис. 6.6,б.
1.3.4. Если согласно А.3.1—А.З.З не достигнуто решение, выбор произволен.
Если в процессе проектирования выясняется, что обязательно наличие двух исходных узлов, следует использовать СУБД, поддерживающую несколько исходных узлов. Узел СЕМЕСТР+КУРС имеет два исходных узла. Допустим, что мы принимаем решение остановиться на логической модели, показанной на рис. 6.6.
Этапы преобразования в п. 1.3.1—1.З.З можно последовательно применять к узлам, расположенным на нижних уровнях: рассматриваются исходные узлы второго уровня и порожденные третьего и т. д.
Теперь можно учесть ограничения, которые накладывает используемая СУБД.
2. Трансформация полученной модели данных с учетом ограничений, накладываемых конкретной СУБД.
Иерархическую модель данных поддерживает целый ряд СУБД. Одна из них –системаIMS, поставляемаяIBM.Эта система поддерживает и некоторые сетевые структуры. Использование системыIMSнакладывает следующие ограничения на модель данных:
Возможно существование .не более 255 типов узлов, которые в системе IMSназываются «типами сегментов».
Допускается не более 15 уровней иерархии.
Порожденный сегмент может иметь максимум два исходных сегмента. Один из исходных сегментов, в иерархии которого находится порожденный, называется «физически исходным». Другой исходный называется «логически исходным». На логически порожденные сегменты накладывается следующее ограничение.
Логически порожденный не может иметь логически порожденного.
Ни одно из перечисленных ограничений на рис. 6.7не нарушено. Поэтому никаких трансформаций логической модели не требуется. Эта модель может быть реализована в системеIMS. Единственный вопрос, который остается решить, касается расположения логически порожденного сегмента СЕМЕСТР + КУРС + СТУДЕНТ. Последний может быть физически порожденным либо сегмента СЕМЕСТР, либо сегмента СЕМЕСТР+КУРС.
Рис. 6.7
3. Модификация трансформированной модели данных с учетом «очевидных» соображений, влияющих на эффективность обработки.
Можно ли улучшить эксплуатационные характеристики будущей базы данных путем объединения сегментов и сокращения числа уровней, разбиения сегментов с целью более эффективной передачи данных или обеспечения их безопасности, объединения или разделения иерархий и других структурных изменений?
На перечисленные вопросы невозможно ответить, не имея ряда количественных характеристик, например частоты использования различных путей в иерархии, среднего числа экземпляров сегментов каждого типа, длин сегментов. Их рассмотрение относится скорее к физическому проектированию базы данных. Однако и в процессе логического проектирования можно принять в этой части ряд решений, основанных на «очевидных» соображениях.
3.1. Исходный сегмент, обладающий только одним порожденным типом сегмента, может с ним объединяться.
На рис. 6.7 у сегмента СЕМЕСТР только один порожденный СЕМЕСТР+ КУРС. Необходимо сделать выбор между требованиями повышения производительности и уменьшения избыточности данных. В сегменте СЕМЕСТР всего два поля: ДНАЧСЕМ (дата начала семестра) и ДКОНСЕМ (дата окончания семестра). Если принять сегмент СЕМЕСТР в качестве исходного для сегмента СЕМЕСТР+КУРС, то для каждого семестра останется лишь один экземпляр сегмента СЕМЕСТР, т. е. даты его начала и окончания будут запоминаться в течение семестра всего один раз. Но при этом должен храниться по крайней мере один указатель на первый принадлежащий данному семестру экземпляр курса. Кроме того, хранятся указатели, связывающие экземпляры семестров. Следует рассмотреть время, затрачиваемое на обновление указателей и на доступ к отдельным сегментам СЕМЕСТР и СЕМЕСТР+КУРС.
Одно из решений состоит в объединении сегментов СЕМЕСТР и СЕМЕСТР+КУРС, что порождает избыточность по значениям ДНАЧСЕМ (дата начала семестра) и ДКОНСЕМ (дата окончания семестра). Если в данном семестре читается 50 различных курсов, им соответствует 50 экземпляров сегмента СЕМЕСТР+КУРС, в каждом из которых для каждого курса хранятся поля ДНАЧСЕМ и ДКОНСЕМ. Избыточность данных приводит к увеличению требуемых объемов памяти. Более серьезную проблему может представлять обеспечение целостности избыточно хранимых данных. Основным вопросом, который следует рассматривать при введении избыточности, является частота обновления данных. Часто обновляемые данные должны храниться с минимальной избыточностью. В нашем примере дата начала семестра и дата его окончания в течение семестра не изменяются. Обновление этих значений происходит достаточно редко. Поэтому интуитивно представляется вполне оправданным объединить сегмент СЕМЕСТР и его порожденный сегмент СЕМЕСТР+КУРС.
Мы решили, что сегмент СЕМЕСТР+КУРС+СТУДЕНТ будет для сегмента СТУДЕНТ физически порожденным, а для сегмента СЕМЕСТР+КУРС –логически порожденным.
3.2. Следует ли сохранить логическую взаимосвязь или объединить логически исходный и логически порожденный сегменты?
Пусть логически исходный сегмент СЕМЕСТР+КУРС имеет логически порожденный СЕМЕСТР+КУРС+СТУДЕНТ. В системе IMSс каждого корневого сегмента начинается новая база данных. Мы имеем два иерархических дерева и соответственно две базы данных. Всякий раз, когда прикладной программе потребуются сведения о курсах, которые изучает какой-либо студент, системаIMSдолжна осуществить доступ к двум различным базам данных: базе данных СТУДЕНТ и базе данных СЕМЕСТР и КУРС.
Главная причина, по которой такого объединения делать не следует, заключается в том, что оно приводит к избыточности часто обновляемой информации о курсах. В такой базе данных сведения о курсе будут повторяться для каждого изучающего этот курс студента. Подобная избыточность может привести к нарушениям непротиворечивости данных. Поэтому мы оставляем два иерархических дерева.
Если же оставить только одно иерархическое дерево, то тем самым сократится число физических баз данных. С точки зрения производительности, уменьшение числа физических баз данных весьма существенный фактор. При этом учитываются такие количественные характеристики, как частота использования различных путей в иерархии, среднее число экземпляров сегментов различных типов, длины сегментов.
4. Упрощение имен ключей.
Имена ключей порожденных сегментов можно упростить, удалив те части имени, которые встречаются в имени исходного сегмента (см. средний рис. 6.8). В иерархии ключ физически порожденного сегмента косвенно подразумевает ключ исходного. Однако составные ключи, которые идентифицируют логически порожденные сегменты, связывающие исходные сегменты, принадлежащие различным иерархическим путям, сохраняются (см. правый рис. 6.8).
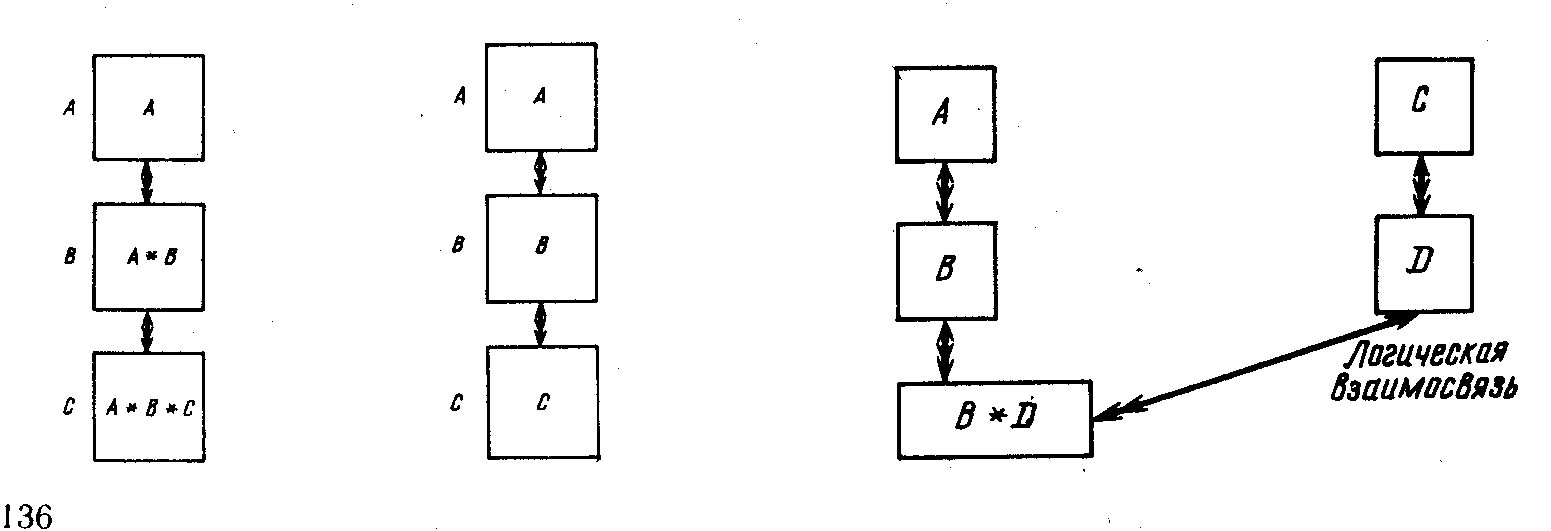

Рис. 6. 8
На рис. 6.7 единственный сегмент, в котором можно упростить ключ,- это СЕМЕСТР+КУРС+СТУДЕНТ – логически порожденный сегмент. Он связывает исходные сегменты, принадлежащие различным иерархическим путям. Нам приходится использовать составной ключ с атрибутами СЕМЕСТР, НОМ-КУРСА и НОМ-СТУДЕНТА.
5. Реализация взаимосвязей, неотраженных в логической модели, но, на самом деле, существующих.
Усовершенствованная логическая модель, представленная на рис. 6.7, удовлетворяет функциональным требованиям и обеспечивает, очевидно, более высокую производительность, чем первоначальная концептуальная модель, показанная на рис. 5.9. На этом можно было бы считать логическое конструирование, включающее отображение в иерархическую модель данных, завершенным. Однако проектировщик может пожелать его продолжить и добавить ряд внутренних (скрытых) взаимосвязей, существующих между данными. Речь идет о реально существующих взаимосвязях, определяемых организационными или физическими характеристиками моделируемой предметной области, но явно не сформулированных в концептуальных требованиях. Основная причина реализации упомянутой взаимосвязи состоит в том, что база данных должна обеспечивать получение ответов на произвольные запросы и легко адаптироваться для будущих применений.
Логическая модель данных для системы IMS, представленная на рис. 6.7, не нуждается в каких-либо изменениях.