

3.2 Формы представления и преобразования информации
3.2.1 . Кодирование и форматы представления числовых данных
В компьютере используются следующие формы представления числовых данных: числа с фиксированной запятой (точкой); числа с плавающей запятой (точкой).
Представление чисел в форме с фиксированной точкой получило название естественной формы числа, представление с плавающей точкой - нормальной формы числа. Под те или иные форматы всегда отводится заранее известное количество разрядов (бит) - 16, 32, и т.д.
Представление чисел в формате с фиксированной точкой. При представлении числа Х в форме с фиксированной точкой указывается знак числа ( sign X ) и модуль числа ( mod X ) в q - ичном коде. Место точки (запятой) постоянно для всех чисел и в процессе решения задач не меняется. Знак положительного числа кодируется цифрой 0 , а знак отрицательного числа - цифрой 1.
Код знака в форме с фиксированной точкой, состоящий из кода знака и q- ичного кода его модуля, называется прямым кодом q - ичного числа. Разряд прямого кода числа, в котором располагается q - ичный код модуля числа, называется знаковым разрядом кода. Разряды прямого кода числа, в которых располагаются q - ичный код модуля числа, называются цифровыми разрядами кода. При записи прямого кода знаковый разряд располагается левее старшего цифрового разряда и обычно отделяется от цифровых разрядов точкой. В общем случае разрядная сетка для размещения чисел в форме с фиксированной точкой выглядит так:

В формате с фиксированной точкой представляются целые числа, в формате с плавающей точкой - вещественные (целые и дробные).
Например, рассмотрим целое число Z1 = 28310 , если для целых чисел в памяти ЭВМ отводится 2 байта. Это число положительное, поэтому его знак кодируется как (0). Двоичный код этого числа Z1 = 1000110112 . Тогда это число в памяти ЭВМ будет расположено так:
Номера разрядов |
|||||||||||||||
Второй байт |
Первый байт |
||||||||||||||
15 |
14 |
13 |
12 |
11 |
10 |
9 |
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
1 |
1 |
Рассмотрим другой пример. Z2 = -2110 . Знак этого числа кодируется как (1), поскольку число отрицательное. Двоичный код этого числа Z2 = 101012 . Тогда это число в памяти ЭВМ будет расположено так:
Номера разрядов |
|||||||||||||||
Второй байт |
Первый байт |
||||||||||||||
15 |
14 |
13 |
12 |
11 |
10 |
9 |
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
1 |
Представление
чисел в формате с плавающей точкой. В
формате с плавающей точкой числа
представляются в виде мантиссы и
основания системы в соответствующей
степени. Любое число в этом формате
можно представить в виде:![]()
![]() ,
,
где m – мантисса числа, q – основание системы счисления, p – порядок.
Все эти величины - двоичные числа без знака. Для представления чисел в формате с плавающей точкой используются фиксированные форматы разной длины. В разрядной сетке форматов отводятся места для знака мантисс (нулевой разряд). Знака порядка (первый разряд), значение порядка (6 разрядов, со 2-го по 7-й), в остальные записывается мантисса числа.
Знак m |
Знак р |
Порядок р |
Мантисса m |
Любое число в формате с плавающей точкой можно представить в различной форме записи.
Пример. Х1 = -55,25 = -5525*10 -2 = -0,5525*10 2 , здесь мантисса m = -0,5525, а порядок p = 2 . Другой пример: Х2 = 0,0000000025324 = 2,5324*10-10 = 0,0025324*10 -7 , здесь мантисса m = 0,0025324, а порядок p = -7.
Обычно числа с плавающей точкой записываются в нормализованном виде т. е. в виде: Х1 = -0,5525*10 2 и Х2 = 0,25324*10-9 . Для числа Х1: знак мантиссы – отрицательный ( - ) – кодируется как (1); знак порядка – положительный ( + ) – кодируется как (0); мантисса m = 0,552510 = 0,1000112 ; порядок p = 210 =102 ;
Номера разрядов |
||||||||||||||||||||||||||||||||||||||||||||||||||||
0 |
1 |
2 |
|
|
|
|
7 |
8 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
31 |
|||||||||||||||||||||||
Зн m |
Зн p |
Порядок p |
Мантисса m |
|||||||||||||||||||||||||||||||||||||||||||||||||
1 |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
1 |
1 |
0 |
|
|
|
|
|
|
. |
. |
. |
|
|
|
|
|
|
|
||||||||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Аналогично выполняются действия для второго числа Х2:
Выполнение арифметических операций с целыми числами, представленными машинными кодами. Для хранения чисел и выполнения различных операций над ними их представляют различными кодами: прямым, обратным и дополнительным. Основные отличия кодов чисел от самих чисел заключаются в следующем: разряды числа в коде жестко связаны с определенной разрядной сеткой; для записи кода знака в разрядной сетке отводится постоянно строго определенный разряд.
Код числа в форме с фиксированной точкой, состоящий из кода знака и двоичного кода его модуля, называется прямым кодом двоичного числа. Для его записи в разрядную сетку необходимо выполнить следующие операции:
записать двоичный код целого числа;
недостающие цифры старших разрядов двоичного кода заменить нулями с тем, чтобы все разряды разрядной сетки были заполнены;
в старший разряд (8 – й или 15 – й) записать код знака: 0 – для положительного числа и 1 – для отрицательного числа.
Обратный и дополнительный коды применяются для кодирования только отрицательных чисел.
Правила образования обратного и дополнительного двоичных машинных кодов.
1. Положительное число в прямом, обратном и дополнительном кодах выглядят одинаково.
2. Прямой код отрицательных и положительных чисел имеет различное значение только в знаковом разряде, модуль числа не изменяется.
3. Обратный код двоичного отрицательного числа получается из прямого кода путем замены единиц на нули и нулей на единицы, только код знака оставить без изменения.
Пример. .
Х2 = +1101101 [Х2]пр = 0.1101101 [Х2]обр = 0.0010010
Х2 = -0101101 [Х2]пр = 1.0101101 [Х2]обр = 1.1010010
Здесь точкой отделяется знак числа (его код) от двоичного кода самого числа. Для простоты изложения рассматривается восьмиразрядная сетка.
4. Дополнительный код отрицательного числа получается формированием обратного кода отрицательного числа и прибавлением единицы к младшему разряду этого кода (перенос в знаковый разряд при этом теряется).
Пример.
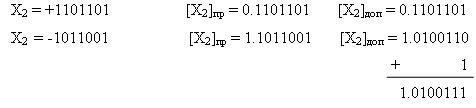
Арифметические действия над целыми числами, представленными в обратном или дополнительном машинном коде. При сложении чисел, представленных в естественной форме, необходимо учитывать следующие положения:
числа хранятся в памяти компьютера в дополнительном коде;
числа складываются вместе со знаками, при этом формируется знак результата;
при сложении чисел с разными знаками единица переноса из знакового разряда отбрасывается.
Сложение чисел. При сложении чисел нужно использовать вышеприведённые правила сложения двоичных разрядов (3.4).
Вычитание чисел. Рассмотрим операцию вычитания, которая выполняется следующим образом: определяется дополнительный или обратный код вычитаемого числа и производится сложение этого кода с уменьшаемым числом. А - В = А + [- В]обр-доп
Вычитание чисел, представленных в обратном коде. Если при выполнении операции сложения чисел формируется перенос из знакового разряда, при использовании обратного кода, он должен быть добавлен в младший разряд результата.
3.2.2 . Кодирование и формат представления символьной информации. Кодирование информации - процесс формирования определенного представления информации. В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки. Обратное преобразование называется декодированием. Способ кодирования зависит от цели, ради которой оно осуществляется: сокращение записи, засекречивание (шифровка) информации, удобство обработки и т. д. Полный набор символов, используемый для кодирования текста, называется алфавитом или азбукой.
Кодирование текстовых данных. Компьютер может обрабатывать информацию, представленную только в числовой форме. Вся другая информация должна быть преобразована в числовую форму. Например, текст в книге состоит из букв и других символов. Буква - это элементарная часть текстовой информации. Информация называется закодированной, если любая ее элементарная часть представлена в виде числа. Такие числа называются кодами. Текст можно закодировать, если каждую букву заменить кодом, например, номером буквы в алфавите.
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы.
Для английского языка, захватившего де-факто нишу международного средства общения институт стандартизации США (ANSI — American National Standard Institute) ввел в действие систему кодирования ASCII (American Standard Code for Information Interchange — стандартный код информационного обмена США). В системе ASCII закреплены две таблицы кодирования — базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (в первую очередь производителям компьютеров и печатающих устройств). В этой области размещаются так называемые управляющие коды, которым не соответствуют никакие символы языков, и, соответственно, эти коды не выводятся ни на экран, ни на устройства печати, но ими можно управлять тем, как производится вывод прочих данных.
Начиная с кода 32 по код 127 размещены коды символов английского алфавита, знаков препинания, цифр, арифметических действий и некоторых вспомогательных символов.
Таблица 3.4 - Базовая таблица кодировки ASCII
32 пробел |
48 0 |
64 @ |
80 Р |
96 |
112 p |
33 ! |
49 1 |
65 А |
81 Q |
97 а |
113 q |
34 |
50 2 |
66 В |
82 R |
98 b |
114 r |
35 # |
51 3 |
67 С |
83 S |
99 с |
115 s |
36 $ |
52 4 |
68 D |
84 Т |
100 d |
116 t |
37 % |
53 5 |
69 Е |
85 U |
101 е |
117 u |
38 & |
54 6 |
70 F |
86 V |
102 f |
118 v |
39 |
55 7 |
71 G |
87 W |
103 g |
119 w |
40 ( |
56 8 |
72 Н |
88 X |
104 h |
120 x |
41 ) |
57 9 |
73 I |
89 Y |
105 i |
121 у |
42 |
58 : |
74 J |
90 Z |
106 j |
122 z |
43 + |
59 ; |
75 К |
91 [ |
107 k |
123 { |
44 |
60 < |
76 L |
92 \ |
108 I |
124 | |
45 |
61 |
77 М |
93 ] |
109 m |
125 } |
46 |
62 > |
78 N |
94 |
110 n |
126 |
47 / |
63 ? |
79 0 |
95 |
111 0 |
127 |
Аналогичные системы кодирования текстовых данных были разработаны и в других странах. Так, например, в СССР в этой области действовала система кодирования КОИ-7 (код обмена информацией, семизначный). Однако поддержка производителей оборудования и программ вывела американский код ASCII на уровень международного стандарта, и национальным системам кодирования пришлось «отступить» во вторую, расширенную часть системы кодирования, определяющую значения кодов со 128 по 255.
Кодировка символов русского языка, известная как кодировка Windows-1251, была введена— компанией Microsoft. Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows
Таблица 3.5 - Кодировка Windows 1251
128 Ъ |
144 f) |
160 |
176 ' |
192 A |
208 Р |
224 а |
240 р |
129 Г |
145 ' |
161 У |
177 ± |
193 Б |
209 С |
225 б |
241 с |
130 , |
146 ' |
162 у |
178 I |
194 В |
210 Т |
226 в |
242 т |
131 f- |
147 " |
163 J |
179 i |
195 Г |
211 У |
227 г |
243 у |
132 „ |
148 " |
164 П |
180 f |
196 Д |
212 Ф |
228 д |
244 ф |
133 ... |
149 • |
165 Г |
181 м |
197 Е |
213 X |
229 е |
245 х |
134 f |
150 - |
166 | |
182 1| |
198 Ж |
214 Ц |
230 ж |
246 ц |
135 f |
151 — |
167 § |
183 • |
199 3 |
215 Ч |
231 з |
247 ч |
136 ' |
152 ' |
168 Ё |
184 ё |
200 И |
216 Ш |
232 и |
248 ш |
137 %o |
153 ™ |
169 © |
185 № |
201 И |
217 Щ |
233 и |
249 щ |
138 Лэ |
154 !Ъ |
170 6 |
186 е |
202 К |
218 Ъ |
234 к |
250 ъ |
139 < |
155 > |
171 « |
187 » |
203 Л |
219 Ы |
235 л |
251 ы |
140 ЬЬ |
156 № |
172 - |
188 j |
204 М |
220 Ь |
236 м |
252 ь |
141 К |
157 к |
173 - |
189 S |
205 Н |
221 Э |
237 н |
253 э |
142 Ъ |
158 Т\ |
174 ® |
190 s |
206 О |
222 Ю |
238 о |
254 ю |
143 М |
159 у |
175 Т |
191 I |
207 П |
223 Я |
239 п |
255 я |
Международный стандарт, в котором предусмотрена кодировка символов русского алфавита, носит название кодировки ISO (International Standard Organization — Международный институт стандартизации). На практике данная кодировка используется редко.
Универсальная система кодирования текстовых данных. Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной — UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов — этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
Один байт - это не только единица информации, это элементарная ячейка памяти. Память компьютера состоит из последовательности таких ячеек. Каждая ячейка (байт) содержит двоичный код, который хранится в ней. Каждый разряд двоичного числа представляется физическим элементом, обладающим двумя устойчивыми состояниями, одному из которых приписывается значение 0, а другому - 1. Совокупность определенного количества этих элементов служит для представления многоразрядных чисел и составляет разрядную сетку. В компьютерах кодируемая информация записывается в разрядную сетку. Рассмотрим восьмиразрядную сетку:
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
Символьная информация представляет собой последовательность знаков, представленных в коде. Например,
Л Е Т О А В В А
ЛЕТО - 203 197 210 206 АВВА - 65 66 66 65
Чтобы записать символьную информацию в разрядную сетку компьютера, ее надо закодировать, затем код каждого символа перевести в двоичную систему счисления.
Пример. Закодируем слово «ЛЕТО»: переведем в двоичную систему:
Л Е Т О
20310 = 11001011 2 19710 = 11000101 2 21010 = 11010010 2 20610 = 11001110 2
и запишем в разрядную сетку. Запись символьной информации:
Л |
Е |
||||||||||||||
1 |
1 |
0 |
0 |
1 |
0 |
1 |
1 |
1 |
1 |
0 |
0 |
0 |
1 |
0 |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Т |
О |
||||||||||||||
1 |
1 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
1 |
0 |
0 |
1 |
1 |
1 |
0 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Кодирование графических данных. Если рассмотреть с помощью увеличительного стекла черно-белое графическое изображение, напечатанное в газете или книге, то можно увидеть, что оно состоит из мельчайших точек, образующих характерный узор, называемый растром.
Поскольку линейные координаты и индивидуальные свойства каждой точки (яркость) можно выразить с помощью целых чисел, то можно сказать, что растровое кодирование позволяет использовать двоичный код для представления графических данных. Общепринятым на сегодняшний день считается представление черно-белых иллюстраций в виде комбинации точек с 256 градациями серого цвета, и, таким образом, для кодирования яркости любой точки обычно достаточно восьмиразрядного двоичного числа.
Для кодирования цветных графических изображений применяется принцип декомпозиции произвольного цвета на основные составляющие. В качестве таких составляющих используют три основные цвета: красный (Red, R), зеленый (Green, G) и синий (Blue, В). На практике считается (хотя теоретически это не совсем так), что любой цвет, видимый человеческим глазом, можно получить путем механического смешения этих трех основных цветов. Такая система кодирования называется системой RGB по первым буквам названий основных цветов.
Если для кодирования яркости каждой из основных составляющих использовать по 256 значений (восемь двоичных разрядов), как это принято для полутоновых черно-белых изображений, то на кодирование цвета одной точки надо затратить 24 разряда. При этом система кодирования обеспечивает однозначное определение 16,5 миллионов различных цветов, что на самом деле близко к чувствительности человеческого глаза. Режим представления цветной графики с использованием 24 двоичных разрядов называется полноцветным (True Color).
Каждому из основных цветов можно поставить в соответствие дополнительный цвет, то есть цвет, дополняющий основной цвет до белого. Нетрудно заметить, что для любого из основных цветов дополнительным будет цвет, образованный суммой пары остальных основных цветов. Соответственно, дополнительными цветами являются: голубой (Cyan, С), пурпурный (Magenta, M) и желтый (Yellow, У). Принцип декомпозиции произвольного цвета на составляющие компоненты можно применять не только для основных цветов, но и для дополнительных, то есть любой цвет можно представить в виде суммы голубой, пурпурной и желтой составляющей. Такой метод кодирования цвета принят в полиграфии, но в полиграфии используется еще и четвертая краска — черная (Black, К). Поэтому данная система кодирования обозначается четырьмя буквами CMYK (черный цвет обозначается буквой К, потому, что буква В уже занята синим цветом), и для представления цветной графики в этой системе надо иметь 32 двоичных разряда. Такой режим тоже называется полноцветным (True Color).
Если уменьшить количество двоичных разрядов, используемых для кодирования цвета каждой точки, то можно сократить объем данных, но при этом диапазон кодируемых цветов заметно сокращается. Кодирование цветной графики 16-разрядными двоичными числами называется режимом High Color.
При кодировании информации о цвете с помощью восьми бит данных можно передать только 256 цветовых оттенков. Такой метод кодирования цвета называется индексным. Смысл названия в том, что, поскольку 256 значений совершенно недостаточно, чтобы передать весь диапазон цветов, доступный человеческому глазу, код каждой точки растра выражает не цвет сам по себе, а только его номер (индекс) в некоей справочной таблице, называемой палитрой. Разумеется, эта палитра должна прикладываться к графическим данным — без нее нельзя воспользоваться методами воспроизведения информации на экране или бумаге (то есть, воспользоваться, конечно, можно, но из-за неполноты данных полученная информация не будет адекватной: листва на деревьях может оказаться красной, а небо — зеленым).
Кодирование звуковой информации. Приемы и методы работы со звуковой информацией пришли в вычислительную технику наиболее поздно. К тому же, в отличие от числовых, текстовых и графических данных, у звукозаписей не было столь же длительной и проверенной истории кодирования. В итоге методы кодирования звуковой информации двоичным кодом далеки от стандартизации. Множество отдельных компаний разработали свои корпоративные стандарты, но если говорить обобщенно, то можно выделить два основных направления.
Метод FM (Frequency Modulation) основан на том, что теоретически любой сложный звук можно разложить на последовательность простейших гармонических сигналов разных частот, каждый из которых представляет собой правильную синусоиду, а следовательно, может быть описан числовыми параметрами, то есть кодом. В природе звуковые сигналы имеют непрерывный спектр, то есть являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства — аналогово-цифровые преобразователи (АЦП). Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи (ЦАП). При таких преобразованиях неизбежны потери информации, связанные с методом кодирования, поэтому качество звукозаписи обычно получается не вполне удовлетворительным и соответствует качеству звучания простейших электромузыкальных инструментов с окрасом, характерным для электронной музыки. В то же время данный метод кодирования обеспечивает весьма компактный код, и потому он нашел применение еще в те годы, когда ресурсы средств вычислительной техники были явно недостаточны.
Метод таблично-волнового (Wave-Table) синтеза лучше соответствует современному уровню развития техники. Если говорить упрощенно, то можно сказать, что где-то в заранее подготовленных таблицах хранятся образцы звуков для множества различных музыкальных инструментов (хотя не только для них). В технике такие образцы называют сэмплами. Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения, некоторые параметры среды, в которой происходит звучание, а также прочие параметры, характеризующие особенности звука. Поскольку в качестве образцов используются «реальные» звуки, то качество звука, полученного в результате синтеза, получается очень высоким и приближается к качеству звучания реальных музыкальных инструментов.