

Тема 13. Анализ и получение тренда. Методы аналитического выравнивания. Метод скользящего среднего. Метод экспоненциального сглаживания. Оценка точности трендовой модели.
Анализ тренда
Не существует "автоматического" способа обнаружения тренда во временном ряду. Однако если тренд является монотонным (устойчиво возрастает или убывает), то анализировать такой ряд обычно нетрудно. Если временные ряды содержат значительную ошибку, то первым шагом выделения тренда является сглаживание. Сглаживание всегда включает некоторый способ локального усреднения данных, при котором несистематические компоненты взаимно погашают друг друга. Самый общий метод сглаживания - скользящее среднее, в котором каждый член ряда заменяется простым или взвешенным средним m соседних членов, где m - ширина "окна". Также для выделения тренда широко используется метод экспоненциального сглаживания. Многие монотонные временные ряды можно хорошо описать линейной функцией. Если же имеется явная монотонная нелинейная компонента, то данные вначале следует преобразовать таким образом, чтобы устранить эту нелинейность. Чаще всего для этой цели используют логарифмическое, экспоненциальное или полиномиальное преобразование данных. Относительно реже, когда ошибка измерения очень большая, используется метод сглаживания методом наименьших квадратов, взвешенных относительно расстояния или метод отрицательного экспоненциально взвешенного сглаживания. Все эти методы отфильтровывают шум и преобразуют данные в относительно гладкую кривую.
Метод скользящего среднего
Среднее скользящее значение относится к категории аналитических инструментов, которые, как принято говорить, "следуют за тенденцией". Его назначение состоит в том, чтобы позволить определить время начала новой тенденции, а также предупредить о ее завершении или повороте. Методы скользящего среднего предназначены для отслеживания тенденций непосредственно в процессе их развития. Построение скользящего среднего представляет собой специальный метод сглаживания показателей.
Простое скользящее среднее, определяемое как среднее арифметическое значение, вычисляется по следующей формуле, при условии что m - нечетное число:
![]()
где
![]() ,-фактическое
значение i-го
уровня; т
- число
уровней, входящих в интервал сглаживания
(т
= 2р+ 1);
,-фактическое
значение i-го
уровня; т
- число
уровней, входящих в интервал сглаживания
(т
= 2р+ 1);
![]() ,
—
текущий уровень ряда динамики; i
- порядковый номер уровня в интервале
сглаживания; р
-
при нечетном т
имеет
значение р
= (т - 1)/2.
,
—
текущий уровень ряда динамики; i
- порядковый номер уровня в интервале
сглаживания; р
-
при нечетном т
имеет
значение р
= (т - 1)/2.
Интервал сглаживания, т.е. число входящих в него уровней т, определяют по следующим правилам. Когда необходимо сгладить незначительные, беспорядочные колебания, интервал сглаживания берут большим, если же требуется сохранить более незначительные колебания и освободиться лишь от периодически повторяющихся выбросов - интервал сглаживания обычно уменьшают.
Метод простого скользящего среднего используется обычно в тех случаях, когда график временного ряда представляет собой прямую линию, поскольку при этом динамика исследуемого явления не искажается. В том случае, когда тренд ряда имеет явно нелинейный характер и желательно сохранить незначительные колебания в динамике значений, этот метод не используется, так как его применение может привести к значительным искажениям исследуемого процесса. В таких случаях используется взвешенное скользящее среднее или методы экспоненциального сглаживания.
Практика показывает, что метод простого скользящего среднего позволяет выработать объективную стратегию и четко определенные правила. Как же можно использовать метод скользящего среднего? Наиболее распространенные способы применения скользящего среднего таковы:
1. Сопоставление значения текущей цены со скользящим средним, используемым в этом случае как индикатор тенденции. Так, если цены находятся выше 65-дневного скользящего среднего, то на рынке имеется промежуточная (краткосрочная) восходящая тенденция. В случае более долгосрочной тенденции цены должны быть выше 40-недельного скользящего среднего.
2. Использование скользящего среднего как уровня поддержки или сопротивления. Закрытие цен выше данного скользящего среднего служит "бычьим" сигналом, закрытие ниже его - "медвежьим".
3. Отслеживание полосы скользящего среднего (другое часто используемое название - конверт). Эта полоса ограничивается двумя параллельными линиями, которые располагаются на определенную процентную величину выше и ниже.
Простая и логически ясная модель временного ряда имеет следующий вид:
![]() ,
,
где
![]() - константа, а
- константа, а![]() -
случайная ошибка. Константа
-
случайная ошибка. Константа![]() относительно стабильна на каждом
временном интервале, но может также
медленно изменяться со временем. Один
из интуитивно ясных способов выделения
значения
относительно стабильна на каждом
временном интервале, но может также
медленно изменяться со временем. Один
из интуитивно ясных способов выделения
значения![]() из данных состоит в том, чтобы использовать
сглаживание скользящим средним, в
котором последним наблюдениям
приписываются большие веса, чем
предпоследним, предпоследним большие
веса, чем пред-предпоследним, и т.д.
Простое экспоненциальное сглаживание
именно так и построено. Здесь более
старым наблюдениям приписываются
экспоненциально убывающие веса, при
этом, в отличие от скользящего среднего,
учитываются все предшествующие наблюдения
ряда, а не только те, которые попали в
определенное окно. Точная формула
простого экспоненциального сглаживания
имеет вид:
из данных состоит в том, чтобы использовать
сглаживание скользящим средним, в
котором последним наблюдениям
приписываются большие веса, чем
предпоследним, предпоследним большие
веса, чем пред-предпоследним, и т.д.
Простое экспоненциальное сглаживание
именно так и построено. Здесь более
старым наблюдениям приписываются
экспоненциально убывающие веса, при
этом, в отличие от скользящего среднего,
учитываются все предшествующие наблюдения
ряда, а не только те, которые попали в
определенное окно. Точная формула
простого экспоненциального сглаживания
имеет вид:
![]()
![]() .
.
Когда
эта формула применяется рекурсивно,
каждое новое сглаженное значение
(которое является также прогнозом)
вычисляется как взвешенное среднее
текущего наблюдения и сглаженного ряда.
Очевидно, результат сглаживания зависит
от параметра
![]() .
Если
.
Если
![]() равен 1, то предыдущие наблюдения
полностью игнорируются. Если
равен 1, то предыдущие наблюдения
полностью игнорируются. Если
![]() равен 0, то игнорируются текущие
наблюдения. Значения а между 0 и 1 дают
промежуточные результаты. Эмпирические
исследования показали, что простое
экспоненциальное сглаживание весьма
часто дает достаточно точный прогноз.
На практике обычно рекомендуется брать
равен 0, то игнорируются текущие
наблюдения. Значения а между 0 и 1 дают
промежуточные результаты. Эмпирические
исследования показали, что простое
экспоненциальное сглаживание весьма
часто дает достаточно точный прогноз.
На практике обычно рекомендуется брать![]() меньше 0,30. Однако выбор
меньше 0,30. Однако выбор![]() больше 0,30 иногда дает более точный
прогноз. Это значит, что лучше все же
оценивать оптимальное значение
больше 0,30 иногда дает более точный
прогноз. Это значит, что лучше все же
оценивать оптимальное значение![]() по реальным данным, чем использовать
общие рекомендации.
по реальным данным, чем использовать
общие рекомендации.
На
практике оптимальный параметр сглаживания
часто ищется с использованием процедуры
поиска на сетке. Возможный диапазон
значений параметра разбивается сеткой
с определенным шагом. Например,
рассматривается сетка значений от
![]() = 0,1 до
= 0,1 до![]() = 0,9 с шагом 0,1. Затем выбирается такое
значение
= 0,9 с шагом 0,1. Затем выбирается такое
значение![]() ,
для которого сумма квадратов (или
средних квадратов) остатков (наблюдаемые
значения минус прогнозы на шаг вперед)
является минимальной.
,
для которого сумма квадратов (или
средних квадратов) остатков (наблюдаемые
значения минус прогнозы на шаг вперед)
является минимальной.
Метод аналитического выравнивания
Основным содержанием метода аналитического выравнивания временных рядов является расчет общей тенденции развития (тренда) как функции времени:
![]() ,
,
где
![]() ,
- теоретические значения временного
ряда, вычисленные по соответствующему
аналитическому уравнению на момент
времениt.
,
- теоретические значения временного
ряда, вычисленные по соответствующему
аналитическому уравнению на момент
времениt.
Определение
теоретических (расчетных) значений
![]() ,
производится
на основе
так
называемой
адекватной
математической модели, которая
наилучшим образом отражает основную
тенденцию развития временного ряда.
,
производится
на основе
так
называемой
адекватной
математической модели, которая
наилучшим образом отражает основную
тенденцию развития временного ряда.
Простейшими моделями (формулами), выражающими тенденцию развития, являются следующие:
линейная функция, график которой является прямой линией:
 ;
;показательная функция:
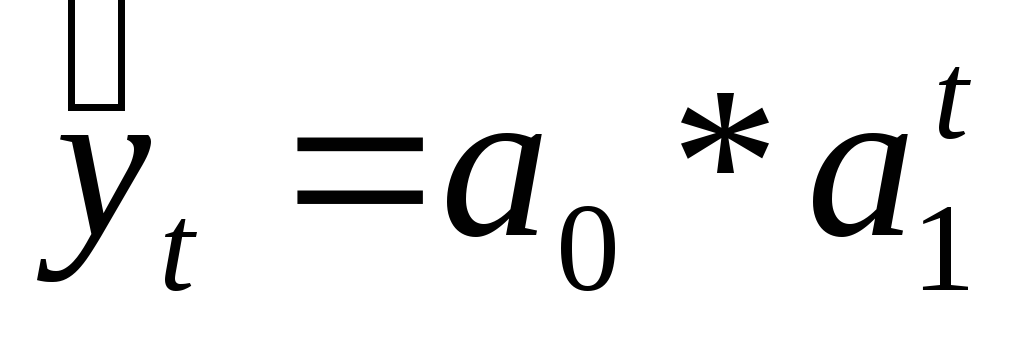 ;
;степенная функция второго порядка, график которой является параболой:
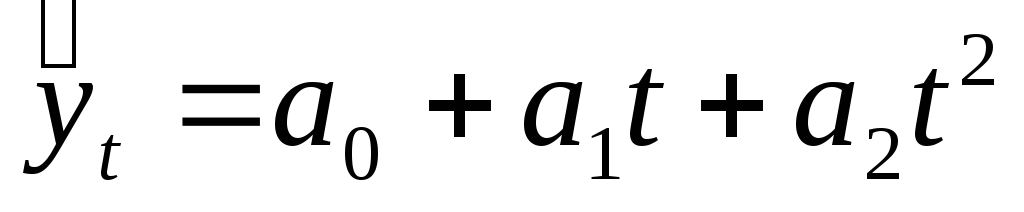 ;
;
-
логарифмическая функция:
![]() .
.
Расчет параметров функции обычно производится методом наименьших (МНК), в котором в качестве решения принимается точка минимума суммы квадратов отклонений между теоретическим и эмпирическим уровнями:
![]() ,
,
где
![]() ,
— выровненные (расчетные) уровни, ауi,
— фактические
уровни.
,
— выровненные (расчетные) уровни, ауi,
— фактические
уровни.
Параметры
уравнения
![]() ,
удовлетворяющие этому условию, могут
быть найдены решением системы нормальных
уравнений. На основе найденного уравнениятренда
вычисляются выровненные уровни.
,
удовлетворяющие этому условию, могут
быть найдены решением системы нормальных
уравнений. На основе найденного уравнениятренда
вычисляются выровненные уровни.
Выравнивание по прямой используется в тех случаях, когда абсолютные приросты практически постоянны, т е. когда уровни изменяются в арифметической прогрессии(или близко к ней).
Выравнивание по показательной функции применяется, когда ряд отражает развитие в геометрической профессии, т. е. цепные коэффициенты роста практически постоянны.
Выравнивание по степенной функции (параболе второго порядка) используется когда ряды динамики изменяются с постоянными цепными темпами прироста.
Выравнивание по логарифмической функции применяется, когда ряд отражает развитие с замедлением роста в конце периода, т.е. когда прирост в конечных уровнях временного ряда стремится к нулю.
По
вычисленным параметрам выполняется
синтез трендовой модели т.е. получение
значений
![]() и
их подстановка в искомое уравнение.
и
их подстановка в искомое уравнение.
Правильность расчетов аналитических уровней можно проверить по следующему условию: сумма значений эмпирического ряда должна совпадать с суммой вычисленных уровней выровненного ряда. При этом может возникнуть небольшая погрешность в расчетах из-за округления вычисляемых величин:
![]() .
.
Для оценки точности трендовой модели используется коэффициент детерминации:
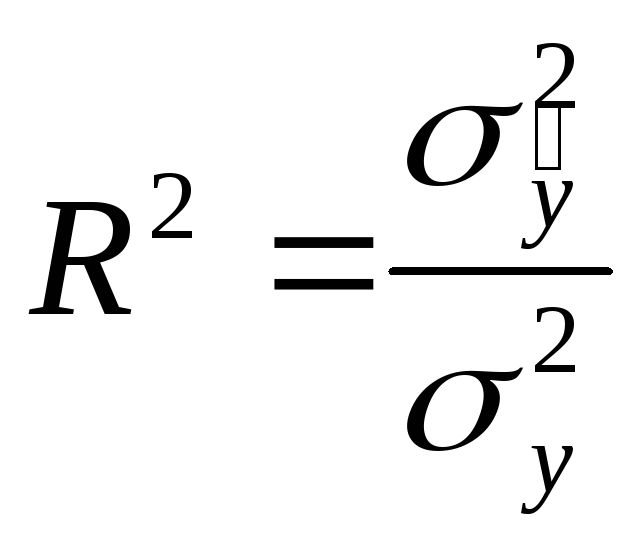 ,
,
где
![]() -
дисперсия теоретических данных,
полученных по трендовой модели, а
-
дисперсия теоретических данных,
полученных по трендовой модели, а
![]() -
дисперсия эмпирических данных.
-
дисперсия эмпирических данных.
Трендовая модель адекватна изучаемому процессу и отражает тенденцию его развития при значениях R2 близких к 1.
После выбора наиболее адекватной модели можно сделать прогноз на любой из периодов. При составлении прогнозов оперируют не точечной, а интервальной оценкой, определяя так называемые доверительные интервалы прогноза. Величина доверительного интервала определяется в общем виде следующим образом:
![]() ,
,
где
![]() -
среднее квадратическое отклонение от
тренда;
-
среднее квадратическое отклонение от
тренда;![]() -
табличное значение
-
табличное значение
критерия
Стьюдента при уровне значимости
![]() ,
которое зависит от уровня значимости
,
которое зависит от уровня значимости![]() (%) и числа степеней свободыk
=
n
- т.
(%) и числа степеней свободыk
=
n
- т.
Величина
![]() определяется по формуле:
определяется по формуле:
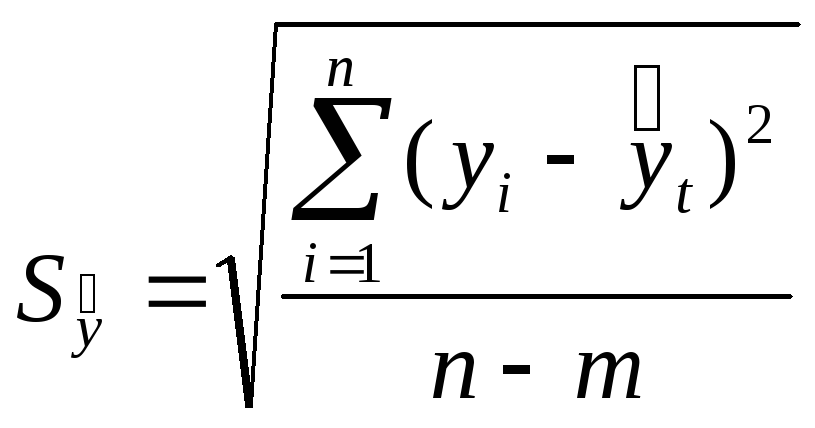 ,
,
![]() ,-
и
,-
и
![]() -
фактические
и расчетные значения уровней динамического
ряда; п-
число
уровней ряда; т
- количество
параметров в уравнении тренда (для
уравнения прямой т
=
2,
для уравнения
параболы 2-го порядка т
=
3). После необходимых расчетов определяется
интервал, в котором с определенной
вероятностью будет находиться
прогнозируемая величина.
-
фактические
и расчетные значения уровней динамического
ряда; п-
число
уровней ряда; т
- количество
параметров в уравнении тренда (для
уравнения прямой т
=
2,
для уравнения
параболы 2-го порядка т
=
3). После необходимых расчетов определяется
интервал, в котором с определенной
вероятностью будет находиться
прогнозируемая величина.
Литература:
1осн. [349-389], 2осн. [208-240], 3осн. [239-272], 4осн. [113-138], 4доп. [150-162].
Контрольные вопросы
1. Что такое тренд временных рядов?
2. Какова идея метода скользящего среднего?
3. Каковы особенности реализации метода скользящего среднего при выявлении тренда?
4. Какова идея метода экспоненциального сглаживания ?
5. Какова идея метода аналитического выравнивания?