

Коэффициенты наследуемости и повторяемости признаков
В селекционной работе большое значение имеют показатели наследуемости и повторяемости признаков.
Коэффициент наследуемости (h2) - это величина, которая показывает, в какой степени общая изменчивость признака в популяции обусловлена его генетическим разнообразием. Коэффициент наследуемости признаков выражается обычно в долях единицы от 0 до 1 или в процентах. Чем выше коэффициент наследуемости, тем в большей степени значение признака обусловлено наследственностью.
Способы определения коэффициента наследуемости основаны на сходстве между родственными животными. При этом, чем больше степень сходства между родственниками, тем выше наследуемость признаков. Цифровое значение коэффициента наследуемости получают методами корреляционного или дисперсионного анализа. В зависимости от того, между какими родственниками изучается сходство, используют различные формулы для определения коэффициента наследуемости. В случае, когда для установления величины коэффициента наследуемости вычисляют корреляцию между продуктивностью матерей и дочерей, отцов и сыновей, полных братьев и сестер (сибсов) формула имеет вид удвоенного коэффициента корреляции:
h2 = 2r. Эта формула используется, когда различия в изменчивости признаков у родителей и потомков незначительны.
При разной интенсивности отбора среди родителей и потомков показатели разнообразия признаков резко различаются. В таких случаях целесообразно пользоваться формулой: h2 = 2R м/д.
Если вычисление коэффициента наследуемости основано на определении сходства между полубратьями и полусестрами (полусибсами), то формула имеет вид: h2 = 4r.
Коэффициент наследуемости можно вычислить и с помощью дисперсионного анализа по формуле:
Сх где h2 - коэффициент наследуемости,
h2 = ──── ; Сх - доля наследственной изменчивости,
Cy Су - общая изменчивость признака.
Техника расчета коэффициента наследуемости методом корреляционного анализа рассмотрена в предыдущей главе. Ниже приведена схема определения коэффициента наследуемости методом дисперсионного анализа. Для примера определим коэффициент наследуемости яйценоскости кур по материалам учета этого показателя у матерей (х) и их дочерей (у).
х - у х - у х - у х - у
298 - 300 306 - 285 254 - 230 263 - 245
263 - 302 350 - 328 237 - 255 294 - 254
303 - 293 321 - 279 260 - 290 278 - 273
268 - 320 284 - 280 271 - 264 321 - 340
242 - 278 233 - 241 278 - 235 277 - 298
305 - 308 346 - 304 322 - 318 328 - 344
261 - 268 304 - 368 325 - 308 305 - 343
278 - 284 230 - 238 315 - 301 280 - 350
266 - 281 308 - 325 292 - 278 285 - 304
255 - 278 276 - 346 295 - 299 256 - 281
Полученные цифровые материалы распределим в корреляционную решетку (табл.16). Для построения корреляционной решетки находим максимальное и минимальное значения признака и лимит, определяем число классов и классовый интервал:
max = 350; min = 230; lim = 350 - 230 = 120;
Число классов - 6; i = lim : число кл.= 120 : 6 = 20 (шт).
16. Корреляционная решетка для определения коэффициента наследуемости методом дисперсионного анализа
|
М Д |
230- 249 |
250- 269 |
270- 299 |
300- 309 |
310- 329 |
330-350 |
ру |
ау |
ру ау |
ру а2 |
|
230- 249 |
2 |
2 |
1 |
|
|
|
5 |
-3 |
-15 |
45 |
|
250- 269 |
1 |
1 |
2 |
2 |
|
|
6 |
-2 |
-12 |
24 |
|
270- 289 |
1 |
2 |
3 |
2 |
1 |
1 |
10 |
-1 |
-10 |
10 |
|
290- 309 |
|
2 |
2 |
4 |
2 |
1 |
11 |
0 |
0 |
0 |
|
310- 329 |
|
1 |
|
1 |
1 |
1 |
4 |
1 |
4 |
4 |
|
330- 350 |
|
|
1 |
1 |
1 |
1 |
4 |
2 |
8 |
16 |
|
рх |
4 |
8 |
9 |
10 |
5 |
4 |
|
|
ру ау -25 |
ру а2 99 |
|
∑рi аy |
-9 |
-9 |
-8 |
-4 |
2 |
2 |
|
|
|
|
|
(∑рi а)2 |
81 |
81 |
64 |
16 |
4 |
4 |
|
|
|
|
|
(∑рi а)2 ───── рх |
20,8 |
10,1 |
7,1 |
1,6 |
0,8 |
1,0 |
(∑рi а)2 ∑ ───── = 40,8 рх | |||
Число классов, классовый промежуток и границы классов для матерей и дочерей берем одинаковые. Дальше делаем разноску вариантов по клеткам корреляционной решетки, учитывая одновременно значение яйценоскости у матерей (х) и дочерей (у).
Распределив значения признаков в корреляционной решетке, определяем условно средний класс дочерей, проставляем условные отклонения (аy) от этого класса, находим величины рy аy и рy аy2 и их суммы. По вертикальной графе вычисляем ∑pi ay , умножая частоты каждой клетки вертикальных граф (pi ) на условные отклонения (аy). После этого полученные величины ∑pi аy по каждой графе возводим в квадрат и получаем строчку значений ( ∑pi аy )2. Эти значения делим по вертикальным графам на соответствующие значения px , полученные величины суммируем и получаем:
( pi ay )
∑ ──── = 40,9
px
Теперь у нас есть все исходные данные для определения Сx и Сy. Эти величины находим по формулам:
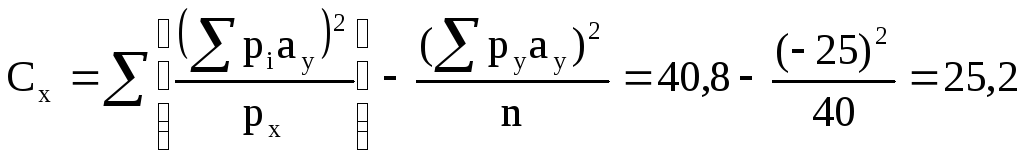
(∑py ay)2
Cy = ∑pi ay2 - ─────── = 99 - 15,6 = 83,4.
n
Коэффициент наследуемости - это доля наследственной изменчивости в общей изменчивости признака. Определяют коэффициент наследуемости по формуле:
Cx 25,2
h2 = ──── = ───── = 0,30.
Cy 83,4
Коэффициент наследуемости свидетельствует о степени влияния родителей на продуктивные качества их потомства. Это позволяет использовать его для предсказания будущей продуктивности потомства (эффекта отбора). Однако следует учитывать, что прогноз будет верным только в случае сохранения в хозяйстве одинаковых условий кормления и содержания.
Для установления эффекта отбора вначале находят селекционный дифференциал (Sd) - отклонение величины показателя признака у отобранной (селекционной) группы от среднего значения его в стаде. Sd = Mселек.гр. - Мстада.
Далее определяют эффект селекции (SE): SE = 0,5 х Sd х h2, где 0,5 – коэффициент, указывающий на то, что матери передают своим дочерям половину наследственной информации, Sd - селекционный дифференциал и h2 - коэффициент наследуемости.
Среднюю продуктивность дочерей (Мд) определяют по формуле:
Мд = Мм + SE
Таким образом, если средний удой коров стада равен 3000, а отобранной группы (племенного ядра) - 4500 кг, при коэффициенте наследуемости h2 = 0,3, то селекционный дифференциал будет:
Sd = Mселек. - Мстада = 4500 - 3000 = 1500 (кг)
Эффект селекции за одно поколение составит:
SE = 0,5 х Sd х h2 = 0,5 х 1500 х 0,3 = 225 (кг)
Продуктивность дочерей находим по формуле:
Мд = Мм + SE = 3000 + 225 = 3225 (кг)
Однако такой продуктивности дочери достигнут при полной замене стада через поколение или через 5 лет. Чтобы определить ежегодную прибавку удоя, в стаде нужно полученное значение селекционного эффекта разделить на интервал между поколениями или для крупного рогатого скота на 5 лет. SE за год = 225 : 5 = 45 (кг).
Кроме определения эффекта селекции, коэффициент наследуемости учитывают при составлении селекционных индексов, которые и используют в селекционной работе.
Коэффициент повторяемости (rw) - это величина, показывающая, в какой степени организм способен удерживать хозяйственно-полезные признаки в постоянных условиях и сохранять свое преимущество (ранг) по сравнению с другими животными при изменении условий среды. Коэффициент повторяемости определяется путем вычисления коэффициента корреляции между последовательными измерениями признака ( например, между удоем за первую и последующие лактации, между плодовитостью свиноматок за первый и другие опоросы и т.д.).
Вычисление коэффициента корреляции с построением корреляционной решетки нами уже рассмотрено в предыдущей главе. Здесь мы продемонстрируем определение этого показателя ранговым методом по Спирмену.
Формула для определения рангового коэффициента корреляции имеет следующий вид:
6∑D2 где r - ранговый коэффициент корреляции
rw =1 - ────────; D - разность рангов,
n (n2 - 1) n - объем выборки
Для примера вычислим коэффициент повторяемости между удоем коров за первую и третью лактации (табл.17). Для расчетов нам необходимо расставить ранги, которые определяют место конкретного животного среди других. Далее находим разность рангов, их квадраты и сумму квадратов (D2 ).
Как показали расчеты между удоем за первую и третью лактации установлена достаточно высокая повторяемость (rw = 0,7). Это дает возможность прогнозировать будущую молочную продуктивность коров по величине их удоя за первую лактацию. Коэффициент повторяемости используют в селекционной работе не только для прогнозирования будущей продуктивности животных, но и для ускоренной оценки производителей и маток по качеству потомства.