

Общие черты intranet-систем
Из перечисленных решений, а это далеко не полный список возможных вариантов, можно вычленить некоторые общие свойства, которые характерны для любой intranet-системы:
опора на Web-технологию;
наличие СУБД и баз данных под ее управлением;
наличие системы контроля и разграничения доступа;
большой объем прикладного программирования.
Разберем каждое из этих свойств более подробно, и посмотрим что из этих свойств следует и чем эти следствия грозят корпорации, которая отважится построить свою корпоративную информационную систему в виде intranet-системы.
Все intranet-решения в той или иной степени опираются на применение Web-технологий в качестве основы информационного обмена. При этом в ряде случаев используется неполный набор средств, которые предоставляет Web. Для того чтобы двигаться дальше, рассмотрим схему основных компонентов Web (Рис. 1).
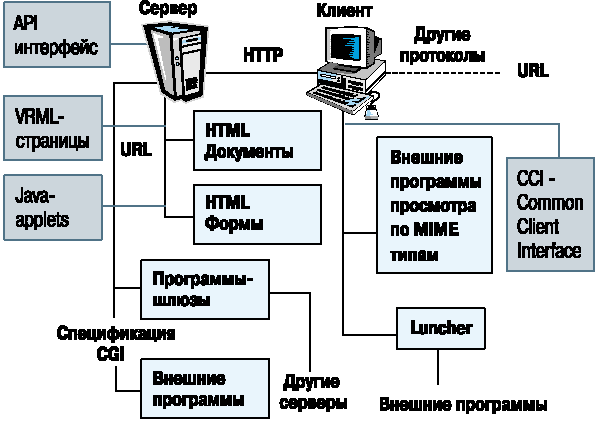
Рис. 1. Схема информационного обмена в рамках Web-технологии
Обмен информацией по технологи WWW является типичным информационным обменом по схеме "клиент-сервер". В качестве клиента обычно выступает программа-браузер. Это такие известные продукты, как Netscape Navigator компании Netscape или Internet Explore от Microsoft. С этими программами большинство пользователей сети хорошо знакомы. Однако не только браузеры могут быть клиентами в рамках информационного обмена WWW - многочисленные "паучки" тоже принимают участие в этом процессе. Они просматривают сеть на предмет появления новых информационных ресурсов, которые следует внести в индексы информационных служб Internet. Клиентами выступают также и редакторы документов Website, которые способны осуществлять опубликование материалов в сети посредством механизма обмена данными WWW.
Сервером же в этой модели выступает программа-сервер протокола обмена гипертекстовой информацией HTTP, которая отвечает на запросы клиентов. В общем случае в качестве сервера может выступать и сервер другого протокола, скажем Gopher или FTP. Такое расширенное толкование возникло по той простой причине, что с самого начала браузеры разрабатывались как мультипротокольные программы (знаменитая Mosaic - предтеча Netscape), обеспечивающие интерфейс доступа ко многим информационным ресурсам сети.
Поясним теперь процесс взаимодействия клиента и сервера при обращении клиента к ресурсам, которыми управляет сервер:
1. Инициатором начала обмена данными в этой схеме, как правило, является клиент.
2. Клиент посылает серверу запрос на получение от него определенного информационного ресурса. Запрос передается в формате HTTP, а адрес ресурса указывается в формате URL.
3. Сервер, получив запрос, определяет, является ли он запросом к информационному ресурсу, которым данный сервер управляет.
4. Если ресурс относится к зоне ответственности данного сервера, то сервер проверяет права доступа к данному информационному ресурсу, и если нет нарушения прав, то возвращает содержание ресурса клиенту (рис. 2).
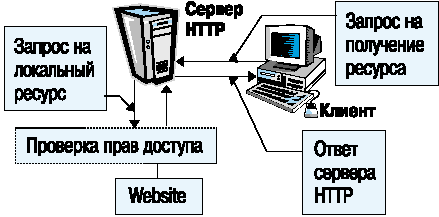
Рис. 2.Обращение к локальному ресурсу сервера.
5. Если запрос клиента нарушает права доступа к ресурсу, то сервер отклоняет запрос и возвращает соответствующее предупреждение клиенту.
6. В случае, если ресурс не относится к зоне ответственности данного сервера, сервер определяет не содержится ли в его файлах настройки информации о перемещении ресурса в сети (Redirection). Если ресурс был размещен на сервере, но в данный момент перемещен в другое место, то сервер сообщает об этом клиенту (рис. 3)
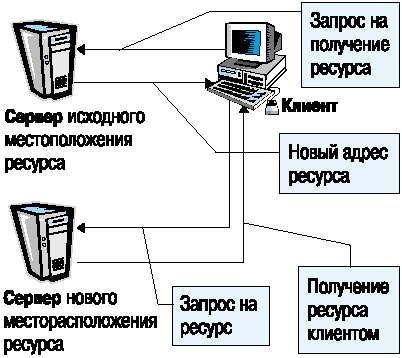
Рис. 3. Выполнение процедуры перенаправления запроса (Redirection).
7. Если сервер поддерживает виртуальное дерево другого Website, то запрос будет перенаправлен на нужный ресурс в таком же ключе, как это происходит для процедуры Redirection.
8. Если сервер используется в качестве сервера-посредника (proxy-сервера), то он выступает, с одной стороны, в качестве сервера для клиента, пославшего запрос, а с другой стороны - в качестве клиента, который посылает запрос к другому серверу (рис. 4).
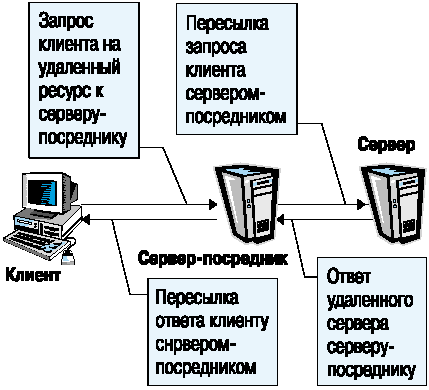
Рис. 4. Использование Web-сервера в качестве сервера-посредника.
9. После возвращения информации клиенту сервер разрывает соединение с ним.
Так в общих чертах выглядит взаимодействие клиента и сервера в рамках технологии обмена данными в среде WWW. Сервер WWW - это "умная" программа, которая действительно может использоваться для широкого круга задач. Наиболее типичными для современных серверов являются функции ведения иерархической базы данных документов, контроля за доступом к информации со стороны программ-клиентов, предварительной обработки данных перед ответом на запрос, взаимодействия с внешними программами через CGI, реализации взаимодействия с клиентами и другими серверами в режиме посредника, реализации встроенных, или взаимодействие с внешними поисковыми машинами.
Кроме того, такие серверы, как NetSite (Netscape Communication) и Apache, реализуют шифрованные протоколы HTTP для обмена информацией с клиентами, что позволяет использовать их в качестве основы для построения защищенных intranet-систем.
Рассмотрим теперь более подробно то, что собственно и составляет совокупность информационных ресурсов сервера - его базу данных или Website (рис. 5).
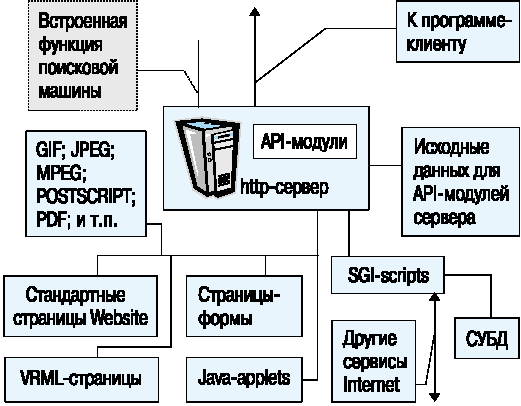
Рис. 5. Структура базы данных и программного обеспечения Website
Итак, основной задачей для любого сервера является ведение его базы данных - части файловой системы, служащей для размещения файлов HTML-документов. В данном случае термин "База данных" применяется просто для обозначения всей совокупности данных, к которым можно получить доступ через Web-сервер. Большинство современных файловых систем - это иерархические деревья, следовательно, и база данных HTTP-сервера также является таким деревом. Для любой базы данных необходимо ввести понятие единицы хранения - минимальный объект, к которому можно обратиться извне или получить в качестве ответа на запрос. Стандартным объектом хранения в базе данных HTTP сервера является HTML-документ. Кроме такого стандартного объекта многие серверы поддерживают различные комбинированные объекты хранения, создаваемые в ряде случаев из нескольких файлов или генерируемые программами "на лету".
Если обратиться к терминологии, принятой в WWW, то можно выделить следующие основные объекты, с которыми оперирует сервер и программа-клиент:
Страница базы данных World Wide Web - это законченный информационный объект, который отображается пользователю при обращении к информационному ресурсу WWW по универсальному идентификатору этого ресурса (URI, URL).
База данных World Wide Web или Website - набор страниц базы данных WWW. При более подробном рассмотрении Website - это вся совокупность данных и программного обеспечения, обеспечивающая отображение страниц информационной базы данных Web.
Если страница Website представляет собой обычный файл в стандарте HTML, то тогда говорят об элементарном или стандартном элементе хранения. В таком случае URL указывает непосредственно на этот файл и сервер просто отправляет его в ответ на запрос пользователя.
Многие страницы содержат внутри себя контейнеры-формы, которые служат для передачи информации от программы клиента программе-серверу. В рамках данного рассмотрения эти страницы выделены в особую группу страниц WWW.
Страницей-формой будем называть в данном контексте файл в формате HTML, который содержит в себе HTML-форму.
После обращения к странице-форме, как правило, следует вызов либо API-модуля, встроенного в сервер, либо CGI-программы. В свою очередь такое действие вызывает генерацию этим модулем или программой виртуальной страницы.
Виртуальной страницей Website будем называть страницу, которая в виде файла в файловой системе сервера не существует. Данная страница появляется только в момент обращения клиента к серверу. Один из способов генерации виртуальной страницы - это генерация при помощи API-модуля или CGI-программы. При этом весь текст страницы может порождаться программой, либо могут использоваться файлы-заготовки. Генерируются не только текстовые файлы, но и графика. Одним из самых популярных способов генерации документов является обращение к стекам гипертекстовых ссылок и СУБД. Второй способ генерации виртуальной страницы - это генерация такой страницы сервером в тело документа и файлы описания иерархии документов сервера включаются команды преобразования документов. Сервер может, в общем случае, производить условную генерацию документов на основе информации, полученной от программы-клиента.
VRML-страница - это такой же объект, как и обычные страницы Website, только написанная на другом языке. К VRML-страницам можно применять все те же механизмы генерации, что и к страницам HTML.
Java-applet - это мобильный код, сгенерированный компилятором апплетов. Множество апплетов составляет в базе данных Website отдельный каталог файловой системы сервера. В страницы HTML встраиваются специальные контейнеры апплетов, позволяющие программе-клиенту распознавать наличие апплетов и подгружать их в качестве части страницы.
Минимальный набор инструментов, который необходим для поддержания страниц базы данных - это редакторы файлов формата HTML, GIF, в том числе и версии GIF89A, и JPEG, редакторы файлов формата MPEG, VRML, редактор аудиофайлов, компилятор байткода Java.
Как уже отмечалось, в intranet-системах Website представляет собой совокупность всех информационных ресурсов корпорации. При таком толковании от монолитного Website логично перейти к распределенному, где информационные ресурсы корпорации будут распределены между различными компьютерами системы. В этом случае полная схема (рис.1) не всегда будет реализована. Так, например, не обязательно устанавливать сервер протокола HTTP - для многих СУБД имеются апплеты, которые способны формировать запросы к базе данных напрямую без обращения к серверу HTTP. При этом, конечно, СУБД должна обеспечивать поддержку такого обращения по сети.
Рассуждая о Web как о сердце intranet-системы, нельзя не обратить внимание на последствия, к которым приводит такая ориентация. А последствия достаточно серьезные.
Во-первых, если рассматривать данную технологию в рамках сетевого обмена и модели такого обмена OSI, то это уровень приложений данной модели. Под ним имеются еще 6 уровней протоколов. При этом Web - уровень приложений стека протоколов TCP/IP, а протокол HTTP опирается на транспортный протокол TCP. Если intranet - это система корпоративная, и корпорация распределена по большой территории, то использование TCP/IP оправдано и позволяет применять Internet в качестве сети, поверх которой можно организовать виртуальную локальную сеть корпорации. Естественно, что в этом случае сеть должна быть защищенной. При таком решении происходит тиражирование технологии ведения информационной системы во все ее сегменты, а обмен информацией между сегментами осуществляется в рамках той же технологии, что и работа внутри сегмента. Если доводить данный подход до его логического завершения, то в рамках обмена TCP/IP можно организовать и локальную информационную систему на одном отдельно стоящем компьютере, вообще не включенном в сеть. Просто на нем необходимо установить все технологические компоненты, что вполне реально - практически для любой компьютерной платформы имеются и Web-клиенты, и Web-серверы.
Другое дело, если в качестве основы для корпоративной сети используется иная, отличная от TCP/IP технология. В этом случае создание intranet-системы приведет к тому, что в локальной сети будут вертеться два типа сетевых протоколов как минимум. Но здесь следует обратить внимание на то, что если сотрудники корпорации работают с ресурсами Internet, то TCP/IP уже все равно есть, и в этом смысле intranet в сетевой "зоопарк" ничего нового не внесет. Выбор в качестве основного интерфейса работы с информационными ресурсами Web-браузера предопределяет появление в сети TCP/IP. Ведь хоть эти программы и являются мультипротокольными, все протоколы, которые они поддерживают - это протоколы уровня приложений TCP/IP. Собственно, именно это и определяет использование TCP/IP в качестве основы сетевого транспорта в intranet.
Если остановиться на Web-браузерах более подробно, то при разработке Website для intranet снимается ряд проблем, которые существуют при создании Web-страниц для Internet. Разработчик корпоративного Website не связан теми жесткими ограничениями на правила использования инструментов Web при создании Web-страниц. Используемое внутри корпорации программное обеспечение хорошо известно, и при разработке Website следует ориентироваться именно на него. При этом нет необходимости в анализе журналов посещений для определения рамок возможного применения, например, JаvaScript. Однако это все касается только внутреннего компонента intranet - части, которая направлена на обслуживание сотрудников корпорации. Для представления информации во внешний мир все проблемы остаются прежними.
Во-вторых, это обязательное использование технологии ведения баз данных в ее традиционном смысле. Действительно, трудно представить корпоративную информационную систему без таких компонентов, как кадровая система или бухгалтерия. В рамках технологии баз данных эти задачи решены многократно и нет смысла снова изобретать велосипед. Кроме того, многие другие задачи, которые оперируют большими массивами структурированной информации, также требуют применения технологии баз данных для своего решения.
В этом смысле intranet-системы ничем не отличаются от других корпоративных информационных систем. Во всяком случае, объем прикладного программирования в них точно не уменьшился. При этом для обеспечения доступа к базе данных из Web-браузера можно использовать два основных способа: подключение сервера баз данных через Web-сервер, и доступ к серверу баз данных из Web-браузера напрямую (рис. 6).
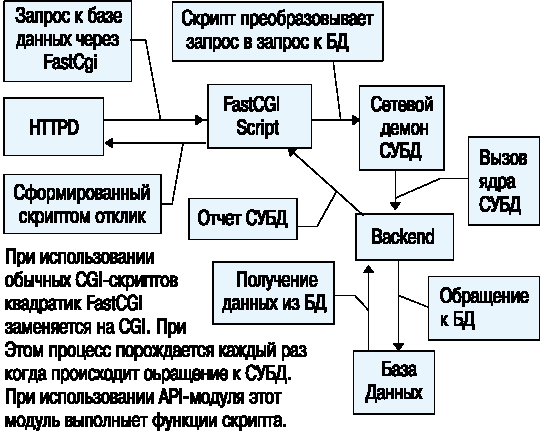
Рис. 6. Взаимодействие компонентов программного обеспечения при доступе
к базе данных через Web-сервер.
В первом варианте используются либо CGI-скрипты, либо специальные API-модули Web-сервера. Применение CGI-скриптов - гораздо более простой способ сопряжения сервера с внешним программным обеспечением, чем любой другой, который предоставляет Web-технология. При этом можно использовать самые разнообразные способы передачи запросов серверу баз данных, начиная от интерфейсов командной строки до написания программ, отредактированных с соответствующими библиотеками шага выполнения СУБД. В качестве интерфейса разработчик Website применяет HTML-формы, которые позволяют формулировать запросы к базе данных. Скрипты получают информацию от сервера либо через переменные окружения, которые порождает сервер, либо через стандартный ввод. Все зависит от метода доступа, который используется при обмене данными между браузером и сервером. Далее скрипт работает как обыкновенное приложение баз данных и возвращает ответ на запрос через стандартный вывод. Таким образом, разработчику не надо ничего знать о том, как устроен сервер. Более того, ему вовсе не обязательно использовать языки типа Cи - скрипт можно написать и на командном языке, например Perl. Такой подход существенно облегчает разработку прикладного программного обеспечения для Web вообще и для сопряжения баз данных с Web-сервером в частности.
Однако за простоту приходится платить низкой эффективностью процедуры обработки запросов, а точнее скоростью обработки этих запросов. Для систем, в которых обращение к базе является обычным делом и таких обращений много, разработка доступа из браузера к базе данных через CGI-скрипт неприемлема. Ответом на этот вызов стал переход к специализированным модулям доступа к базам данных, которые встраиваются как часть программного обеспечения сервера. Для этого перешли от монолитных серверов к модульным, и разработчики серверов предложили интерфейс сопряжения модулей с сервером, который получил название API-интерфейса. В отличие от CGI API-модули должны быть откомпилированы и собраны в единое целое с сервером. Фактически API-модуль - это часть сервера, написанная прикладным программистом. Естественно, что при таком подходе в жертву эффективности была принесена мобильность кода и его независимость от конкретной реализации сервера. Для WWW последнее замечание довольно важное. Так, например, использование модулей перекодировки символ "на лету" на отечественных Website тормозит переход на более совершенные версии Web-серверов - модули написаны для ранних версий и с новыми не всегда желают работать. В результате тот же модуль для Apache работает с версиями 1.1.x, но уже вышла версия 1.2, которая обладает большим числом новых возможностей, от которых не хочется отказываться. Следует, правда, заметить, что в данном случае для intranet-системы это не столь существенно. Ориентация на корпорацию заставляет освободиться от проблем перекодировки - внутри корпорации используется, как правило, один и тот же тип программного обеспечения, и, следовательно, нет необходимости использовать разные кодовые страницы для представления одной и той же информации.
Очевидно, что для программирования модулей требуется программист гораздо более высокой квалификации, чем для программирования CGI-скриптов. Поэтому стали появляться способы построения некоторого промежуточного варианта, который, с одной стороны, удовлетворял бы требованиям мобильности, независимости и простоты программирования, а с другой стороны - был бы достаточно эффективным. Одним из таких решений является спецификация FastCGI. Идея этой спецификации в том, что прикладная программа использует способ передачи параметров и данных, который применяется в CGI, но при этом не удаляется из памяти, а остается демоном, который получает запросы от сервера и обрабатывает их. При работе через FastCGI с базами данных получается схема, в которой фактически используется три демона HTTPD (Web-сервер), FastCGI-скрипт и сервер базы данных. HTTPD принимает запрос Web-браузера и передает его FastCGI-скрипту, который в свою очередь обращается к серверу баз данных. Обычно в качестве последнего выступает не собственно ядро базы данных, а некоторый демон, который это ядро (backend process) запускает.
Другой способ непосредственного обращения к СУБД из Web-браузера - использование plug-in либо Java-applet. В этом случае СУБД не обязана поддерживать протокол HTTP. Запрос попадает на сетевой демон СУБД в том же виде, как и с любого другого клиента, который не использует Web-технологии. Преобразование запроса в надлежащую форму возлагается в этом случае либо на plug-in-программу, либо на апплет. Программировать здесь придется ничуть не меньше. Разница только в том, что часть работы по преобразованию запросов и формированию отчетов возлагается на программное обеспечение, которое выполняется на компьютере пользователя. При этом в случае с plug-in придется соблюдать соответствующие спецификации по обмену данными между браузером и прикладной программой, что сильно зависит от типа браузера, а во втором случае осваивать программирование апплетов на Java. Если учесть, что Java будет исполняться браузером в режиме интерпретации мобильного кода, то требования к аппаратуре, установленной у пользователя, в части производительности и объема оперативной памяти возрастают, и, как показывает практика, существенно.
Кроме работы с обычными базами данных в рамках intranet-систем появляется необходимость развертывания информационно-поисковых систем (ИПС), которые облегчают навигацию пользователя в гипертекстовой сети Website. Типичным примерами такого рода систем и программного обеспечения для их поддержки являются Altavista и Harvest. Общая схема такой системы может состоять из следующих компонентов (рис. 7): интерфейс пользователя, поисковая машина, система индексирования и робот сканирования сети.
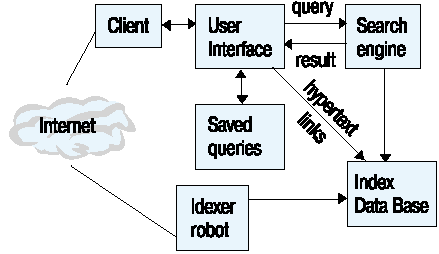
Рис. 7. Схема построения информационно-поисковой службы
В качестве источника информационных ресурсов указан Internet, но с тем же успехом здесь можно написать и intranet, подразумевая внутренние информационные ресурсы корпорации. На самом деле должны быть указаны оба источника. Фактически речь идет о создании общего информационного каталога информационных источников вне зависимости от того, где этот источник расположен, во внутренней информационной системе или во внешнем мире. Для сотрудника корпорации этот ресурс должен быть одинаково легко доступен. К тому же, при использовании кэширующих серверов, пользователь может и не заметить разницу во времени доступа к ресурсу, потому что тот будет расположен во временной памяти на диске Web-сервера. Единственное отличие от ресурса, хранящегося в базе данных корпорации, будет состоять в том, что заботу о ведении этого ресурса будет выполнять та информационная служба, которая данный ресурс в сети разместила. Таким образом, ИПС, построенная на основе Web-технологии, представляет собой единый виртуальный тематический каталог корпорации.
Если кратко пройтись по функциям каждого из компонентов этого программного обеспечения, то получим примерно следующее:
Интерфейс пользователя отвечает за поддержание сеансов работы с ИПС. В данном случае можно говорить о периодическом исполнении постоянно действующих запросов или о хранении предыдущих запросов каждого из пользователей системы. Здесь же происходит преобразование запросов из формы их представления в HTML-формах в формат запроса ИПС.
Поисковая машина осуществляет поиск информации в базе данных индекса ИПС и формирует список ссылок на информационные ресурсы. При этом ссылки могут указывать как на документы корпоративного Website, так и на документы во внешней сети.
Индекс создается системой ведения индекса. При этом используются различные конверторы из форматов документов сети и системы нормализации лексики наподобие системы Яndex.
Робот сканирования сети периодически просматривает сеть на предмет внесения новых документов, соответствующих тематике корпорации, и внесения изменений в существующие документы. Если рассматривать intranet только как сугубо внутреннюю систему корпорации, то необходимости в сканировании и поиске информации нет - источник новых поступлений известен. Но если рассматривать систему в качестве виртуального каталога, то необходимость в такого вида работе очевидна.