

BiometriaKnuga
.pdf54 |
|
Біометрія |
|
У наведених вище способах обчислювання середнього арифметичного значення ряду розподілу застосовувалась величина, що являє собою різницю між будь-якою варіантою (х) і середнім значенням ряду розподілу (x). За середнє значення ряду розподілу приймалось умовне середнє (Аум). Це − о к р е м и й в и п а д о к в и з н а ч е н н я р і з н и ц і : а = х − Аум (або Аум − х). Отже, в узагальненому визначенні ця різниця буде
мати вигляд |
|
|
|
= A |
|
+ |
d |
|
|
|
||||
|
|
|
|
x |
|
ум |
, |
|
|
|||||
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
n |
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Середнє значення цих різниць, одержане як |
|
|
||||||||||||
|
|
|
−102 + 86 |
|
|
|
16 |
|
|
|
|
|||
|
x |
= 7 + |
|
|
= 7 + |
− |
|
|
|
= 7 |
− 0,07 |
= 6,93. |
||
|
|
|
|
|
|
|||||||||
|
|
|
236 |
|
|
|
|
236 |
|
|
|
|
||
зветься моментом розподілу варіаційного ряду. Причому, замість x можна взяти будь-яке довільне число.
Отже, момент розподілу варіаційного ряду є середні величини відхилень
варіант ряду від будь-якого числа. |
|
|
|
Для визначення моменту a = x − |
|
. розподілу можуть |
бути |
x |
|||
застосовані: значення |
|
середньої арифметичної |
ряду |
розподілу (x), усяке довільне число (А) або 0 (нуль). В залежності від того, яке значення обрано для порівняння, моменти розподілу розрізняють на:
1. Центральний момент розподілу (М) − коли для порівняння значень варіант застосовується значення середнього арифметичного цього ряду розподілу. Цей момент розподілу позначається літерою М і визначається за
формулою
∑pa, n

Розділ 3.4 ЕкОсологіябливості середніх величин в біометрії |
|
55 |
|
||
|
|
|
2. Умовний момент розподілу, коли для його визначення застосовується будь-яке число. Цей момент розподілу позначається літерою b і визначається за формулою
Mα = ∑p(x − x ). n
3. Початковий момент розподілу, коли для його визначення застосовується 0 (нуль). Цей момент позначається літерою m і визначається за формулою
b = |
∑ p(x −A) |
= |
∑ a |
|
. |
||
|
n |
|
n |
Як бачимо, початковий момент розподілу є одним з варіантів умовного моменту.
Для характеристики окремих особливостей рядів розподілу використовуються моменти розподілу, піднесені до різних степенів. Тоді відповідно вони звуться: момент першого порядку, момент другого порядку, момент третього порядку і т.д.
m = |
∑ p(x −0) |
= |
∑ x |
|
. |
||
|
n |
|
n |
56 |
|
Біометрія |
|
4.1.3. Варіювання даних спостережень
Середнє арифметичне є важливою статистичною характеристикою варіаційного ряду. Але вона не характеризує величини відхилення окремих значень, тобто окремих варіант від одержаного середнього їх значення. Тобто середня арифметична не дає уяву про величину варіювання даних (варіювати − лат. vario − змінюю, змінювати що-небудь у певних межах).
Не дають уяви про ступінь варіювання і інші середні показники, про які йшла мова вище.
Однак без урахування ступеню варіювання неможливо дати повну характеристику досліджуваної ознаки.
Наприклад, для того, щоб охарактеризувати ріст людини, недостатньо посилатись тільки на показник середнього значення, а необхідно вказати, що ріст окремих людей відхиляється від цього середнього на певну величину. Для того, щоб охарактеризувати висоту дерева в деревостані, недостатньо визначити лише її середній показник, а необхідно відмітити, що окремі дерева можуть мати висоту іншу за середній показник.
56 |
|
Біометрія |
|
4.1.4. Ліміти, розмах і коефіцієнт варіації
Одним із показників, який характеризує ступінь відхилення окремих варіант варіаційного ряду від їх середнього значення, є ліміти розподілу (ліміт − лат. limes (limites) − межа, крайній ступінь обмеження). Ліміти − це мінімальна і максимальна варіанта сукупності (варіаційного ряду). Вони позначають фактичні межі відхилення даної ознаки від її се-реднього значення в даній сукупності. Ліміт позначається символом lim.
Ступінь цього відхилення визначається як різниця між цими лімітами, тобто між максимальною і мінімальною варіантами. Цей показник зветься розмах варіації даної сукупності.
Відхилення членів сукупності (N або n) має місце в порівнянні з будьяким одним із членів. Тобто один з членів не бере участі у варіюванні. Тому при визначенні відповідних показників варіювання в розрахунках також враховується число ступенів вільності (n − 1).
Відхилення значення кожної конкретної варіанти від середнього для варіаційного ряду зветься варіюванням. По відношенню до всього

Розділ 3.4 ЕкОсологіябливості середніх величин в біометрії |
|
57 |
|
||
|
|
|
варіаційного ряду найбільш об’єктивною характеристикою міри варіювання варіант, що входять до цього ряду, є середній квадрат відхилень, який визначається як сума квадратів відхилень кожної варіанти, поділена на кількість варіант. Для генеральної сукупності він позначається символом σ2, а для виборки − s2. Отже,
|
|
|
∑(x − |
|
)2 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
σ |
2 |
= |
x |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
|
|
; |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
N |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||
|
|
|
(x |
− |
|
)2 + (x |
|
− |
|
)2 + (x |
|
− |
|
)2 |
+ ... + (x |
|
− |
|
)2 |
|
|
||
s2 |
|
x |
2 |
x |
3 |
x |
n |
x |
|
||||||||||||||
= |
1 |
|
|
|
|
|
|
|
|
|
|
|
|
|
. |
(4.1) |
|||||||
|
|
|
|
|
|
|
|
|
n −1 |
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
Приклад визначення середнього квадратичного відхилення наведений в табл. 3.
Нагадаємо, що величини σ2 і s2 звуться дисперсією (відповідно до генеральної і вибіркової сукупності).
Таблиця 3. Приклад визначення середнього квадратичного відхилення
Класи |
Середнє |
Частота |
хр |
Відхилення |
Квадратичне |
(інтервал), |
значення |
прояву (р) |
|
(х–x) |
відхилення |
см |
класу (х) |
|
|
|
(х–x)2 |
2 − 5,9 |
3,9 |
2 |
7,8 |
− 7,2 |
51,8 |
6,0 −9,9 |
7,9 |
8 |
63,2 |
− 3,2 |
10,2 |
10,0 − 13,9 |
11,9 |
14 |
166,6 |
− 0,8 |
0,64 |
14,0 − 17,9 |
15,9 |
4 |
63,6 |
+ 4,8 |
23,0 |
18,0 − 21,9 |
19,9 |
1 |
19,9 |
+ 8,8 |
77,4 |
|
11,1 |
Σ р = 29 |
Σ хр = 321,1 |
|
Σ z2 = 363,0 |
За значеннями σ2 і s2 знаходять показник середнього квадратичного відхилення, який дорівнює
σ = 
 σ2 і s =
σ2 і s = 
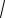 s2 .
s2 .
Середнє квадратичне відхилення зветься ще стандартним відхиленням або стандартною помилкою. Нагадаємо, що вона величина іменована, тобто виражається в тих самих одиницях, що значення ознаки:
58 |
|
|
|
|
|
|
Біометрія |
|
|
|
|
|
|
||
|
∑p(x − |
|
)2 |
|
∑xp |
||
2 |
x |
|
|||||
|
σ = |
∑p−1 |
= 3,6см; M = |
∑p =11,07см. |
|||
Для того, щоб середнє квадратичне відхилення можна було використати для порівняння варіабельності ознак незалежно від того, якими одиницями вони позначені (мм, г, % та інші) використовуємо відносний показник, який має назву коефіцієнт варіації (С) або (Сv).
Коефіцієнт варіації − це відношення середнього квадратичного відхилення до середньої арифметичної, визначене у %, тобто
|
σ |
|
або |
||||||
C = 100 |
% |
C =100 |
s |
. |
|||||
|
|
||||||||
|
|
x |
|
|
|
|
x |
|
|

58 |
|
Біометрія |
|
||
|
|
4.1.5. Помилка середньої арифметичної
Середнє значення, визначене з урахуванням всіх варіант генеральної сукупності, помилки не має. Однак, коли середнє вираховується лише за певною кількістю вибіркових варіант, то можливе відповідне відхилення одержаного значення середнього для даної виборки від середнього для генеральної сукупності. Це зветься помилкою репрезентативності.
Вона визначається за формулою
|
|
= |
x1 + x2 + x3 +...+ x10000 |
. |
(4.2) |
X |
|||||
10000 |
|
|
|||
Приклад:
x = 4,5± 0,57.

Розділ 3.4 ЕкОсологіябливості середніх величин в біометрії |
59 |
|
Із збільшенням кількості варіант (n), які залучені у частковій виборці для визначення середнього, помилки зменшуються. Наявність помилки середнього значення вносить певну долю умовності щодо безапеляційного застосування її як об’єктивної характеристики. Характер помилки означає, що справжнє (об’єктивно існуюче) значення середньої знаходиться в діапазоні між додатнім і від’ємним значеннями середнього. Ці значення звуться довірчими межами середнього значення.
Довірчі межі одержаного середнього значення знаходяться від M + m або M − m, тобто M + m > M > M − m. Іноді довірчі межі стають орієнтирами не тільки для попереднього аналізу явища, але й в практичній діяльності.
|
|
|
|
Наприклад. За даними обрахувань бригада рибалок за |
||||||||||||||||
|
|
|
|
черговий вихід на рибалку може добути 3,5 ± 0,8 т риби. За |
||||||||||||||||
mx = |
σцими |
xданими2 = (4,5)бригадир2 = 20,25;мусить |
забезпечити |
умови |
||||||||||||||||
|
|
зберігання s3,5 |
+ |
0,8 = |
4,3 |
т |
риби |
(холодильники, цехи |
||||||||||||
|
|
|
N m |
|
= |
|
|
|
|
. |
|
|
|
|
|
|
|
|
||
|
|
|
|
|
36 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1 |
180 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
2 |
|
|
|
|
|
x |
|
|
), |
|
але |
|
контракти |
на |
збут |
риби він |
має |
право |
||
|
|
|
переробки |
|
|
|||||||||||||||
|
= |
x |
= |
|
|
= |
|
n |
|
−1 |
|
|
|
|
|
|
|
|
||
|
|
|
|
|
− |
4,5; |
|
= |
30,327 ;5 |
6 |
4 |
5 |
Σ |
|
|
|||||
mЗначення |
варіант20(х),254 |
|
|
|
||||||||||||||||
x |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
mx |
= |
0,32 =х =0,3657. |
|
|
|
|
|
7 |
|
82 |
|
|
|
|
|
|
|
|
|
|
|
|
2 |
|
|
|
|
|
|
|
заключити8 |
|
лише на 3,5 |
− 0,8 = 2,7 т, інакше він ризикує |
|||||||||||||
Квадрати (х ) |
|
|
|
4 16 9 49 25 36 16 25 |
Σ х = 180 |
|
||||||||||||||
|
|
|
|
можливими |
штрафними санкціями. |
|
|
|
||||||||||||
Значення помилки репрезентативності можна пояснити на такому прикладі.
Приклад. Необхідно визначити середню довжину колоса на дослідній ділянці пшениці, на якій є 10 тис. рослин. Ці 10 тисяч колосків в даному випадку складають генеральну сукупність їх на даній ділянці (N).
Для того, щоб визначити їх середню величину, необхідно заміряти довжину кожного колоска, знайти суму довжин і поділити цю суму на 10 тис.:
M= ∑xp =11,07см.
∑p

60 |
|
Біометрія |
|
||
|
|
Але в проведенні такої величезної роботи немає необхідності. Їх можна спростити, якщо застосувати метод визначення середньої довжини колоска не шляхом вимірювання довжини кожного колоска, що входять в генеральну сукупність, а лише вимірюючи її у частини колосків. Ця частина колосків, що відбирається для цього формує вибіркову або часткову сукупність (n). Припустимо, що ця часткова сукупність складається з 50 колосків. У кожного колоска замірюється довжина і їх сума ділиться на 50:
x = x1 + x2 + x3 +...+ x50 . 50
Це буде середня довжина колосків, які були відібрані в часткову сукупність. Зрозуміло, що x ніколи не буде дорівнювати X, оскільки тут для замірів взято лише частину колосків (рис. 4). x ≠ x2 ≠ x3 ≠ ... ≠ xa . При цьому, якщо взяти інші 50 колосків, то їх середня довжина (x2) буде на якусь міру
відрізнятись від результатів, одержаних по першій групі; якщо взяти ще одну виборку з 50 колосків, то буде одержано третій результат (x3) і так далі. Тобто,
x ≠ X; x2 ≠ X ; x3 ≠ X
Але одночасно і так далі.
Звідси
X − x1 ≠ X − x2 ≠ X − x3,
тобто кожне значення генеральної сукупності і будь-якого середнього значення вибіркової сукупності буде різним. Значення для вибіркових сукупностей можуть бути більшими або меншими у порівнянні із значеннями для генеральної сукупності. Але для однієї вибіркової сукупності ця різниця буде меншою, для другої − більшою. Конкретна величина різниці по кожній вибірковій сукупності залежить від того, наскільки представництво відібраних колосків відображає структуру даної генеральної сукупності за

Розділ 3.4 ЕкОсологіябливості середніх величин в біометрії |
61 |
|
обраною ознакою, тобто в даному прикладі за довжиною колосків.
Ще однією, майже апріорною особливістю є те, що чим більша кількість варіант включена у вибіркову сукупність (скажімо не 50, а 100 або 150 колосків), тим в більшій мірі середнє значення вибіркової сукупності буде наближатись до середнього значення генеральної сукупності. В математиці ця особливість відома як "закон великих чисел", сформульований Бернулі, Пуассоном, Чебишевим, Марковим, Ляпуновим. Згідно з цим законом
Ознаки варіант генеральної сукупності
|
|
= |
x1 + x2 + ... + x50 |
|
|
= |
x1 + x2 + ... + x10000 |
|
|
|
= |
x1 + x2 + ... + x50 |
||
|
|
X |
|
|||||||||||
x |
x |
2 |
||||||||||||
|
|
|
|
|||||||||||
1 |
|
50 |
10000 |
|
|
50 |
||||||||
|
|
|
|
|
|
|
||||||||
|
Рис. 4. Середнє значення ознаки по генеральній (X) і кожній вибірковій сукупності |
|||||||||||||
|
(x1, x2 і т.д.) |
|
|
|
|
|
|
|
|
|
|
|||
помилка середнього значення вибіркової сукупності (± |
|
m) зменшується при |
||||||||||||
збільшенні числа спостережень (n). Тобто, вибіркова середня (x) буде скільки
завгодно наближатись до генеральної середньої |
(M), |
якщо число |
спостережень (n) необмежено збільшується. |
|
|
У прикладі, який наведено на рис. 4, взято |
з однієї |
генеральної |
сукупності лише дві вибіркові сукупності і показано, що їх середні значення (x1 і x2) є різними. Можна провести такий дослід: взяти з цієї самої генеральної сукупності досить велику кількість вибіркових сукупностей і для одержання їх середніх значень провести статистичний аналіз. Одержані результати засвідчать наявність певних статистичних достовірних