

Определение понятия "архитектура"
Термин "архитектура системы" часто употребляется как в узком, так и в широком смысле этого слова. В узком смысле под архитектурой понимается архитектура набора команд. Архитектура набора команд служит границей между аппаратурой и программным обеспечением и представляет ту часть системы, которая видна программисту или разработчику компиляторов. Следует отметить, что это наиболее частое употребление этого термина. В широком смысле архитектура охватывает понятие организации системы, включающее такие высокоуровневые аспекты разработки компьютера как систему памяти, структуру системной шины, организацию ввода/вывода и т.п.
Применительно к вычислительным системам термин "архитектура" может быть определен как распределение функций, реализуемых системой, между ее уровнями, точнее как определение границ между этими уровнями. Таким образом, архитектура вычислительной системы предполагает многоуровневую организацию. Архитектура первого уровня определяет, какие функции по обработке данных выполняются системой в целом, а какие возлагаются на внешний мир (пользователей, операторов, администраторов баз данных и т.д.). Система взаимодействует с внешним миром через набор интерфейсов: языки (язык оператора, языки программирования, языки описания и манипулирования базой данных, язык управления заданиями) и системные программы (программы-утилиты, программы редактирования, сортировки, сохранения и восстановления информации).
Интерфейсы следующих уровней могут разграничивать определенные уровни внутри программного обеспечения. Например, уровень управления логическими ресурсами может включать реализацию таких функций, как управление базой данных, файлами, виртуальной памятью, сетевой телеобработкой. К уровню управления физическими ресурсами относятся функции управления внешней и оперативной памятью, управления процессами, выполняющимися в системе.
Следующий уровень отражает основную линию разграничения системы, а именно границу между системным программным обеспечением и аппаратурой. Эту идею можно развить и дальше и говорить о распределении функций между отдельными частями физической системы. Например, некоторый интерфейс определяет, какие функции реализуют центральные процессоры, а какие - процессоры ввода/вывода. Архитектура следующего уровня определяет разграничение функций между процессорами ввода/вывода и контроллерами внешних устройств. В свою очередь можно разграничить функции, реализуемые контроллерами и самими устройствами ввода/вывода (терминалами, модемами, накопителями на магнитных дисках и лентах). Архитектура таких уровней часто называется архитектурой физического ввода/вывода.
Архитектуры cisc и risc
Здесь рассматриваются базовые свойства архитектур CISC и RISC, а также особенности интеграции элементов RISC-архитектуры в процессорах x86. Особое внимание уделяется описанию преимуществ и недостатков этой интеграции. Показано естественность взаимообогащения CISC и RISC-процессоров эффективными аппаратно-программными решениями, а также практичность развития процессоров в этом направлении.
Организация первых моделей процессоров - i8086/8088 - была направлена, в частности, на сокращение объёма программ, критичного для систем того времени, отличавшихся малой оперативной памятью. Расширение спектра операций, реализуемых системой команд, позволило уменьшить размер программ, а также трудоёмкость их написания и отладки. Однако увеличение числа команд повысило трудоёмкость разработки их топологических и микропрограммных реализаций.
Последнее проявилось в удлинении сроков разработки CISC-процессоров, а также в проявлении различных ошибок в их работе. Кроме того, нерегулярность потока команд ограничила развитие топологии временным параллелизмом обработки инструкций на конвейере "выборка команды- дешифрация команды- выборка данных- вычисление- запись результата".
Эти недостатки обусловили необходимость разработки альтернативной архитектуры, нацеленной, прежде всего, на снижение нерегулярности потока команд уменьшением их общего количества. Это было реализовано в RISC-процессорах, название которых означает "чипы с сокращённой системой команд" (Reduced Instruction Set Computer). Одновременно "классические" процессоры получили обозначение CISC (Complex Instruction Set Computer) - компьютер со сложным набором инструкций.
Сокращение нерегулярности потока команд позволило обогатить топологию RISC-процессоров пространственным параллелизмом, специализированными аппаратными АЛУ (ALU - блок логики и арифметики = Arithmetic (and) Logic Unit), независимыми кэш данных и команд, раздельными шинами ввода-вывода. Последние, в частности, увеличили длину конвейеров команд. Всё это повысило и производительность - увеличением числа операций, выполняемых за один такт, и быстродействие - сокращением пути транзактов - RISC-процессоров. При этом срок разработки данных чипов свидетельствует о том, что её трудоёмкость меньше, чем в случае CISC-процессоров.
На мировых рынках CISC-процессоры представлены, в основном, клонами процессоров Intel серии x86, производимыми AMD, Cyrix, а RISC - чипами Alpha, PowerPC, SPARC. Уступая во многом последним, процессоры x86 сохранили лидерство на рынке персональных систем лишь благодаря совместимости с программным обеспечением младших моделей, общая стоимость которого - в начале 90-х годов - составила несколько миллиардов долларов США. В свою очередь, достоинства RISC-процессоров укрепили их позиции на более молодом рынке высокопроизводительных машин.
Несмотря на формальное разделение "сфер влияния", между представителями этих архитектур в начале 90-х годов началась острая конкуренция за превентивное улучшение характеристик. В первую очередь, производительности и её отношения к трудоёмкости разработки процессоров. Следуя принципу "бить врага его оружием", создатели и CISC, и RISC-процессоров нередко боролись с конкурентами, заимствуя их удачные решения.
Первыми на то решились разработчики Intel, реализовавшие в i486 пространственный параллелизм вычислений с фиксированной и плавающей запятой. Поддержка каждого АЛУ своей шиной данных/команд и регистровым блоком повысила производительность i486 одновременным выполнением указанных команд. Кроме того, интеграция кэш и очереди команд позволила поднять частоту ядра процессора в 2-3 раза в сравнении с системной шиной. Однако совместное размещение данных и команд ограничило эффективность кэш необходимостью его полной перезагрузки после выполнения команд переходов.
Для устранения недостатка в Pentium реализованы раздельные кэш для команд и данных, позволяющие после переходов перезагружать лишь команды - такое решение называется Гарвардской архитектурой, а также предсказание переходов, снижающее частоту перезагрузок. Последнее достигается предварительной загрузкой в кэш команд с обоих разветвлений. Введение второго целочисленного тракта, состоящего из АЛУ, адресного блока, шин данных/команд, и работающего на общий блок регистров, повысило производительность поддержкой параллельной обработки целочисленных данных. Развитием данной тенденции стало обогащение Pentium MMX мультимедийным трактом, образованным АЛУ, шинами данных/команд и регистровым файлом.
При этом в случае выборки двух целочисленных команд, зависящих по данным, каждая из них выполняется последовательно, что снижает эффективность работы процессора. Частично поправило ситуацию создание оптимизирующих рекомпиляторов, например, Pen_Opt фирмы Intel, разделяющих по возможности такие команды.
Реализация описанного управления обработкой команд CISC-формата вызвала дополнительный рост трудоёмкости разработки Pentium в сравнении с i8086/i486, что привело не только к увеличению её реального срока на 27% в сравнении с ожидаемым, но и к проявлению ошибок в первых моделях данного процессора.
Учтя это, компания Intel реализовала в Pentium Pro RISC-подобную организацию вычислений. Интерпретация команд х86 внутренними - RISC86 - инструкциями VLIW-формата помимо снижения нерегулярности их потока, обеспечила синхронную загрузку четырёх операционных - по два с плавающей и фиксированной запятой - АЛУ этого чипа. Термин VLIW расшифровывается как "очень длинное командное слово" (Very Long Instruction Word). Инструкции этого формата содержат команды для всех параллельных АЛУ.
Обогащение управления обработкой предвыборкой данных и команд, предполагаемых к обработке в ближайшие 20 тактов, повысило регулярность загрузки вычислительных трактов. В свою очередь, осуществление предвыборки из интегрированного на кристалле кэш второго уровня, обслуживаемого раздельными шинами "интерфейс-кэш" и "кэш-АЛУ" и работающего на частоте АЛУ, повысило быстродействие подготовки команд в сравнении с внешними кэш. Дополнительное повышение производительности Pentium Pro обеспечило увеличение длины команд до 11 ступеней введением ступеней трансляции и предвыборки. Кроме того, интеграция кэш второго уровня позволила умножать частоту ядра в 5-6 раз.
В архитектуре Р6 RISC-решения впервые в семействе х86 перестали быть лишь дополнением исконных CISC-средств повышения производительности - роста разрядности, отложенной записи шины и других. Поэтому частица PRO в названии первого процессора этой серии обозначает "Полноценная RISC-архитектура" (Precision RISC Organization).
Топологические новинки Pentium II - интеграция тракта MMX, мультипроцессорный интерфейс Xeon, вынесение кэш второго уровня на кристалл в корпусе чипа, как и полное устранение кэш второго уровня в Celeron, не имеют в данном случае качественной роли и направлены на оптимизацию отношения характеристик этих процессоров, к их цене.
При этом сокращение нерегулярности потока RISC86-инструкицй ограничило рост требований к развитию управления вычислениями в сравнении с Pentium. Одновременно снижение трудоёмкости разработки аппаратно-программных реализаций алгоритмов работы Pentium Pro, достигнутое развитием САПР, ослабило влияние развития обработки данных, оцениваемого ростом объёма информации, заложенной в реализациях этой обработки, на общую трудоёмкость разработки процессоров, оцениваемую её длительностью.
Последнее создало возможность оптимизации соотношения характеристик чипов и их трудоёмкости не снижением последней ограничением внедрения прогрессивных решений в CISC-архитектуру или ограничением функциональных возможностей RISC-процессоров, а ростом характеристик, достигаемым сочетанием преимуществ упомянутых архитектур.
Сказанное иллюстрирует и организация современных RISC-процессоров. Их отличает, в данном случае, развитие систем команд с целью сохранения иерархической совместимости и снижения трудоёмкости разработки программ. Это сближает технологии обработки команд процессорами упомянутых архитектур. Например, SuperSparc взяли от последних моделей х86 предсказание переходов и предварительную интерпретацию кода.
Таким образом, развиваясь, каждая из рассмотренных архитектур, "отказавшись" от своих черт - CISC от скалярности вычислений, RISC от "простоты" системы команд, приобрела лучшие черты конкурента, что повысило характеристики её представителей.
Это подтверждает и процессор Merced, разрабатываемый недавними противниками - Intel и Hewlett Packard. Имеющиеся сведения позволяют предположить, что его архитектура продолжит тенденции Pentium Pro по оптимизации обработки внутренних VLIW-подобных команд реализацией эффективных архитектурных решений при одновременной оптимизации преобразования "внешних" инструкций. Особо отмечаются намерения создания двух вариантов этого чипа, различающихся лишь множеством этих инструкций. Первый будет совместим с CISC-семейством x86, второй - с RISC-процессорами Alpha.
Будучи "един в двух лицах", Merced ознаменует прекращение соперничества CISC и RISC, в ходе которого представители данных архитектура улучшили свои характеристики реализацией лучших аппаратно-программных решений конкурентов. Это позволяет предположить, что дальнейшее развитие массовых процессоров пройдёт по пути развития топологических и микропрограммных решений вычислительного ядра RISC-организации при одновременном повышении возможностей CISC-подобной "внешней" системы команд.
Требования к характеристикам внешнего тактового сигнала
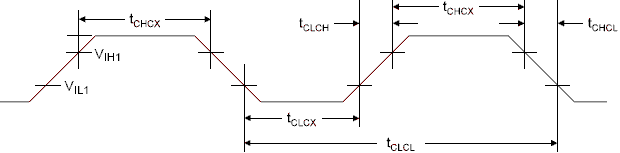 Рисунок
152. Осциллограмма внешнего тактового
сигнала
Рисунок
152. Осциллограмма внешнего тактового
сигнала
Таблица 132. Параметры внешнего тактового сигнала
Обозначение |
Параметр |
VCC = 2.7В…5.5В |
VCC = 4.5В…5.5В |
Ед.изм. |
||
мин. |
макс. |
мин. |
макс. |
|||
1/tCLCL |
Частота генератора |
0 |
8 |
0 |
16 |
МГц |
tCLCL |
Период синхронизации |
125 |
|
62,5 |
|
нс |
tCHCX |
Длительность единичного импульса |
50 |
|
25 |
|
нс |
tCLCX |
Длительность нулевого импульса |
50 |
|
25 |
|
нс |
tCLCH |
Длительность нарастающего фронта |
|
1,6 |
|
0,5 |
мкс |
tCHCL |
Длительность падающего фронта |
|
1,6 |
|
0,5 |
мкс |
tCLCL |
Разброс периодов смежных импульсов |
|
2 |
|
2 |
% |
Таблица 133. Типичные частоты при тактировании от внешней RC-цепи
R, кОм |
C, пФ |
f |
100 |
70 |
TBD(2) |
31,5 |
20 |
TBD(2) |
6,5 |
20 |
TBD(2) |
Прим.:
Сопротивление R должно находиться в пределах 3 кОм…100 кОм, а емкость не менее 20 пФ. Значения C представлены в таблице с учетом емкости вывода микроконтроллера. Емкость вывода может варьироваться в зависимости от типа корпуса.
TBD означает, что точное значение величины находится в состоянии определения.
МП 80386 фирмы Intel
МП 80386 вышел на рынок с уникальным преимуществом. Он является единственным 32-разрядным МП, для которого пригодно существующее прикладное программное обеспечение стоимостью 6,5 млрд. долл., написанное для МП предыдущих моделей от 8086/88 до 80286 (клон IBM PC).
Говорят, что системы совместимы, если программы, написанные на одной системе, успешно выполняются на другой. Если совместимость распространяется только в одном направлении, от старой системы к новой, то говорят о совместимости снизу вверх. Совместимость снизу вверх на объектном уровне поддерживает капиталовложения конечного пользователя в программное обеспечение, поскольку новая система просто заменяет более медленную старую. Микропроцессор 80386 совместим снизу вверх с предыдущими поколениями МП фирмы Intel. Это означает, что программы, написанные специально для МП 80386 и использующие его специфические особенности, обычно не работают на более старых моделях. Однако, так как набор команд МП 80386 и его модули обработки являются расширениями набора команд предшествующих моделей, программное обеспечение последних совместимо снизу вверх с МП 80386.
Специфическими особенностями МП 80386 являются многозадачность, встроенное управление памятью, виртуальная память с разделением на страницы, защита программ и большое адресное пространство. Аппаратная совместимость с предыдущими моделями сохранена посредством динамического изменения разрядности магистрали.
МП 80386 выполнен на основе технологии CHMOS III фирмы Intel, которая вобрала в себя быстродействие технологии HMOS (МДП высокой плотности) и малое потребление мощности технологии CMOS (КМДП). МП 80386 предусматривает переключение программ, выполняемых под управлением различных операционных систем, таких как MS-DOS и UNIX. Это свойство позволяет разработчикам программ включать стандартное прикладное программное обеспечение для 16-разрядных МП непосредственно в 32-разрядную систему. Процессор определяет адресное пространство как один или несколько сегментов памяти любого размера в диапазоне от 1 байт до 4 Гбайт (4·230 байт). Эти сегменты могут быть индивидуально защищены уровнями привилегий и таким образом избирательно разделяться различными задачами. Механизм защиты основан на понятии иерархии привилегий или ранжированного ряда. Это означает, что разным задачам или программам могут быть присвоены определенные уровни, которые используются исключительно для данной задачи.