

Запоминающее устройство на магнитной ленте.
Характеристики:
ёмкость: неограниченная;
время доступа: секунды и минуты;
управляется оператором (пользователем);
стоимость: 0,000001 цент/бит.
Просматривая пирамиду памяти сверху вниз, выявляются следующие закономерности:
уменьшается стоимость хранения 1 бита информации;
возрастает ёмкость;
растет время доступа (уменьшается быстродействие);
уменьшается частота обращения памяти со стороны ЦП.
Смысл такого построения памяти основывается на принципе локальности по обращению, который имеет 3 составляющих:
Пространственная локальность программы.
Суть: большинство процессов, обрабатываемых ЭВМ, с очень высокой долей вероятности адрес очередной команды определяют из текущего адреса или близлежащего адреса, т.е. осуществляется сфокусированность адресов.
Пространственная локальность данных.
Данные структурируются и хранятся последовательно в ячейках памяти. Место хранения данных тоже сфокусировано.
Временная локальность.
Учитывается, что множество программ содержат в себе короткие циклы и короткие подпрограммы, т.е. небольшие наборы команд могут многократно повторяться в течение некоторого программного времени, т.е. время сфокусировано.
90 % программы связано с обращением к 10 % адресного пространства. Программу при выполнении разумно представить в виде последовательно обрабатываемых фрагментов – компактных групп адресов и данных. Помещая фрагмент в более быстрый верхний уровень, сокращается время выполнения программы, т. е. увеличивается быстродействие. Для этого фрагменты из медленного уровня помещаются в верхний соседний уровень, что позволяет хранить большие объемы информации в медленных уровнях, а обрабатывать - в быстрых. На каждом уровне информация разбивается на блоки. Блок – наименьшая информационная единица, которая пересылается между двумя соседними иерархическими уровнями памяти. Размер блока может быть фиксированным, а может быть переменным. При фиксированном размере блока емкость памяти кратна размеру блока. Размер блока для различных уровней различен и увеличивается при движении от верхних уровней к нижним. Т.к. блок – часть программы, то программа может выйти за размер блока.
При обращении процессора к памяти необходимая информация сначала ищется на самом верхнем уровне. Если информация находится, то говорят, что имеет место «Попадание», иначе речь идет о «Промахе». В случае «Промаха» поиск снижается по уровню и на более низком уровне возможно «Попадание» или «Промах». Вопрос в том, как соотносятся блок и выполняемая программа? Всегда существует обмен в ЭВМ между сложностью и быстродействием. При нахождении информации она пересылается вверх и с ней начинает работать процессор. Применение многоуровневой памяти дает выигрыш в быстродействии. Пересылка блоков идет между соседними уровнями (не перескакивает между уровнями), осуществляется программно и аппаратно, без вмешательства оператора.
Для оценки эффективности памяти используется ряд характеристик:
Коэффициент попадания. Высчитывается, как отношение числа обращений при попадании к общему числу обращений;
Коэффициент промахов. Высчитывается, как отношение числа обращений при промахе к общему числу обращений;
Время обращений при попадании. Выставляется требование к информации на самый верхний уровень.
Время потери при промахе. Время для замены блока в верхнем уровне на необходимый блок из нижнего уровня. Потери складываются из времени доступа к верхнему уровню и времени пересылки из нижнего уровня к верхнему.
Если описывается конкретный уровень памяти, то при описании конкретизируются следующие моменты:
Размещение блока. Где допустимо расположение блока на примыкающем сверху уровне.
Идентификация блока. Способ нахождения блока на верхнем уровне.
Замещение блока. Как осуществляется выборка заменяемого блока, как туда размещается необходимый блок.
Согласование копий блоков, расположенных на разных уровнях. Возникает необходимость при записи новой информации в копию, расположенную на верхнем уровне.
11.2. Основная память
Основная память – единственный вид памяти, к которой процессор может обращаться непосредственно. Во всех остальных случаях обращение происходит только через интерфейс и все, что идет в память сначала нормализуется в основной памяти. В ней информация переводится в язык, понятный процессору.
Как организуется память?
Любое запоминающее устройство есть совокупность основных элементов памяти.
ЗУ=∑ОЭП
К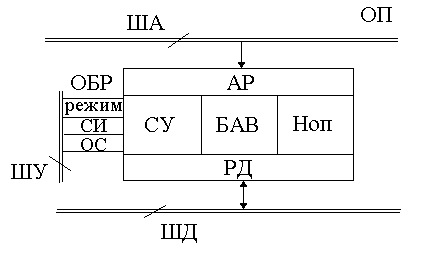 раткие
обозначения:
раткие
обозначения:
ШД - шина данных
ША – шина адреса
ШУ – шина управления
АР – адресный регистр
СУ – схема управления
БАВ – блок адресной выборки
Ноп – накопитель основной памяти
Р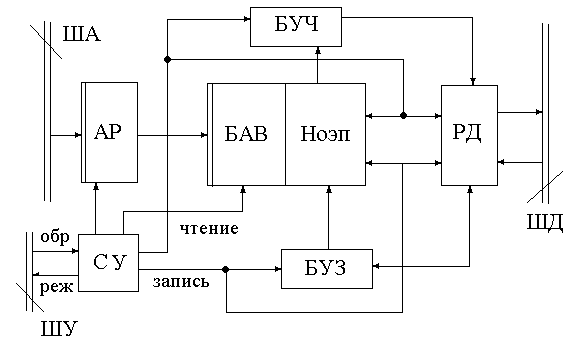 Д
– регистр данных Рис. 3 Структура
памяти
Рисунок 126. Структура памяти
Д
– регистр данных Рис. 3 Структура
памяти
Рисунок 126. Структура памяти
Краткие обозначения:
БУЗ – блок управления записи
БУЧ – блок управления чтения Рисунок 127. Функциональная схема ОП
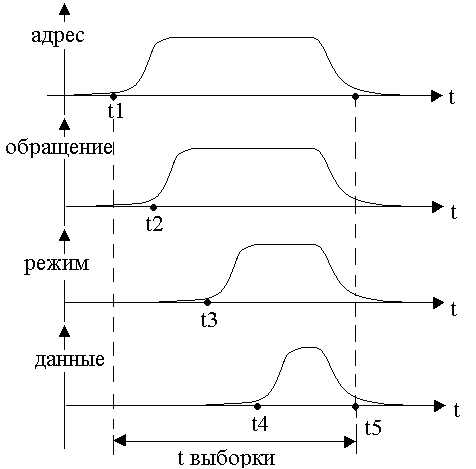
Рисунок 128. Диаграммы управления ОП
На рис.126 изображена общая схема памяти ЭВМ, на рис. 127 она рассмотрена более подробно.
Из шины адреса (ША) в адресный регистр (АР) приходит адрес информационного слова. В простом случае блок адресной выборки это дешифратор. Сигнал РЕЖИМ подается на вход схемы управления. Выбирается один из режимов: чтение или запись. Если режим ЗАПИСЬ, то выполняет свою работу БУЗ, инициирую РД и Ноэп. Если режим ЧТЕНИЕ, то инициируются другие элементы схемы.
Рассмотрим рис.128. В момент времени t1 вводится адрес информации, ничего пока не происходит. В момент времени t2 получено обращение, режим не установлен. Во время t3 устанавливается режим чтение или хранение. Этот сигнал появляется на выходе СУ. В момент t4 можно начинать чтение из РД, т.к. заканчиваются переходные процессы во всех связях и на выходах ОП появляется истинная информация, в момент t5 отображается истинная информация, может происходить режим записи.
Время выборки – время между t1 и t5 (между началом запроса и его окончанием).
Если обращения нет, то память находится в режиме хранения (используются только Ноэп и РД).
ЗУ с произвольной выборкой (БАВ):
ЗУ с однокоординатной выборкой (ЗУ со словарной организацией памяти);
ЗУ с двухкоординатной выборкой (ЗУ с матричной выборкой памяти);
ЗУ с трехкоординатной выборкой (ЗУ со страничной организацией памяти)
Организация ЗУ зависит от того, что собой представляет ЗЭ. Это может быть триггер, перемычка, ёмкость, специальный p-n переход. Наиболее понятным является триггер. Рассмотрим его использование в ЗУ.
Триггер.
Если в ЗУ используется в качестве ЗЭ триггер, то это статическое ЗУ.
Простейший случай – R-S триггер, изображен на рис. 129.
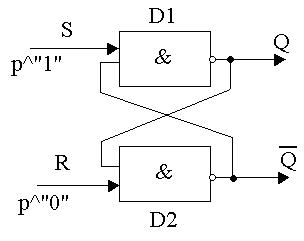
Рисунок 129. R-S триггер _
Состояние триггера определяют по значению выхода Q, а Q – его инверсный выход, р – разрядная линия.
Если передается «1», то состояние S=1, R=0.
Если передается «0», то состояние S=0, R=1.
Режим хранение, при значении S=1, R=1.
При сокращении числа линий, но при сохранении режима работы, рис.129 будет выглядеть так (рис. 130):
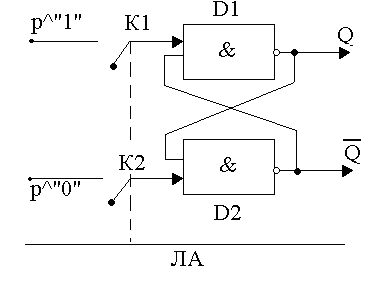
Рисунок 130. S-R триггер с ключами
На рис. 130 изображен тот же триггер, что и на рис129, но он использует подачу сигнала по входам, сокращая число линий. Если есть обращение к ячейкам, то ключ замкнут (режим обращения), если нет обращения – ключ разомкнут (режим хранения). Обращение идет от линии адреса (ЛА). Р^”1” и P^”0” могут быть использованы как для записи, так и для чтения.
11.3. Зу с однокоординатной выборкой (со словарной организацией)
Самая простая структура у ЗУ со словарной организации. Изображена на рис. 131.
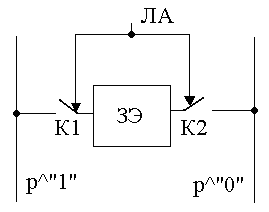
Рис131. Структура ЗУ с однокоординатной выборкой
С помощью ключей производится доступ к триггерам, если они замкнуты.
Блок адресной
выборки. 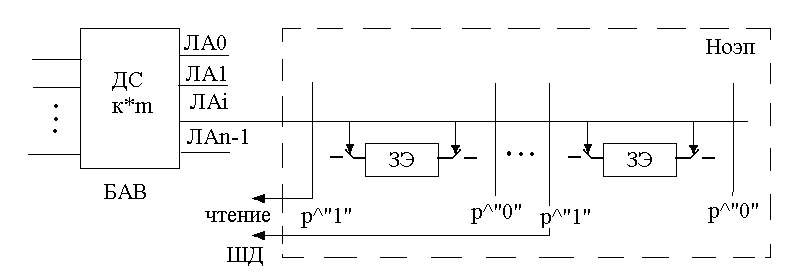
Рисунок 132. БАВ при ЗУ с однокоординатной выборкой
У каждого ЗЭ есть ключи к разрядной линии. При выборе данного адреса возбуждается некоторая разрядная линия, потом воздействуют на запоминающие устройства на i-ой линии.
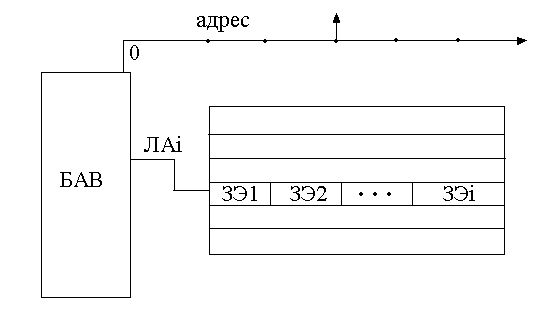
Рисунок 133. Строчная организация ЗУ
Информация снимается по каждой строчке, которая задает ЛА. Линия эквивалентна накопителю. Задается всего лишь одна координата.
Целесообразно при применении в системах с организацией 10х1024.
11.4. Зу с двухкоординатной выборкой (с матричной организацией)
Д ля
данного ЗУ нахождения информационного
слова нужно задается номером строки и
столбца (см. рис. 134).
ля
данного ЗУ нахождения информационного
слова нужно задается номером строки и
столбца (см. рис. 134).
Рисунок 134. Задание информационного слова в ЗУ с двухкоординатной выборкой
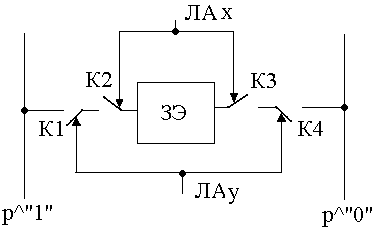
Рисунок 135. Структура ЗЭ с двухкоординатной выборкой
Связь осуществляется через 4 ключа. Управление производится от двух линий адресов: Х и У. Ключи К1 и К2 отвечают за Х, ключи К3 и К4 – за У. На пересечении срабатывает ЗЭ.
Адрес любая ячейки разбивается на 2 части: на старшие и младшие адреса. БАВ состоит из дешифраторов строк и столбцов и его можно изобразить следующим образом (см. рис. 136):
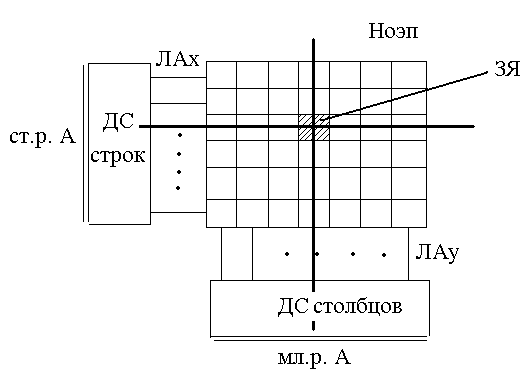
Рисунок 136. БАВ при ЗУ с двухкоординатной выборкой
ЗЯ=∑ЗЭ
На пересечении строк и столбцов содержится ЗЯ с ИC длиной n. ЗЭ соединены параллельно. Их отличие одного от другого состоит в том, что они подсоединяются к разным линиям ШД.
Предел по объему памяти составляет 1М бит (организация 1024х1024).
11.5. Зу с трехкоординатной выборкой (со страничной организацией)
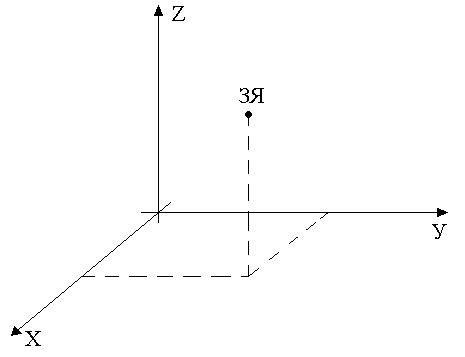
Рис. 137. Задание информационного слова в ЗУ с трехкоординатной выборкой.
Предел по объему памяти составляет 1Г бит.
Трехкоординатная выборка осуществляется за счет сигнала обращения. Например, по двухкоординатной выборке организован 1 кристалл (куб). Самые старшие разряды используются для выработки сигнала обращения. Идет инициализация элемента памяти. А в ОЭП используется двухкоординатная выборка.
ЗУ с трехкоординатной выборкой называется ЗУ со страничной организацией, т.к. существуют страницы и к ним происходит обращение.
При увеличении объема увеличивается размер адреса. Значит, нужны методы, которые позволят увеличить емкость ЗУ.
Как увеличить ёмкость зу при различных ситуациях?
ЗУ=∑ОЭП (память имеет организацию mxn), где m – число ИС, а n – длина ИС
mЗУ=mОЭП
nЗУ>nОЭП
nЗУ=L· nОЭП
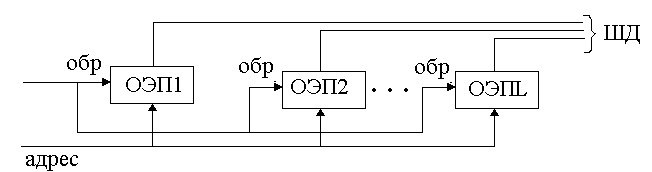
Рисунок 138. Схема увеличения длины ИС в ЗУ
На все ОЭП поводят одновременно сигналы обращения, они инициализируют все ОЭП. На выходы подсоединяются к различным линиям ШД.
nЗУ=nОЭП
mЗУ>mОЭП
mЗУ=k·mОЭП (увеличиваем емкость в k раз)
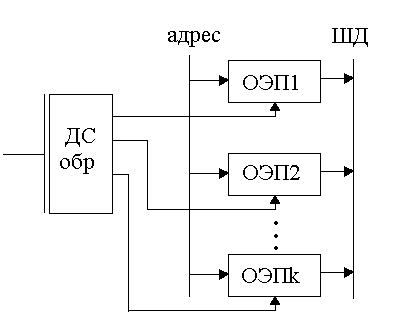
Рисунок 139. Схема увеличения глубины ЗУ
Ко всем ОЭП подают один адрес. По старшим разрядам они различаются - посылают сигнал обращения на выбранный ОЭП. Тогда из этой ячейки данные будут считываться и поступать на ШД,
Посылается сигнал обращения и выбирается элемент памяти.
nЗУ>nОЭП
mЗУ>mОЭП
Применяются два перечисленных метода выше в совокупности.
Метод организации увеличения ёмкости:
m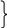 ЗУ>>mОЭП
ЗУ>>mОЭП
nЗУ=nОЭП
12. Организация оп
Увеличение быстродействия ОП решается за счет блочной организации основной памяти и за счет пользования локальности по обращению.
Блочная организация классифицируется на 3 группы:
Блочная организация.
Циклическая организация.
Блочно-циклическая организация.
12.1. Блочная организация памяти.
∑ОЭП=ЗУ
∑ЗУ=МП (модуль памяти)
∑МП=БП (блок памяти)
Иногда вместо блока упоминается банк и поэтому память организуется в виде совокупности банков. Организация памяти идет за счет разбиения адреса на определенные группы разрядов.
mОП=512 ИС
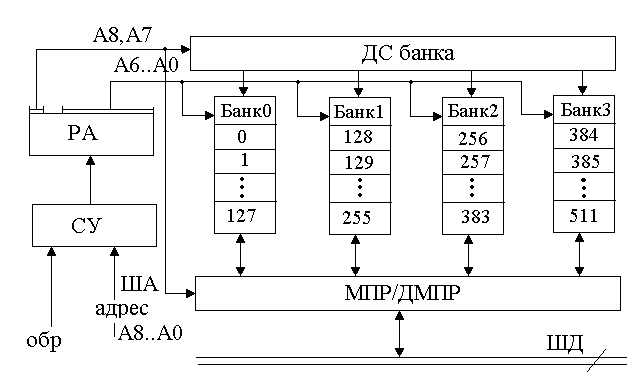
Рисунок 140. Блочная организация памяти
Краткие обозначения:
СУ – схема управления
РА – регистр адреса
ДС банка – дешифратор банка
МПР/ДМПР – мультиплексор/демультиплексор
обр – обращение
0, 1.. 127 и т.д. –ячейки памяти пронумерованы в порядке возрастания в каждом блоке
Приходит обращение и значения выходов с ША на схему управления регистра адреса.
Режим ЧТЕНИЯ. Вместе с обращением поступает команда чтения на СУ и СУ передает адрес в регистр адреса. В РА два поля: левое и правое. В левом находятся старшие разряды (А8, А7), а в правом – младшие разряды (А6..А0). В старших разрядах А8, А7 с помощью дешифратора включают тот или иной банк с организацией 2х4. Параллельно на 4 банка поступают младшие разряды А0..А6, но разрешение на чтение получает тот банк, обозначенный с помощью дешифратора и считывает ячейки. Данная информация поступает в ячейки МПР (с организацией 4х1) и затем информация идет из МПР в шину данных.
Режим ЗАПИСИ. Приходит с обращением команда записи на СУ и производятся все те же действия. Отличие от предыдущего режима внизу вместо мультиплексора работает демультиплексор.
Преимущество данной организации памяти: при параллельном доступе в банки обеспечивается более высокое быстродействие, т.к. сокращается процедура обращения к ячейкам.
Для увеличения быстродействия в несколько раз переходим к циклической организации памяти.
12.2. Циклическая организация памяти
mОП=512 ИС
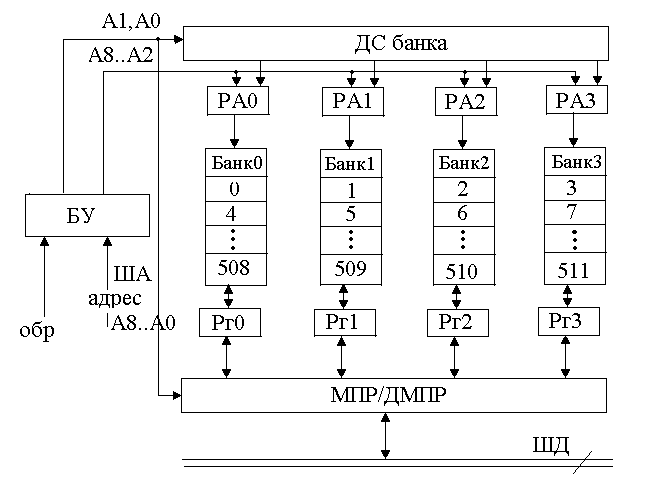
Рисунок 141. Циклическая организация памяти
Адрес выставляется по каждому банку в РА. У каждого банка есть регистры. Вход и выход производится через МПР и ДМПР. Особенность в нумерации ячеек. Если при блочной организации поля нумеруются сверху вниз, то здесь по строкам, слева направо. Нумерация по горизонтали носит название расслоение памяти. Очевидно, за счет расслоения увеличивается быстродействие, если используется локальность по обращению. Если выставить адрес по команде, то следующая будет смежной с ней, находится рядом.
Если режим ЧТЕНИЯ подается на БУ, то старшие разряды А2..А8 поступают в регистр адреса банков (РА). Съем осуществляется по команде от дешифратора. Дешифратор информирует двухразрядное слово А1, А0. Далее информация идет через регистр данных, МПР, на ШД.
Если режим чтение, то повторяются те же операции, только данные внизу поступают на ДМПР.
В данной организации памяти увеличивается быстродействие в обращении, при чем в b раз, где b – число банков.
12.3. Блочно-циклическая организация памяти.
Эта организация является комбинацией двух методов, описанных выше. Позволяет в определенной степени сочетать преимущество обоих методов.
mОП=512 ИС
Рисунок 142. Блочно-циклическая организация памяти
В каждом банке нужно выделить модули. В каждом банке находится по 2 модуля – четных и нечетных соседних номеров. Из ША данные поступают в форматный РА и в нем выделено 3 поля: поле старших разрядов, средних и младших. Каждое поле чем-то управляет: старшие разряды задают номер банка, к которому идет обращение, средние разряды – номер ячейки младшие разряды – номер модуля (при блочном обращении).
Блочно-циклическая организация существенно улучшает быстродействие памяти, так как получается минимальное время перехода от одной ячейки к другой.
Дальнейшее развитие в архитектуре памяти связано с развитием многопроцессорной системы. Тогда каждый банк имеет свой контроллер и управляется независимо, автономно. Проблема возникает, когда из двух процессоров обращение происходит к одной и той же ячейке.
12.4. Многопортовая память
Для повышения быстродействия системы используют многопортовую память.
В настоящее время существует память двухпортовая, четырехпортовая, восьмипортовая.
Рассмотрим функционирование двухпортовой памяти.
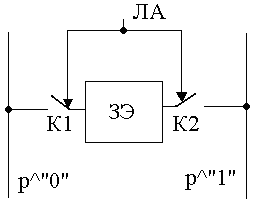
Рисунок 143. Структура однопортового ЗЭ
По выставленной ЛА идет использование ЗЭ. Если сигнал обращения – ключ замкнут, если хранение – разомкнут.
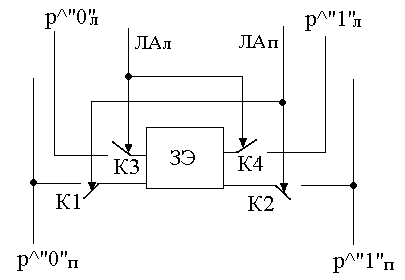
Рисунок 144. Структура ЗУ с двухпортовым ЗЭ
В данной схеме есть 2 шины данных и 2 шины управления.
Двухпортовая память
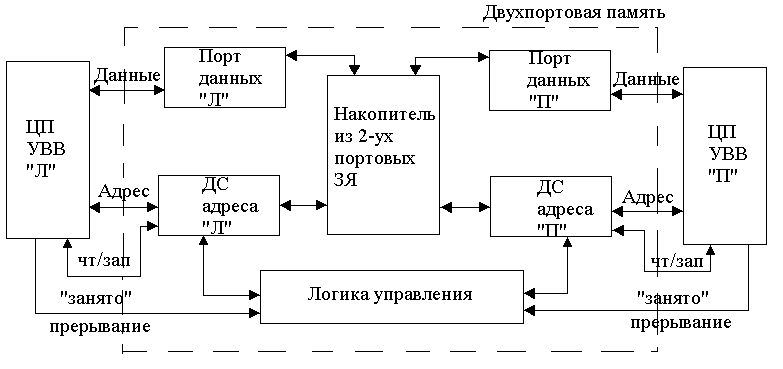
Рисунок 145. Схема двухпортовой памяти
Логика управления схемы:
В центре находится накопитель памяти на двухпортовых запоминающих элементах, так же изображены 2 шины адреса и 2 шины управления. Доступ возможен как слева, так и справа.
Исключительные ситуации возникают, когда запрос справа и слева поступает в 1 ячейку одновременно. Если запрос на чтение, то казусов нет, возникает только вопрос нагрузочной способности. Если, например, правая – чтение, левая – запись, то выдает неопределенную (случайную) величину. Если оба запроса запись, то тоже получаются случайные значения.
Поэтому логика управления – логика арбитража, она решается аппаратными средствами. Формируют логику сигнала ”занято”-прерывание. Логика включается, когда в 1 ячейку посылаются 2 запроса. Если сигнал от первого пришел раньше, то логика в его сторону, а для другого – ”занято”-прерывание. Если сигналы приходят одновременно на чтение, то разрешается выполнение обоих. Если сигналы приходят одновременно на запись, то арбитраж выбирает случайную логику (одному путь открыт, а другому закрыт). Если коллизий нет, то арбитраж разрешает свободную работу. Частота таких событий зависит от объема памяти и от числа портов. Для двухпортовой памяти коллизии имеют вероятность обращения примерно 0,1%.
12.5. Ассоциативная память
Если поиск идет по ассоциативным признакам, по сути информации, заложенной в ИС, то говорят, что используют ассоциативную память.
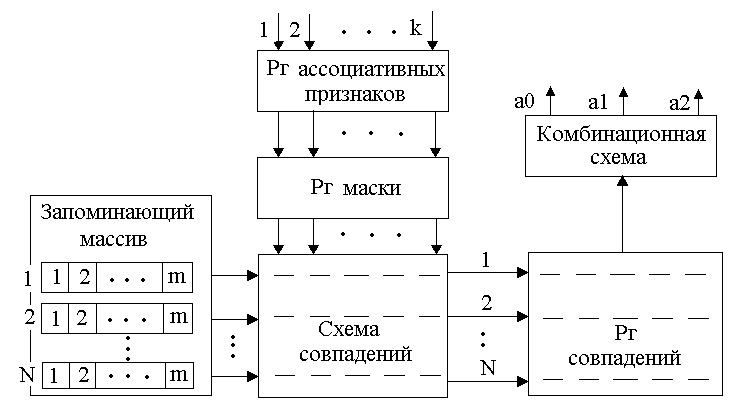
Рисунок 146. Структурная схема ассоциативной памяти
На схеме слева изображен запоминающий массив, где хранится информация о числе слов N, разрядов m. В центе находится схема совпадений. Выше – регистр маски, ассоциативные признаки. Признак формируется по k разрядам. Справа находится регистр совпадений, который может принять значения a0, a1, a2. Ассоциативным признаком может быть частью ИС, а так же может приравниваться ИС (тогда он называется тег - ярлык). Обычно тег располагается в младших разрядах. В регистр ассоциативных признаков помещается код искомой информации, т.е. признак поиска (k разрядное двоичное слово). В схеме совпадений по каждому разряду регистрируется, совпадает ли разряд с признаком или нет. Операция осуществляется параллельно. Для каждого бита ИС есть соответствующий бит в ассоциативном признаке. Факт совпадений запоминается в регистре совпадений. Если разряды одинаковые, то в соответствующих разрядах записывается 1.
Комбинационная схема принимает значения a0, a1, a2:
а0 – не найдено ИС;
а1 – искомая информация содержится в первой ячейке;
а2 – искомая информация содержится в нескольких ячейках. В этом случае нужно выбирать ту ячейку, которая необходима.
Ассоциативный поиск ИС может отличаться по виду поиска, способу опроса, по способу выборки при множественных совпадениях и по способу записи ИС.
Признаки классификации ассоциативной памяти:
По виду поиска:
простой (по разрядам);
сложный (по частичным совпадениям):
поиск максимума совпадений (продолжается до ближайшего большего);
поиск минимума совпадений (продолжается до ближайшего меньшего);
поиск всех слов больше заданного (определяется интервал, в котором идет поиск);
поиск всех слов меньше заданного (определяется интервал, в котором идет поиск) .
По способу опроса:
последовательно по словам;
параллельно по словам;
последовательно по разрядам ИС;
параллельно по разрядам;
комбинированно (параллельно по группе разрядов и последовательно по группе слов).
По способу выборки при множественных совпадениях с ассоциативными признаками:
с целью очередности (поочередно);
алгоритмически.
По способу записи информации в ассоциативное ЗУ:
Это когда запись очередного слова идет в ячейку с наименьшим номером. Наиболее сложный способ записи – предварительной сортировки информации по величине ассоциативного признака.
по адресу;
с сортировкой по величине ассоциативного признака на входе;
по совпадению признаков;
с целью очередности.
АЗУ – сложное устройство. При очень больших массивах информации оно не используется как самостоятельное, а идет как дополнительное.
13. Кэш память
Почему возникла необходимость в использовании КЭШ?
Динамическая ЗУ обладает на порядок меньше быстродействием. Основная ЗУ отстает от процессора. У статической ЗУ стоимость выше на порядок. Компромисс - в основную память вводится КЭШ память.
Суть: в операционную память добавляется блок КЭШ памяти. Обладает высоким быстродействием. С точки зрения процессора КЭШ не видна при обращении в ОП, но в ОП КЭШ присутствует. В КЭШ память отображается тем или иным способом ОП своими участками, и если поступает запрос от ЦП, то этот то этот запрос к ОП проходит сначала в КЭШ память, и если в ней запрашиваемое слово есть, то говорят о «попадании» процессора, а если слово отсутствует и обращается в основной массив ОП, то говорят о «промахе». Обращение к КЭШ требует меньшего времени чем к ОП. Основано на принципе локальности по обращению. Суть: если выполняемая команда из программы, то для выполнения программы требуется рядом текущая команда по адресу. Поэтому, если мы выбираем команду, а в ОП заносим команду рядом лежащую, то скорее всего буде попадание. Быстродействие увеличивается.
13.1. Архитектура кэш и оп и их взаимосвязь

Рисунок 147. Архитектура КЭШ и ОП
Связь процессора с КЭШ осуществляется специальной системой данных, более многоразрядной чем системная шина.
Как преобразует ИС из ОП в КЭШ?
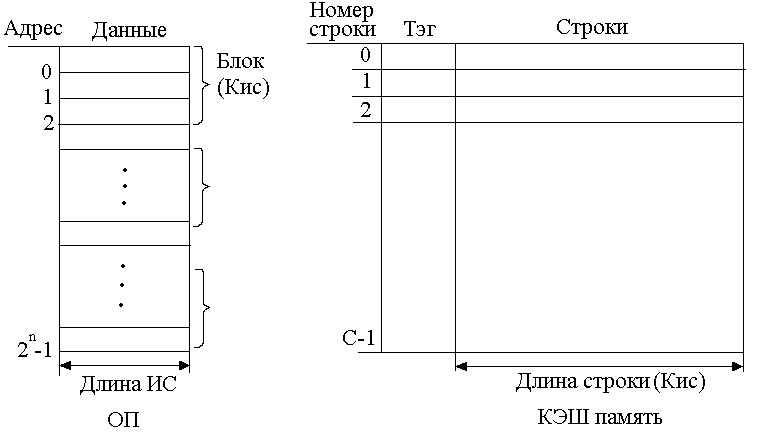
Рисунок 148. Связь ОП с КЭШ памятью
С<<M
Используется принцип локальности по обращению.
Память данных в ОП имеет 2n BC c номерами от 0 до (2n -1). Они разбиваются на блоки одинаковой длины. В каждом блоке собираются K ИС. Число таких блоков: M=2n/K.
У КЭШ памяти есть понятие строки, число которых С, которые имеют номера от 0 до (С-1). Длина каждой строки Кис. У каждой строки есть признак, который обозначается тэг.
Если выполняется команда из верхнего блока (0, 1 .. M-1), то все слова из этого блока размещаются в определенной строке КЭШ. Если работаем с каким-нибудь ИС, то рядом с ним есть другие ИС, необходимые для операции. Поэтому блоки ОП определенным образом размещаются в строках КЭШ.
Обычно признак строки (тэг) нужно сформировать. Используется часть адреса, который выставляет ЦП при запросе в ОП. Тэг берется оттуда.
Что влияет на эффективность такой архитектуры оп с кэш?
Емкость КЭШ;
Размер строки КЭШ;
Способ отображения ОП на КЭШ память;
Алгоритм замещения информации в заполненной КЭШ памяти.
Если КЭШ заполнена, то нужно чем-то жертвовать (есть алгоритм);
Алгоритм согласования ОП с содержанием КЭШ;
Число уровней КЭШ:
КЭШ L1 (на кристалле процессора);
КЭШ L2 (на материнской плате с микросхемами ОП);
Кроме этого существует дисковая КЭШ и проектируется КЭШ L3.
Емкость кэш памяти.
Определение параметров ёмкости КЭШ с точки зрения:
Стоимости. Нужно выбирать КЭШ малой ёмкости, тогда и стоимость окажется не очень высокой.
Быстродействия. Если увеличить ёмкость, то следует применять микросхемы памяти повышенной ёмкости для КЭШ. Тогда чем более громоздкой будет ёмкость, тем медленней станет работать КЭШ.
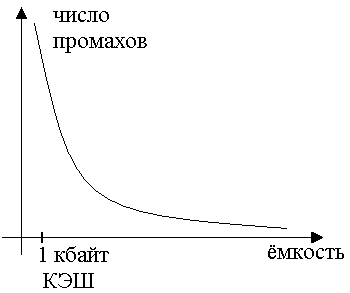
Рисунок 149. Зависимость вероятности числа промахов от ёмкости КЭШ
Если увеличиваем ёмкость КЭШ памяти, то число промахов уменьшается. Оптимальное значение для ёмкости лежит в пределах от 1 до 512 кбайт.
Заметно, что имеет смысл сделать КЭШ двухступенчатой: первый уровень будет находиться в пределах кбайт, а второй – в пределах сотни кбайт.
Как влияет на эффективность длина строки?
Когда размещаем в строки К информационных слов, то туда помещаются и соседние ИС. Увеличивая ёмкость строки, К растет, значит вероятность промахов падает. Когда размер становится излишне большим, вероятность промахов увеличивается при увеличении строки. Если строки удлиняются, то при заданном объеме КЭШ их число падает, а если число строк С будет уменьшаться, то возникает необходимость замены содержимого строк, что приведет к замедлению работы.
Для длины строк имеется оптимальное значение в районе 4 – 8 ИС. Длина строки выбирается равной ширине ШД, соединяющих ЦП с КЭШ.
13.2. Способы отображения оп на кэш память
Сущность отображения ОП на КЭШ – копирование блока ОП в строку КЭШ, одну из С строк. Если в запросе выставляется адрес интересующего нас ИС, то в рамках работы КЭШ памяти должна быть переадресация этого адреса из ОП в КЭШ память.
Требования:
Способ должен обеспечивать быструю проверку КЭШ памяти на наличие в ней необходимой копии блока ОП.
Обеспечивать быстрое преобразование адреса блока ОП в адрес строки КЭШ.
Все выполнения 2 предыдущих требований осуществлено экономными средствами.
Пример.
mОП=256 кИС
mКЭШ=2 кИС
Очевидно, что если mОП=256 кИС, то для адресации требуется 18 разрядов. ОП в этом случае разбивается на К блоков, где К=16.
Количество блоков: M=218/24=214
Значит, что из 18 разрядов адреса 4 младших разряда, которые определяют ИС в блоках, а оставшиеся 14 – адресуют блок.
Требуется 11 разрядов.
Как образовать адрес строки?
В строке 16 ИС, требуется 11 разрядов, из которых 4 младших разряда – для адресации внутри строки, а 7 – для адресации самой строки (адрес строки в КЭШ). Эти 7 оставшихся разрядов используются для образования тега (признака строки). Как они используются? Зависит от способа отображения ОП на КЭШ.
Способы отображения ОП на КЭШ разделяются на три группы:
прямой способ отображения;
полностью ассоциативный способ отображения;
комбинированный способ отображения (частично ассоциативный способ отображения).
Рассмотрим прямой способ отображения ОП на КЭШ память:
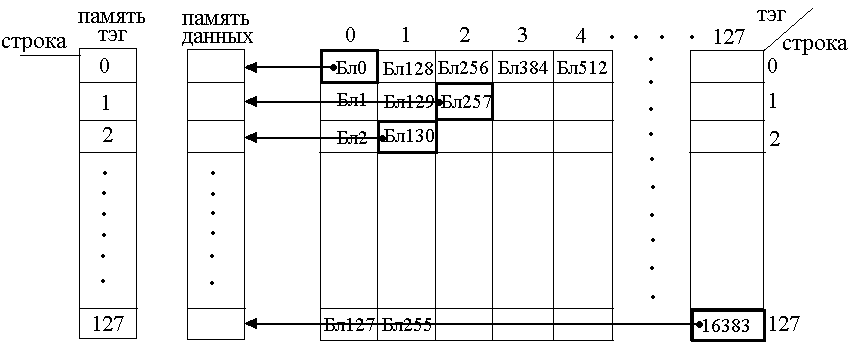
КЭШ память ОП
Рисунок 150. Прямой способ отображения ОП на КЭШ
В соответствии с числовыми параметрами адресация строк проводится с 7-разрядным адресным кодом, т.е. 27=128 строк (0..127). Отводится 7 разрядов на память тэгов, число которых равняется 128.
В чем же состоит суть прямого отображения?
j блок ОП отображается в i блоке КЭШ. Отображение идет по принципу i=j mod 128.
При отображении мы описываем блок на пересечении тэга и строки.
ЦП выставляет 4 младших разряда для адресации необходимого ИС в строке ОП или в строке КЭШ. Оставшиеся 14 разрядов разбиваются на номер строки и на номер тэга. С помощью этих координат можем задать тот блок ОП, с которым работаем и следовательно можем задать номер строки в КЭШ.
Достоинства и недостатки прямого способа отображения.
Достоинства: логичность (причинность) преобразований.
Недостатки: если работаем с двумя блоками ОП, расположенных на одной строке, придется перезаписывать информацию в КЭШ. Это замедляет вычислительный процесс.
Чтобы устранить недостаток прямого отображения, используется ассоциативное отображение ОП на КЭШ, при котором любой блок ОП может отображаться в любую строку КЭШ.
Содержание
1. Предмет и задачи курса . . . . . . . . 2
2. Мера информации . . . . . . . . . 2
3. Принципы организации и построения ЭВМ . . . . . 4
4. Организация интерфейса . . . . . . . . 14
5. Обмен информацией между ядром ЭВМ и ВУ(УВВ) . . . . 21
6. Микрооперация сдвига . . . . . . . . 26
7. Основные характеритики и режимы работы ЭВМ . . . . . 33
8. Вычислительные системы . . . . . . . . 38
9. Арифметико-логическое устройство . . . . . . 41
10. Устройства управления в процессоре . . . . . . 66
11. Память . . . . . . . . . . 72
12. Организация ОП . . . . . . . . . 81
13. КЭШ память . . . . . . . . . . 87
n