

Раздел IV. Методика обработки информации л.Н. Маслова, м.Л. Суховский совершенствование методики обработки анкетных данных на счетно-перфорационных машинах
Проведение конкретных социологических обследований большей частью основано на методе анкетирования. Массовость проводимых обследований, а также большой объем первичной информации об объекте обследования, содержащийся в анкете, настоятельно требуют совершенствовать методику машинной обработки анкет.
Как показывает опыт, материалы анкетных обследований можно успешно обрабатывать на 80-колонных счетно-перфорационных машинах (СПМ). Основные этапы обработки анкет на СПМ:
а) подготовка анкет к перфорации;
б) перенесение анкетной информации на перфокарты;
в) получение на основе перфокарт сводной информации, необходимой для анализа,
Все эти этапы обработки взаимосвязаны друг с другом, и наиболее правильное решение каждого из них сказывается на эффективности обработки анкет на СПМ в целом.
В данной статье освещены некоторые вопросы совершенствования методики обработки материалов анкетных обследований. При этом ставились задачи максимального сокращения затрат ручного труда при подготовке анкет к машинной обработке, получения на СПМ как можно более широкого круга показателей, используемых при анализе, выдачи результатов расчетов в удобной для анализа
155
табличной форме и в форме перфокарт, пригодной для дальнейшей обработки на электронных вычислительных машинах (ЭВМ).
Перенос зашифрованной информации с анкет на перфокарты осуществляется в порядке, определяемом макетом перфорации. В тех случаях, когда шифры всех реквизитов анкеты возможно разместить в одной 80-колонной перфокарте, порядок расположения реквизитов в макете перфорации соответствующих расположению в анкете. Предварительная подготовка анкет к перфорации ограничивается в основном шифровкой анкетных данных, которые необходимо перенести на перфокарты.
Но в практике часто применяют анкеты с таким объемом информации, шифры которой не могут разместиться на одной 80-колон-иой перфокарте. В этом случае приходится пользоваться двумя и более макетами. Чтобы получить сводную информацию (табуляграммы), реквизиты в этих макетах размещаются не в порядке их расположения в анкете, а выборочно. Такое распределение реквизитов по макетам значительно увеличивает трудоемкость ручной подготовки анкет к машинной обработке, так как возникает необходимость определенным образом отмечать, к какому макету относятся те или иные реквизиты. Применять трафареты в этих случаях неудобно, так как анкеты занимают несколько листов. Поскольку оператору при перфорации приходится перфорировать цифры не подряд, а выборочно, производительность его труда падает, а количество ошибок увеличивается.
Однако, как показывает опыт, без ручной разметки данных анкет по макетам и выборочной перфорации вручную можно обойтись, заменив эту работу машинной. Порядок перфорации массивов перфокарт по нескольким макетам следующий. 1
Подготовка анкеты к передаче на машиносчетную станцию такая же, как и при перфорации по одному макету, т.е. шифры реквизитов проставляются в анкете в порядке расположения вопросов в ней. Все реквизиты анкеты в виде шифров переносятся на перфокарты по необходимому количеству макетов в порядке расположения этих шифров в анкете. Назовем перфокарты, пробитые таким образом, и макеты, по которым они пробиваются, первичными.
156
Для примера возьмем анкету, содержащую 100 вопросов. Предположим, что в соответствии с табуляторами, которые необходимо получить, все реквизиты анкеты распределены по трем макетам. Назовем эти макеты итоговыми. Причем каждый из макетов содержит вопросы, которые расположены в анкете не подряд, а в разных местах.
Прежде чем автоматически изготовить массивы итоговых перфокарт, пробиваемых по трем макетам, необходимо отперфорировать массивы первичных перфокарт. Предположим, что все шифры анкеты по сумме знаков могут разместиться в двух 80-колонных перфокартах. Макеты первичных перфокарт составим таким образом, чтобы с 1 по 50 вопросы анкеты разместились в одном макете, а с 51 по 100 вопросы - в другом макете (макеты №1 и 2 первичных перфокарт). В обоих макетах первичных перфокарт надо предусмотреть перфорацию в одних и тех же колонках номера анкеты и однозначного номера макета. Оператор с одной анкеты переносит на перфокарту данные сначала по макету № 1, а затек по макету № 2, после чего переходит к перфорации данных следующей анкеты. После перфорации первичные перфокарты контролируются, а затем поступают на табуляцию. Первичные перфокарты обоих макетов (№1 в 2) должны быть рассортированы по номеру анкеты и составлять единый массив. Табулятор настраивается на совместную работу с итоговым перфоратором в соответствии с одним из трех макетов итоговых перфокарт. Шифры, которые нужно отперфорировать, автоматически отбираются во время табуляции первичных перфокарт макетов № 1 и 2, заносятся в определенные разряды счетчиков табуляторов, а затем с головок счетчика автоматически переносятся на итоговые перфокарты в порядке их расположения в макете итоговых перфокарт. Контрольный аппарат табулятора настраивается на контроль по номеру анкеты. Управлять отборочными устройствами табулятора можно или от насечки, пробитой на перфокартах одного из макетов, или от цифровой пробивки, соответствующей номеру первичного макета. Таким образом, за один пропуск перфокарт через табулятор получаем массив перфокарт, отперфорированный по одному из итоговых макетов. Для перфорации итоговых перфокарт по другому макету необходимо соответствующим образом настроить табулятор и итоговый перфоратор и еще раз протабулировать тот же первичный
157
массив перфокарт. Готовая перфорация контролируется путем сопоставления контрольных сумм, полученных по массивам первичных и итоговых перфокарт.
Итак, по массиву первичных перфокарт автоматически можно отперфорировать перфокарты, содержащие ответы на любое сочетание вопросов анкеты в пределах 80 колонок.
Подобным же образом можно автоматически макетировать, если данные анкетного обследования будут предварительно нанесены графическими отметками на специальные перфокарты, предназначенные для автоматической перфорации на считывающем перфораторе. В этом случае шифры реквизитов анкеты заносятся карандашом на специальные перфокарты в порядке расположения их в анкете. Так как едкость одной перфокарты с графическими отметками составляет 27 колонок, одной анкете будут соответствовать несколько перфокарт с графическими отметками. Следует предусмотреть, чтобы номер анкеты и порядковый номер перфокарты с графическими отметками в пределах анкеты проставлялись в одних и тех же колонках. После графической отметки перфокарт со всех анкет производится автоматическая перфорация на считывающем перфораторе, т.е. подготовка первичного массива перфокарт. В дальнейшем автоматическое макетирование выполняется в порядке, описанном выше.
Устраняя трудоемкую, ручную операцию разбивки вопросов каждой анкеты по различным макетам и уменьшая трудоемкость при ручной перфорации, способ автоматического макетирования позволяет в короткие сроки изготовить перфокарты по любому макету для получения большого количества табуляграмм с различными сочетаниями вопросов анкеты.
Среди работ в процессе подготовки материалов обследования к машинной обработке, выполняемых вручную, шифровка анкет – одна из наиболее трудоемких.
Однако опыт свидетельствует, что ручную шифровку некоторых вопросов анкеты можно заменить машинной. Это относится к шифровке интервалов различных показателей (например, возраст, стаж работы и др.). В анкетах проставляются непосредственные значения признаков, например возраст и стаж работы - в годах, зарплата - в рублях, которые и переносятся на перфокарты. Кроме того, в макете перфорации предусматриваются свободные колонки
158
для автоматической перфорации шифров интервалов признаков. Порядок автоматической перфорации следующий.
После перенесения информации на перфокарты полученный массив перфокарт сортируется по колонкам одного из признаков, подлежащих шифровке по интервалам. Отсортированные перфокарты разделяются прокладками на несколько групп в соответствии с значениями признаков, попадающих в определенный интервал. Пробивку шифров интервалов можно выполнить на репродукторе или позиционном итоговом перфораторе, коммутируя поочередно шифр интервала на импульсаторе с той колонкой, которая отведена для шифра интервала данного признака, и пропуская через репродуктор или итоговый перфоратор группы перфокарт с соответствующими данному интервалу значениями признака. Подобная автоматическая перфорация осуществляется с большой скоростью (техническая скорость 100-120 карт в мин.) и легко контролируется ("на прокол" или "на просвет").
Применение автоматической шифровки интервалов различных показателей имеет некоторые преимущества. Прежде всего, частично устраняется ручная шифровка и сопутствующие ей ошибки. Наличие в перфокарте прямого значения признака повышает точность расчетов различных статистических величин, в то же время создается возможность автоматически получать всевозможные группировки с помощью пробитых в перфокартах шифров интервалов. Кроме того, отказ от вынесения крайних значений интервалов и их шифров в анкету сокращает ее объем.
Совершенствование методики следующего этапа обработки данных анкетного обследования на СПМ – получение сводной аналитической информации – имеет целью получение как можно более широкого круга материалов, необходимых для анализа, сокращение до минимума доработки табуляграмм на клавишных вычислительных машинах, выдачу сводной информации в удобной для анализа форме - в форме таблиц.
Комплект СПМ, состоящий из табулятора Т-5МВ, электронной вычислительной приставки и позиционного итогового перфоратора, позволяет автоматически вычислить довольно обширную сводную информации.
С его помощью, кроме распределения обследованных по составу (абсолютному и в процентах), по первичным материалам анкет-
159
ных обследований можно вычислять средние значения различных показателей определенных групп обследованных, величину дисперсии, квадрат коэффициента вариации и ошибку среднего арифметического. Менее эффективно (в силу большой сложности алгоритма вычислений), но тем не менее возможно получение парных коэффициентов корреляции.
Данные обработки, характеризующие структуру обследованных, печатаются в табуляграмме как в абсолютном выражении, так и в процентах одной, двух, трех и более степеней итогов в соответствии с размерностью комбинационных таблиц, используемых при анализе. Для получения рядов распределения в абсолютном выражении отобранный массив перфокарт сортируют по колонкам группировочных признаков, а затем табулируют с автоконтролером по этим признакам. Подсчет количества карт в разрезе группировочных признаков соответствует численности обследованных по определенным группам.
Процентный состав обследованных вычисляется по одному из двух вариантов расчетов в зависимости от сложности таблицы и количества групп в старших группировочных признаках.
По
первому варианту целесообразно вычислять
несложные таблицы (с одной или двумя
степенями итогов). Для вычисления таблицы
с одной степенью итогов (например,
распределение всех обследованных по
возрастным группам) табулятор агрегатируют
с электронной вычислительной приставкой,
настроенной на выполнение деления,
контрольный аппарат табулятора
настраивают на контроль по группировочному
признаку (возрастной группе). На
промежуточных ходах табулятора
выполняется деление
![]() ,
,
где mi - счет карт по группировочному признаку (возрастной группе);
n – то же, по всему массиву (устанавливается на импульсатор промежуточных ходов, поэтому эту величину необходимо определить заранее);
pi – удельный вес данной группы в общей численности.
Сумма частных по массиву при правильной настройке и работе машин должна быть равна или близка в 100%.
При расчете процентного состава обследованных по двухстепенной таблице (например, распределение обследованных по полу, а в пределах пола - по возрасту) по предыдущему варианту расче
160
тов предварительно определяют счет карт по каждому шифру старшего признака (например, по полу), а затем вычисляют процентный состав точно так же, как и для таблицы с одной степенью итогов, с той лишь разницей, что на импульсаторе необходимо установить цифру счета карт по каждому шифру старшего группировочного признака перед пропуском соответствующей группы карт.
Для получения более сложных группировочных таблиц с одновременным вычислением процентного состава обследованных целесообразно пользоваться следующим вариантом вычислений. Табулятор агрегатируют с итоговым перфоратором, контрольный аппарат табулятора настраивают на контроль по всем группировочным признакам в соответствии с заданной таблицей, а счетчики табулятора на "счет карт" для получения всех необходимых степеней итогов. Одновременно необходимо предусмотреть передачу в счетчик значений группировочных признаков (для итоговой перфорации) с первой карты каждой группа, его гашение и накопление счетчиками табулятора контрольных сумм тех же группировочных признаков для счетного контроля итоговой перфорации.
При смене частных групп на итоговую перфокарту переносятся шифры группировочных признаков и счет карт по частной группе.
При смене промежуточных групп в соответствующих итоговых перфокартах дополнительно пробивается счет карт по промежуточным группам, при смене общих групп - счет карт по общим группам и т.д. Выверенные итоговые перфокарты табулируются. Табулятор работает совместно с ЭВП. Необходимо, чтобы итоговые перфокарты сохраняли порядок итоговой перфорации и закладывались в табулятор цифровой сеткой к оператору, срезанным углом влево. При таком расположении перфокарт общие итоги будут поступать в счетчики табулятора первыми. При коммутации необходимо пользоваться обратной нумерацией колонок нижних и верхних щеток. Табулятор настраивают на контроль по всем необходимым группировочным признакам. За один пропуск перфокарт через табулятор путем последовательного деления на ЭВП "счета карт" более младших признаков на "счет карт" по более старшим группировочным признакам можно получить процентный состав обследованных двух, трех, четырех и более степеней итога. В одной табуляграмме в зависимости от необходимости можно печатать или только процентный состав по всем группировочным признакам, или одновременно с про-
161
центным составом численность в абсолютном выражении по этим же группам. На СПМ легко можно получать средние значения различных признаков по определенным группам обследованных (например, средний возраст, средняя зарплата, средний стаж работы мужчин и женщин с различным семейным положением). Для вычисления средних величин табулятор агрегатируется с ЭВП, счетчики табулятора суммируют значения признаков (возраст, зарплата, стаж работы и т.д.) и счет карт в разрезе группировочных признаков в автоконтроле осуществляется только по частным группам. При смене частной группы накопленные в счетчиках суммы значений признаков последовательно передаются в ЭВП в качестве делимого. Делителем является "счет карт" (численность по данной группе). Настроив агрегат на выполнение совмещенных делений, за один пропуск перфокарт можно получить от одного до семи средних значений признаков на одного человека (частных от делений).
Помимо средних величин на СПМ можно выполнить расчет дисперсии, квадрата ошибки среднеарифметического, квадрата коэффициента вариации и квадратов парных коэффициентов корреляции. Поскольку вычисления среднеквадратического отклонения, ошибки среднего арифметического, коэффициента вариации, парных коэффициентов корреляции предполагают извлечение корня, что невозможно выполнить на СПМ за один пропуск перфокарт на табуляторе, составленная нами программа рассчитана на нахождение квадратов этих статистических величин.
По определению дисперсии
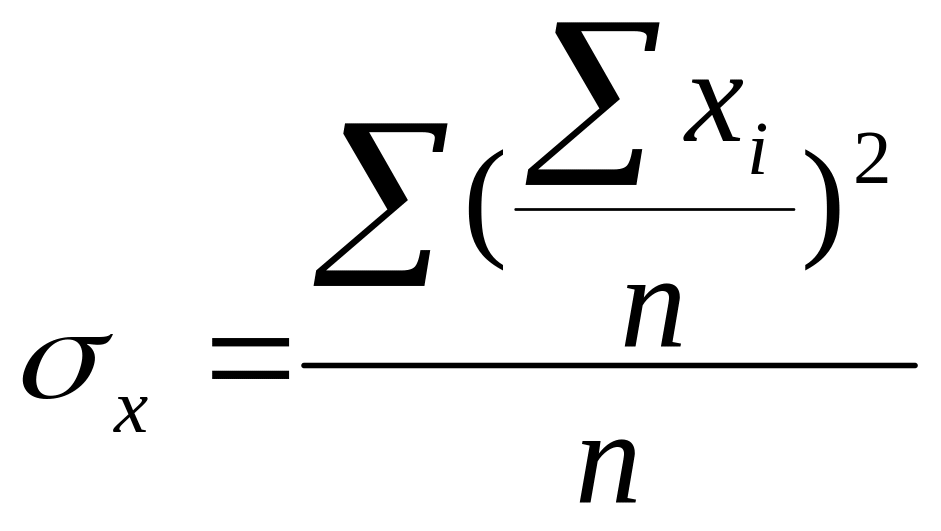 , (1)
, (1)
где i =1,2,..., n;
xi – значения величины x, соответствующее i -тому наблюдению;
n – количество наблюдений (счет карт в группе).
Непосредственно по формуле (1) вычисления на СПМ производить неудобно. Поэтому для расчета дисперсии была использована другая расчетная формула, а именно
![]() (2)
(2)
162
По этому алгоритму расчет дисперсии по одному признаку можно выполнить за один пропуск исходного массива перфокарт через табулятор.
Табулятор настраивают на автоконтроль группировочного признака по частным группам и агрегатируют с ЭВП. Исходный массив перфокарт сортируют по колонкам группировочного признака.
На
карточных ходах табулятора счетчики
накапливают
![]() ,
счет карт, а в сумматоре ЭВП происходит
накопление
,
счет карт, а в сумматоре ЭВП происходит
накопление
![]() .
При смене группировочного признака на
промежуточных ходах из сумматора ЭВП
передается в счетчик табулятора, затем
вычисляются величины
.
При смене группировочного признака на
промежуточных ходах из сумматора ЭВП
передается в счетчик табулятора, затем
вычисляются величины
![]() ,
,
![]() ,
n2
и вывод табулятора. Одновременно с
вычислением n2
выполняется вычитание [
–
],
а затем деление полученной разности на
n2
и выдача величины дисперсии на печать.
На печать в целях облегчения контроля
вычислений можно выводить также и
промежуточные результаты вычисления
дисперсии.
,
n2
и вывод табулятора. Одновременно с
вычислением n2
выполняется вычитание [
–
],
а затем деление полученной разности на
n2
и выдача величины дисперсии на печать.
На печать в целях облегчения контроля
вычислений можно выводить также и
промежуточные результаты вычисления
дисперсии.
Схема вычисления дисперсии составлена для трехразрядных значений xi и n. Для значений xi большей разрядности величина дисперсии может быть рассчитана с меньшей степенью точности, так как при расчете будут отброшены один или несколько младших разрядов значений xi.
По определению ошибки среднего арифметического
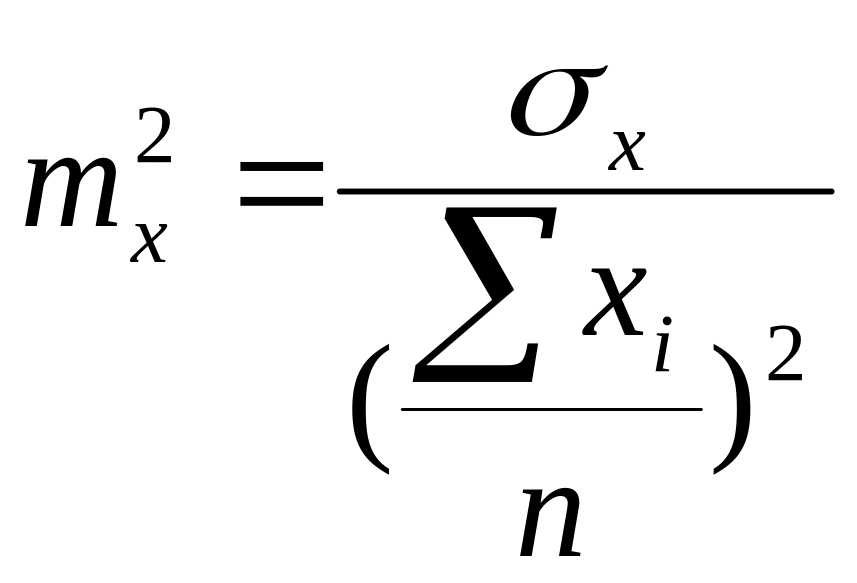 или
или
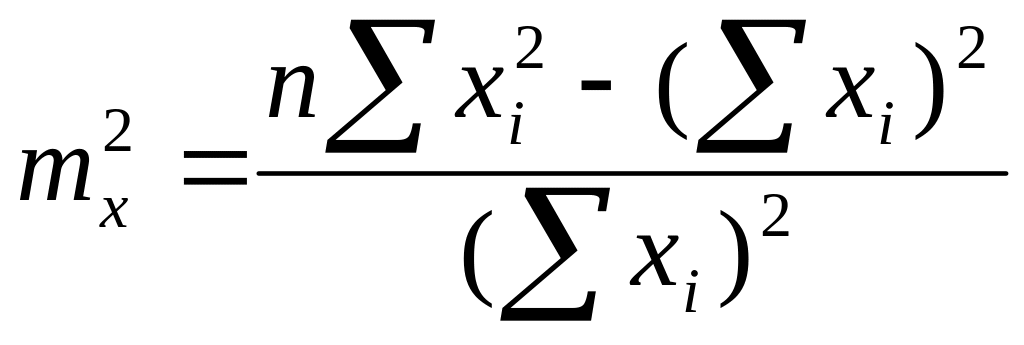
Таким
образом, расчет
![]() можно производить по схеме, аналогичной
вычислению дисперсии, с той лишь разницей,
что в данном случае не надо находить n2
и в качестве делителя вместо n2
используется
.
можно производить по схеме, аналогичной
вычислению дисперсии, с той лишь разницей,
что в данном случае не надо находить n2
и в качестве делителя вместо n2
используется
.
Следующая формула коэффициента детерминации удобна для вычисления на СПМ
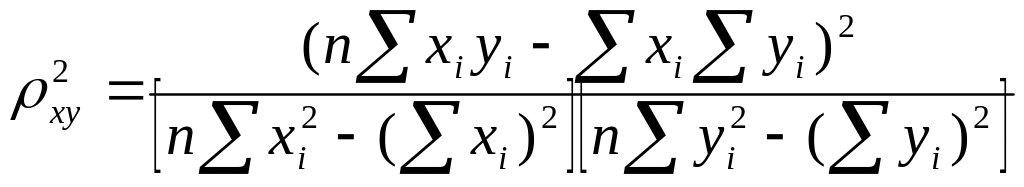
163
Ввиду
относительно большой сложности алгоритма,
значения
![]() за один прогон исходного массива
перфокарт на табуляторе получить
невозможно. Поэтому для вычисления
квадрата коэффициента корреляции на
первом этапе получаем два массива
итоговых перфокарт, содержащих
промежуточные результаты вычислений,
а именно:
за один прогон исходного массива
перфокарт на табуляторе получить
невозможно. Поэтому для вычисления
квадрата коэффициента корреляции на
первом этапе получаем два массива
итоговых перфокарт, содержащих
промежуточные результаты вычислений,
а именно:
![]() ,
,
![]() ,
,
![]() ;
;
![]() ,
,
![]() .
.
Итоговые перфокарты двух массивов объединяются путем сортировки по общему группировочному признаку, а затем табулируются при одновременной работе ЭВП. На основании массива итоговых перфокарт вычисляем величину .
На
основании этого же массива итоговых
перфокарт можно вычислить и дисперсию
квадрат ошибки среднего арифметического,
квадрат коэффициента вариации
![]() или
или
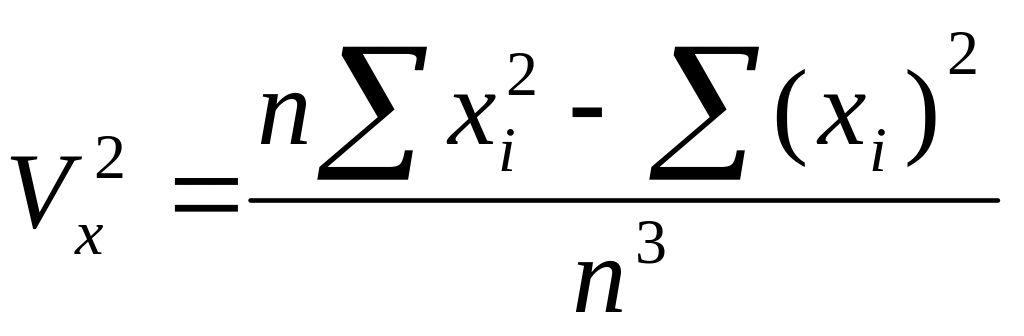
Обычно сводная информация, получаемая в результате обработки данных на СПМ, выдается в виде табуляграммы. Но из-за того что большая часть табуляграмм имеет вертикальное расположение итогов (в соответствии с вертикальным расположением шифров сказуемого в табуляграмме), а эта форма выдачи неудобна для анализа, приходится вручную переносить итоги из табуляграмм в таблицы. Опыт работы некоторых машиносчетных станций свидетельствует также о возможности получения части сводной информации непосредственно в форме табуляграмм-таблиц. На стандартном оборудовании это эффективно лишь в том случае, если младший группировочный признак имеет максимум 10 позиций. Процесс получения таких табуляграмм даже менее трудоемок, чем табуляграмм с вертикальным расположением итогов (за счет устранения сортировки по младшему группировочному признаку и меньшему количеству промежуточных ходов при табулировании).
При большем же числе позиций младшего группировочного признака приходится делить массив перфокарт на несколько массивов по определенным шифрам этого признака (число возможных позиций его
164
в каждом массиве не должно превышать десяти) и пропускать каждый массив на табуляторе отдельно. Затем табуляграммы разных массивов подклеиваются по горизонтали одна к другой в порядке возрастания шифров.
Модернизация табулятора Т-5М путем установления на нем дополнительного импульсатора, питающегося от плюсовой длины, обеспечивает получение табуляграмм – таблиц непосредственно по всему массиву перфокарт даже в том случае, если количество позиций в младшем группировочном признаке меньше.
Совершенствование методики обработки анкет с помощью счетно-перфорационных машин, отдельные вопросы которого рассмотрены выше, позволяет значительно уменьшить применение ручного труда, повысить качество получаемой сводной информации.
165
J.P. Voronov, N.P. Yershova
GENERAL PRINCIPLES OP SOCIOLOGICAL MEASUREMENT
The authors adhere to general principles of measurement representation theory developed by P. Suppes and J. Zines. It is shown here that the principles of measurements, proposed by Ajdukiewiez may be considered as a special case of this theory.
Some alternative generalizations of the measurement representation theory are given which may be useful for its application in sociology.
The paper sets forth a number of problems concerning practical application of this theory for processing the sociological data.
E.V. Ryvkina, M.I. Cheremisina
ON A PROGRAM OF CONSTRUCTING A DICTIONARY OF SOCIOLOGICAL TERMINOLOGY
This paper gives an extensive and well-reasoned design program for systematization and clarification of sociological terminology. The body of planned work is meant to be of two kinds: 1) methodological and terminological analyses of sociological theories and 2) the construction of a dictionary of sociological terms based on these analyses and made according to definite rules of inference. These rules result from logical analysis of definitions stated in sociological literature by direction or indirection.
166
V.I. Gerchikov
MUTUAL ORIENTATION OF SOCIOLOGICAL SCALES
Here is described a method of transition from nominal scales to graded ones through orienting then by a basic graded scale. An algorithm realizing this method is given here. The second part of the paper describes a program made in terms of ALGOL-60 and adjusted for electronic computers M-20. Using this program, up to 8 scales nay be simultaneously oriented by the basic scale.
B.G. Mirkin
A NEW APPROACH TO THE PROCESSING OF SOCIOLOGICAL INFORMATION
This paper presents a scheme of techniques for solving a broad class of problems pertaining to processing non-numerical data based on a common principle. The main tool is a measure of proximity among partitions in a set of surveyed objects. This measure is introduced by Beans of four natural axioms which uniquely determine it. Some methods of solving certain problems of data processing with the help of partitions proximity measure are given: quantitative estimation of proximity and significance of characters, classifications of objects, etc.
167
V.G. Ustiuzhaninov
INFORMATION MEASURES AND THEIR APPLICATION IN SOCIOLOGICAL ANALYSIS
The paper introduces difference measures among characters obtained on a nominal scale. It has been shown that this task is equivalent to measuring differences between two sets of objects on which the sane set of characters was determined.
For this, informational difference measures are used, calculated by conventional probability distributions.
On a number of examples the author demonstrates the sphere of application of these measures in sociological studies.
As a natural generalization of the binary difference measure, a difference measure for sets of objects whose number is more than two is introduced.
The application of difference measure for measuring time variations of the same object is considered.
The findings of this paper are used in the other paper by this author published in the present volume.
V.I. Gerchikov
OH THE PROPORTIONALIZATION OF THE SCALES OF SOCIOLOGICAL CHARACTERS
The paper sets forth the task of "proportionalization" of two scales with mutual reference which is opposite to the task of determining the extent of relative proportionality of scales. A method of measuring the proportionality of scales is described and illustrated by a number of examples, and hereupon the proportionality ratio is used to build such a model which can maximize the proportionality ratio.
168
V.Q. Ustiuzhaninov
THE INFORMATION THEORY AND THE PROBLEM OF CLASSIFICATION IN SOCIOLOGY
This paper deals with the classification of some initial set of objects on which a set of characters Is determined.
The solution of this problem is reduced to the solution of two special tastes.
1. Here is proposed a method of partitioning a set of characters into two nonoverlapping sets. The algorithm of partitioning is based on construction made according to definite rules of information binary measures graph.
2. A criterion of aggregating the elements of a set of objects into classes is introduced. With the help of this criterion the aggregation is made in such a manner as to minimize the loss of information.
An algorithm of multistep aggregation process is proposed. By means of this algorithm it is possible to establish levels of hierarchy among the classes obtained.
A case is considered when measures of difference among the groups of objects vary with time. For this ease an algorithm of distinguishing stable groups is proposed.
E.E. Goriachenko
THE PROCESSING OF GRADED SCALES AHD THE DISTINGUISHING OF TYPICAL GROUPS
The paper deals with a possible way of solving the problem of distinguishing typical groups in sociological studies. It is the processing of graded scales.
The account of methods is supplied with concrete examples in which the typical groups are distinguished on a set of social psychological characters.
The proposed scheme is general enough to be used in the processing of graded scales made in different ways.
169
V.N. Rassadin, V.M. Sokolov
OH A SCHEME OF CONSTRUCTING MATHEMATICAL MODELS OF SOCIAL OBJECTS
The construction of a social object model usually requires a selection of characters which Dust be considered in it.
The paper sets forth a method of formal logical selection of most essential characters. This method is included into the stage scheme of constructing mathematical-statistical models which forms the major part of the paper. An area of application of this scheme is also delimited.
J.P. Voronov, H.P. Moskalenko
ON MODELLING THE ADAPTATIOH TO WORK OF THE YOUTH
In this paper a model is proposed which permits to define the requirements of national economy to the system of polytechnical training of high school upper grade students.
It is thought as possible to establish the conformity between the habits of work obtained at high school and the demand of national economy for professionals of different kinds. Judging by the criterion of national economy, an optimal structure of obtained habits of work is the one which minimizes sum total of discrepancies between these habits and the demands of national economy.
170
O.V. Rozanov
A POSSIBLE APPROACH TO THE DESCRIPTION OF SOCIAL SYSTEM DYNAMICS
This paper suggests an original approach to the statistical estimate of the parameters in a dynamic process model which makes it possible to represent them as a functional matrix. It is shown that such model is a system on interdependent equations. A usual application of the dual method of Tale's least squares does not yield unbiased estimators of effect coefficients and does not allow for the change of effects structure in time. In order to avoid these shortcomings a principle of expanding time in space has been used. It is supposed that the models with parameters estimated by the above procedure may be applied to the predicting of social systems development.
L. Maslova, M. Sukhovsky
THE PROCESSING Of SOCIOLOGICAL DATA BY USING CARD-PUNCHED MACHINES
The authors who have great experience in processing sociological information describe some new methods in this field.
Most of these methods are in that the basic parameters of one- and twodimenslonal distributions are calculated at a data processing center. Due to this, the data of a great number of sociological researches need not be processed on computers.
171
CONTENTS
|
Page |
PART I. Primary Measurement |
|
J.P. Voronov, N.P. Yershova. General Principles of Sociological Measurement |
3 |
E.V. Ryvkina, M.I. Cheremisina. On a Program of Constructing a Dictionary of Sociological Terminology. |
16 |
V.I. Gerchikov. Mutual Orientation of Sociological Scales. |
37 |
B.G. Mirkin. A New Approach to the Processin Of Sociological Information. |
51 |
V.G. Ustiuzhaninov. Information Measures and Their Application in Sociological Analysis. |
62 |
V.I. Gerchikov. On the Proportionalization of the Scales of Sociological Characters. |
87 |
PART II. Typology |
|
V.G. Ustiuzhaninov. The Information Theoryand the Problem of Classification in Sociology. |
94 |
E.E. Goriachenko. The Processing of Graded Scales and the Distinguishing of Typical Groups. |
116 |
PART III. Model-building |
|
N.V. Rassadin, V.M. Sokolov. On a Scheme of Constructing Mathematical Models of Social Objects. |
127 |
J.P. Voronov, N.P. Moskalenko. On Modelling the Adaptation to Work of the Youth. |
133 |
G.T. Rosanov. A Possible Approach to the Description of Social System Dynamics. |
145 |
FART IV. Methods of Data Processing |
|
L. Maslova, M. Sukhovsky. The Processing of Sociological Data by Using Cardpunched Machines |
155 |
Abstracts |
166 |
1 Далее будет показано, что теория измерений по Айдукевичу может быт сведена к теории измерений по П.Суппесу и Дж.Зинесу, хотя и существует мнение, что это два разных подхода к одной и той же проблеме.
2 Обобщенное измерение можно назвать обозначением, однако использование термина "обобщенное измерение" более удобно, так как он указывает на связь данной категории с измерением.
Это не значит, что термин в текстах обязан иметь неизменный объём. Дело в том, что второе определение допускает интерпретацию в смысле первого, а первое не допускает интерпретации в смысле второго.
Напомним, что речь идёт лишь об общей схеме решения, где типы отношений можно задать произвольно. Интерпретация реальных отношений между объектами, несомненно, представляет очень серьезные трудности и потребует разработки своей методики.
Публикуемые в данном сборнике две статьи автора являются переработкой и развитием идей, изложенных в докладе на Всесоюзном совещании по количественным методам в социальных исследованиях, которое состоялось в Сухуми в апреле 1967 г. Основные идеи доклада и статей появились благодаря дружеской помощи научных сотрудников СО АН СССР Д. Демина, Е. Печерского, И. Истошина, Ф. Бородкина, Ю.Воронова.
В дальнейшем оборот «шкала признака S» будет заменяться сокращением «шкала S». ( Прим. Ред.)
1)
Это означает, что для любых двух объектов
![]() :
:
а) если они принадлежат одному классу и в разбиении , и в разбиении , то они находятся в одном классе и в разбиении ;
6) если они находятся в разных классах и в разбиении , и в разбиении , то они находятся в разных классах разбиения .
2) Сегментом разбиения называется множество, являющееся объединением некоторых его классов [ 3].
3) Можно было бы взять любое другое число; данное приводит к удобной формуле для .
*) Доказательство опускается. (Прим. ред.)
*) Данные нерепрезентативны. (Прим. ред.)
Работа выполнена под руководством Ю.П. Воронова; исходным материалом послужили данные выборочных обследований, проведенных сотрудниками сектора социологии Л.Г. Борисовой и Ю.Д. Карповым. Наряду с автором в работе принимала участие Н.П. Ершова.
3начимость определялась произвольно, по абсолютной величине коэффициента, поскольку оценки, приводимые в таблицах, рассчитаны на индивидуальное упорядочение.
Схема, излагаемая в данной статье, опробована на многих социологических задачах. Сопоставление ее с методами распознавания образов см. в сб. "Распознавание образов в социологии" под ред. Т.И. Заславской, Н.А. Загоруйко. Новосибирск, 1968
Исследование проводилось в 1967 году в районных комиссиях по трудоустройству молодежи Новосибирской области.
Задача синтеза системы управления рассматриваться здесь не будет.
К настоящему времени разработан "тройной метод наименьших квадратов". В результате проведенных экспериментов выяснилось, что заметных преимуществ перед "двойным методом наименьших квадратов" он не имеет.
В преобразованной форме каждая из взаимозависимых переменных выражена с помощью метода наименьших квадратов как функция от всех предопределенных переменных.
В работе по модернизации оборудования и отладке схем коммутации участвовал С.М. Данченко.
Термин "реквизит применяется при механизированной обработке информации, соответствующей вопросу анкеты.