

Питання для самоконтролю
1. Дайте визначення поняття «апроксимація експериментальних даних».
2. Сформулюйте задачу функціональної апроксимації.
3. Опишіть технологію підбору емпіричної формули, для якої наближення до заданої функції виявляється найкращим.
4. Обґрунтуйте необхідність прогнозування розвитку медико-біологічних процесів.
5. Опишіть комп’ютерну технологію апроксимації даних функціональними залежностями.
6. Які вбудовані функції табличного процесора MS Excel використовуються для апроксимації експериментальних даних?
7. Яке призначення лінії тренда?
8. Охарактеризуйте зміну похибки прогнозу при збільшенні кількості даних спостереження.
9. Охарактеризуйте зміну похибки прогнозу при збільшенні часового проміжку прогнозу.
10. Які типи діаграм можна побудувати в середовищі електронних таблиць MS Excel?
11. Опишіть технологію побудови діаграми.
12. Опишіть технологію редагування діаграми.
13. Як оцінити степінь наближення апроксимації експериментальних даних вибраною функцією?
14. Що показує величина достовірності апроксимації?
15. Яким чином здійснюється вибір типу апроксимуючої функції з деякого числа придатних варіантів?
Завдання для самостійного виконання
Завдання 1-С. .У відповідності з завданням 1 апроксимуйте дані таблиці 25 за допомогою експоненціальної функції. Визначте на основі отриманої аналітичної залежності кількість захворілих на 11, 15, 15 день від початку епідемії. Порівняйте з результатами, отриманими при виконанні завдання 1.
Завдання2-С. Виконайте завдання 1 при скороченому варіанті вхідних даних (таблиця даних розвитку епідемії містить інформацію про 7 днів розвитку епідемії). Порівняйте отримані результати з результатами розрахунків за повною таблицею 25.
Завдання3-С. Побудуйте графік росту числа захворілих на грип населених пунктів Володарки та Ставища протягом 5 тижнів за даними завдання 4.
Завдання4-С. Побудуйте графік росту числа захворілих на грип населених пунктів Володарки та Ставища протягом 5 тижнів за даними завдання 4.

Схема 3. Редагування діаграм в табличному процесорі
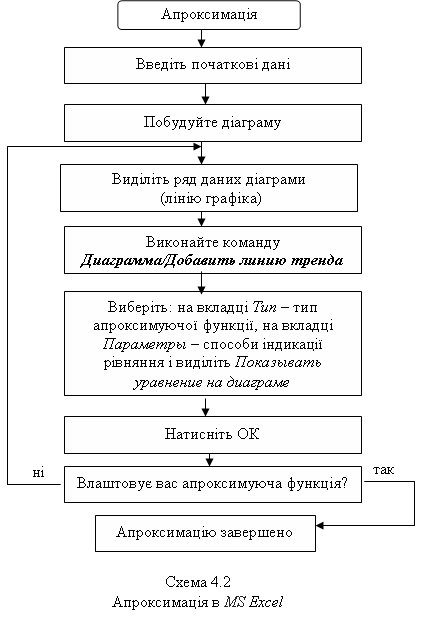
Схема 4. Апроксимація даних в середовищі табличного процесора
Представлення систем підтримки прийняття рішень. Експертні системи. Побудова бази знань та структурування. Сучасна архітектура системи прийняття рішень.
Конкретні цілі заняття:інтерпретуватиосновні моделі представлення медичних знань;аналізуватипринципи побудови і функціонування систем підтримки прийняття рішень;демонструвативміння використовувати напівактивні експертні системи для підтримки прийняття рішень.
Основні поняття теми
Система знань, експертна система (ЕС), база знань, штучний інтелект, система штучного інтелекту, інтелектуальні інформаційні технології, інженер зі знань, експерт, діагностика, класифікація, прогнозування, планування, керування, типи ЕС (інтерпретації даних, діагностики, моніторингу, прогнозування, навчання, планування, проектування, автономні, гібридні, формальні моделі зображення знань
Короткі теоретичні відомості
Принципово нові досягнення в технології обробки інформації пов’язані зі створенням особливих людино-машинних систем, призначених для накопичення й обробки у комп’ютері знань, необхідних для вирішення складних практичних задач. Подібні системи одержали назву систем знань (knowledgebased system). Серед систем знань найбільш бурхливо останнім часом розвивалися експертні системи (ЕС). У медицині ЕС широко застосовуються для підтримки прийняття рішень при розв’язанні різноманітних проблем діагностики, прогнозування, лікування, управління, навчання тощо.
Продемонструємо особливості архітектури, характеристик та принципів роботи з клінічними експертними системами на прикладі програми «Експертна система» v2.0 (http://bukhnin.chat.ru/).
«Експертна система» є напівактивною експертною системою, що використовує байєсовскую систему логічного висновку. Програма (див. рис. 59) призначена для проведення консультації з користувачем у деякій прикладній області (відповідно до завантаженої бази знань) з метою визначення ймовірностей можливих висновків, використовуючи для цього оцінку правдоподібності деяких передумов (свідчень), одержаних від користувача.
Як приклад розглянемо задачу визначення ймовірностей наявності різних захворювань у пацієнта. Програма в цьому випадку виступає в ролі лікаря (експерта), що задає пацієнтові систему відповідних питань та на основі отриманих відомостей ставить діагноз. Причому під час діалогу користувача і програми запитується оцінка істинності ключового факту і на основі відповіді коректується ймовірність висновку та перехід до наступного актуального факту. У такий спосіб досягається швидке одержання результату при мінімальній кількості питань.
Використання байєсовської системи логічного висновку означає, що оброблювана експертною системою інформація не є абсолютно точною, а носить ймовірнісний характер. Користувач не обов’язково повинен бути впевнений в абсолютній істинності або хибності відповіді, а може відповідати на запитання системи з певним ступенем впевненості. У свою чергу система видає результати консультації у вигляді ймовірностей настання висновків.
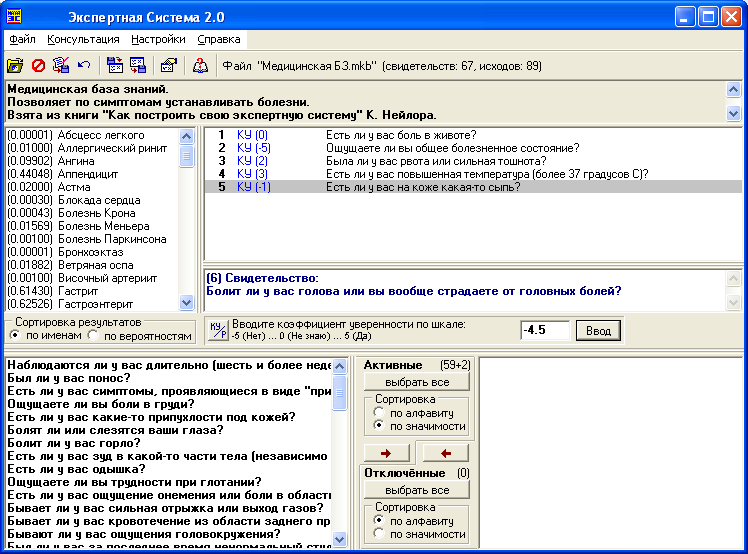
Рис. 59. Інтерфейс програми Експертна система
Для початку роботи з програмою необхідно завантажити базу знань, що містить інформацію з тієї прикладної області, у якій Ви бажаєте одержати консультацію (детальний опис роботи з програмою подано в схемі 5). Після початку консультації в правій частині вікна (область запитів) з’являється перший запит системи, ступінь істинності якого система бажає дізнатися. У даній версії експертної системи можливі два способи відповіді користувача:
задання за деякою шкалою коефіцієнту впевненості(КВ) (наприклад, від ‑5, що означає «точно ні», до +5 – «точно так»).
введення ймовірності істинності відповіді (число від нуля до одиниці).
В обох випадках користувач має можливість вибирати будь-які проміжні значення. Ці два варіанти відповідей не тотожні, оскільки значення коефіцієнта впевненості вибирається практично інтуїтивно, в той час як імовірність може бути отримана з дослідів, математичних обрахунків тощо. Зазначимо ще одну важливу відмінність між двома способами відповіді. У випадку вибору коефіцієнта впевненості, користувач може відповісти «не знаю», ввівши число, що відповідає середині шкали (наприклад, нуль, якщо шкала від -5 до +5). Така відповідь не впливає на результат консультації. При виборі введення ймовірностей істинності відповідей такої можливості не має.
Введення ймовірності істинності відповіді виправдане у випадку, коли користувач точно знає її значення. Його можна отримати з таблиць, за результатами статистичних досліджень, математичних обчислень.
На схемі 6 реалізована дидактична імітаційна модель відповіді користувача на запит системи.
Введена користувачем відповідь обробляється, розташовується в список, вище області запиту та підсвічується сірими кольором. При потребі користувач може виділити будь-які відповіді в цьому списку й скасувати її обробку.
Одержуючи від користувача відповіді, система коректує ймовірності можливих діагнозів, що відображається в лівій частині верхньої половини вікна.
По завершенні (а також у процесі) консультації передбачено можливість збереження її ходу у текстовому файлі. До протоколу буде записаний поточний час, опис бази знань, список оброблених питань та відповідей і результати консультації в тому порядку, у якому вони представлені у вікні програми.

Схема 5. Модель опису роботи з програмою
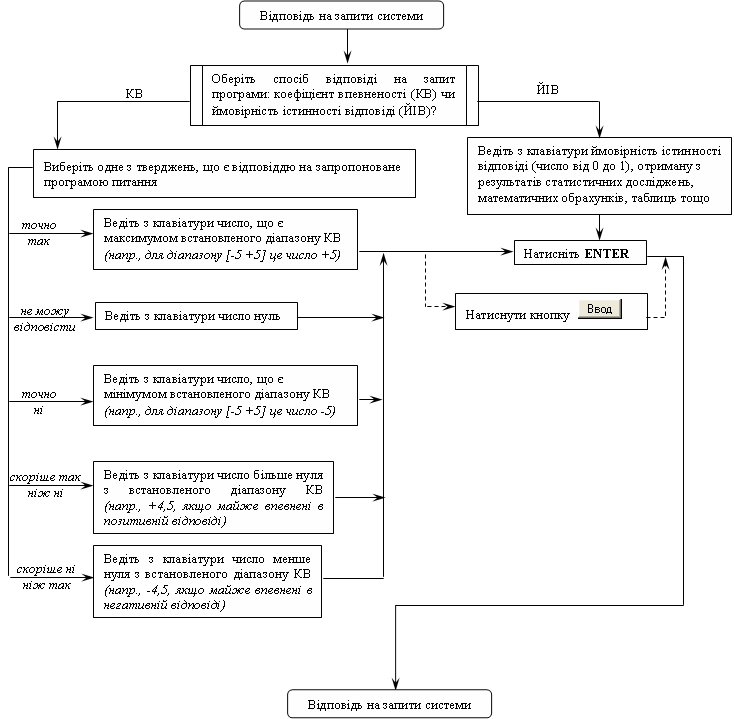
Схема 6. Модель відповіді користувача на запити системи