

Коэффициенты ошибок
Появление ошибки в двоичной последовательности зависит от многих факторов и оценивается как случайное явление. Вероятность появления ошибки находится как предел отношения количества ошибок в переданной двоичной последовательности к общему числу элементов этой последовательности при условии, что общее число элементов последовательности стремится к бесконечности, т.е.
![]() .
.
В реальных условиях
выполнить требование
![]() невозможно. Поэтому при анализе используют
понятие частость ошибок или коэффициент
ошибок
невозможно. Поэтому при анализе используют
понятие частость ошибок или коэффициент
ошибок
![]() ,
который определяется как отношение
числа ошибочных элементов (комбинаций,
сообщений) в принятой последовательности
к общему числу принятых элементов
(комбинаций, сообщений) этой
последовательности:
,
который определяется как отношение
числа ошибочных элементов (комбинаций,
сообщений) в принятой последовательности
к общему числу принятых элементов
(комбинаций, сообщений) этой
последовательности:
![]()
При достаточно
большом
![]() величины
величины
![]() и
и
![]() мало отличаются друг от друга.
мало отличаются друг от друга.
В связи с выше сказанным различают следующие коэффициенты ошибок:
1. Коэффициент ошибок по элементам
![]()
где
![]() число
ошибочных элементов в переданном
сообщении,
число
ошибочных элементов в переданном
сообщении,
![]() общее число
элементов в переданном сообщении.
общее число
элементов в переданном сообщении.
В рассмотренном
выше примере
![]()
2. Коэффициент ошибок по комбинациям:
![]()
где
![]() число комбинаций принятых с ошибками
в переданном сообщении,
число комбинаций принятых с ошибками
в переданном сообщении,
![]() общее
число комбинаций в переданном сообщении.
общее
число комбинаций в переданном сообщении.
В рассмотренном
выше примере
![]()
3. Коэффициент ошибок по сообщениям:
![]()
где
![]() число
сообщений принятых с ошибками,
число
сообщений принятых с ошибками,
![]() общее
число принятых сообщений.
общее
число принятых сообщений.
В рассмотренном
выше примере![]()
Расчет вероятности ошибок
Вероятность появления ошибок можно вычислить, предположив, что ошибки появляются независимо друг от друга, т.е. представить появление ошибок как независимые случайные события (такие ошибки называют простейшими).
Будем считать, что
вероятность появления ошибки P
численно
равна вероятности появления искажения,
превышающего допустимое значение
![]() .
.
Вероятность превышения случайной величиной некоторого значения без учета знака может быть определена по формуле:
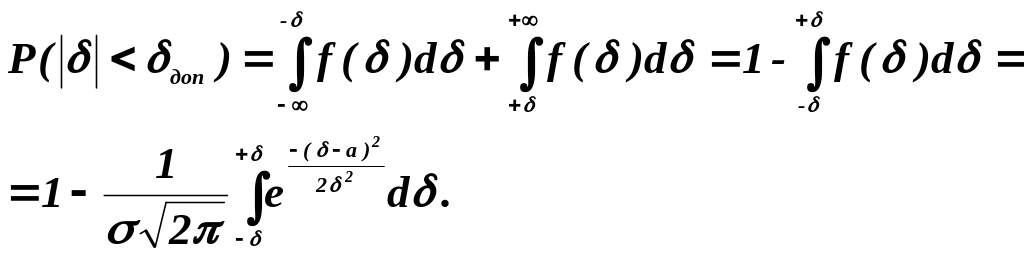
В выражении учтено, что, согласно исследованиям, проведенным с помощью анализатора искажений, закон распределения смещений границ принимаемых импульсов близок к нормальному.
Интеграл в этой формуле не выражается через элементарные функции, но его можно вычислить через функцию Лапласа, воспользовавшись соответствующими таблицами:
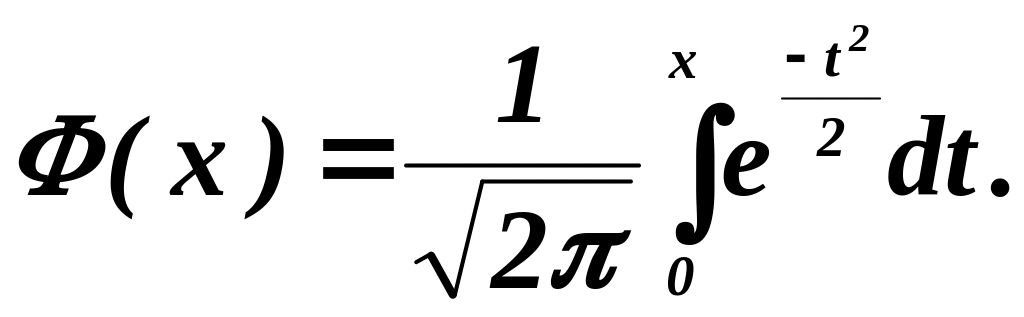
В этом случае вероятность ошибки при симметричной кривой распределения искажений (а = 0) равна:
![]() ,
,
где
![]()
Такой упрощенный метод расчета отличается простотой получения исходных данных и может быть рекомендован для ориентировочного анализа.
Математические модели ошибок
Для анализа механизма возникновения ошибок при аналитических исследованиях применяют математические модели ошибок, т.е. математическое описание процесса их появления.
Простейшей модель основана на предположении статистической независимости ошибок. При этом свойства канала как источника ошибок описываются лишь единственным параметром – вероятностью p ошибочного приема одного элемента.
Задача формулируется следующим образом: происходит испытание, состоящее в том, что по каналу связи передается кодовый элемент. Вероятность того, что этот кодовый элемент будет принят неверно (т.е. произойдет ошибка при передаче - событие A), равна p, тогда вероятность того, что ошибка не произойдет (т.е. событие А не наступит) равна q=1-p. Происходит n независимых испытаний, т.е. передается n кодовых элементов. Вероятность наступления события А в каждом испытании постоянна и равна p. Требуется определить вероятность наступления события А ровно k раз, если опыт повторялся n раз. Такая постановка задачи полностью соответствует схеме Бернулли, тогда имеем:
![]()
где
![]() число
ошибочно принятых элементов в кодовой
комбинации,
число
ошибочно принятых элементов в кодовой
комбинации,
![]() число сочетаний
из n
по
число сочетаний
из n
по
![]() .
.
Тогда вероятность
приема неискаженной комбинации
![]() равно
равно
![]()
Чтобы упростить дальнейшие выкладки, разложим данное выражение в ряд Маклорена, воспользовавшись известной формулой:
![]()
Беря два члена данного разложения и используя введенные обозначения, получим:
![]()
(Заметим, что данным разложением можно воспользоваться, т.к. вероятность p всегда меньше единицы).
Тогда вероятность приема ошибочной комбинации, т.е. комбинации, содержащей хотя бы одну ошибку, равна:
![]()
Результат получен
с достаточной для практики точностью,
т.к. вероятность неправильного приема
одного элемента p![]() .
.
Простейшая модель ошибок носит приближенный характер, дает грубое описание реальных каналов и может быть использована только для ориентировочных расчетов.
Все остальные известные модели ошибок основаны на допущении, что ошибки не являются независимыми, а группируются в пакеты.
Модель Э.Н.Гильберга основана на предложении, что при пакетном группировании поток ошибок может быть описан простым Марковским процессом. Согласно Э.Н.Гильберту, канал может находиться в одном из двух состояний: «хорошем» (ошибки не возможны) и «плохом», при этом ошибки полностью определяются матрицей переходных вероятностей:
![]()
где p00 – вероятность передачи по каналу «0» без ошибки,
p11 – вероятность передачи по каналу «1» без ошибки,
p01 – вероятность ошибки 0→1 при передачи по каналу,
p10 – вероятность ошибки 1→0 при передачи по каналу.
и вероятностью p0. Вероятности изменения состояний канала p01 и p10 должны быть значительно меньше вероятностей сохранения состояния канала p00 и p11. Эта модель хорошо описывает характер распределения ошибок в каналах с длинными и плотными пакетами ошибок.
Имеется ряд моделей,
дающих частичное описание канала.
Например, по одной из них можно определить
зависимость вероятности появления
ошибочной комбинации (Рок)
от ее длины n
и вероятности появления
![]() -
кратной ошибки в комбинации:
-
кратной ошибки в комбинации:
![]() ,
,
где - коэффициент группирования ошибок.
Если
![]() ,
то пакетирование ошибок отсутствует,
они считаются независимыми, и выражение
преобразуется в формулу, полученную по
схеме Бернулли.
,
то пакетирование ошибок отсутствует,
они считаются независимыми, и выражение
преобразуется в формулу, полученную по
схеме Бернулли.
Известна модель
Б.Бенета и Ф.Фройлиха основанная на
предположении, что ошибки группируются
в пакеты и что ошибки в пакете, как и
сами пакеты, возникают независимо друг
от друга. Для описания канала с ошибками
следует знать три параметра: вероятность
появления пакета ошибок любой длины
![]() ,
вероятность ошибки в пакете
,
вероятность ошибки в пакете
![]() и распределение вероятностей длин
пакетов ошибок
и распределение вероятностей длин
пакетов ошибок
![]()
![]() .
Основным недостатком рассматриваемой
модели является предположением о
независимости появления пакетов ошибок.
.
Основным недостатком рассматриваемой
модели является предположением о
независимости появления пакетов ошибок.
Ни одна модель не дает абсолютно точного описания реального процесса возникновения ошибок вследствие его сложности.