

2.6. Поняття про Data Mining
В даний час елементи штучного інтелекту активно упроваджуються в практичну діяльність менеджера. На відміну від традиційних систем штучного інтелекту, технологія інтелектуального пошуку і аналізу даних або "здобич даних" (Data Mining - DM), не намагається моделювати природний інтелект, а підсилює його можливості потужністю сучасних обчислювальних серверів, пошукових систем і сховищ даних. Нерідко поряд із словами "Data Mining" зустрічаються слова "виявлення знань в базах даних" (Knowledge Discovery in Databases).
Data Mining - це процес виявлення в сирих даних раніше невідомих, нетривіальних, практично корисних і доступних інтерпретації знань, необхідних для прийняття рішень в різних сферах людської діяльності. Data Mining представляють велику цінність для керівників і аналітиків в їх повсякденній діяльності. Ділові люди усвідомили, що за допомогою методів Data Mining вони можуть одержати відчутні переваги в конкурентній боротьбі.
У основу сучасної технології Data Mining (Discovery-driven Data Mining) покладена концепція шаблонів (Patterns), що відображають фрагменти багатоаспектних взаємостосунків в даних. Ці шаблони є закономірностями, властивими вибіркам даних, які можуть бути компактно виражені в зрозумілій людині формі. Пошук шаблонів проводиться методами, не обмеженими рамками апріорних припущень про структуру вибірки і вид розподілів значень аналізованих показників. На рис. 2.17 показана схема перетворення даних з використанням технології Data Mining.
Основою для всіляких систем прогнозування служить історична інформація, що зберігається в БД у вигляді тимчасових рядів. Якщо вдається побудувати шаблони, адекватно поведінки цільових показників, що відображають динаміку, є вірогідність, що з їх допомогою можна передбачити і поведінка системи в майбутньому. На рис. 2.18 показаний повний цикл застосування технології Data Mining.
Важливе положення Data Mining - не тривіальність розшукуваних шаблонів. Це означає, що знайдені шаблони повинні відображати неочевидні, несподівані (Unexpected) регулярності в даних, складові так звані приховані знання (Hidden Knowledge). Ділових людей дійшло розуміння, що "сирі" дані (Raw Data) містять глибинний пласт знань, і при грамотній його розкопці можуть бути виявлені справжні самородки, які можна використовувати в конкурентній боротьбі.
Сфера застосування Data Mining нічим не обмежена - технологію можна застосовувати усюди, де є величезні кількості яких-небудь "сирих" даних!
В першу чергу методи Data Mining зацікавили комерційні підприємства, що розгортають проекти на основі інформаційних сховищ даних (Data Warehousing). Досвід багатьох таких підприємств показує, що віддача від використання Data Mining може досягати 1000%. Відомі повідомлення про економічний ефект, що в 10-70 разів перевищив первинні витрати від 350 до 750 тис. доларів. Є відомості про проект в 20 млн. доларів, який окупився всього за 4 місяці. Інший приклад - річна економія 700 тис. доларів за рахунок впровадження Data Mining в одній з мереж універсамів у Великобританії.
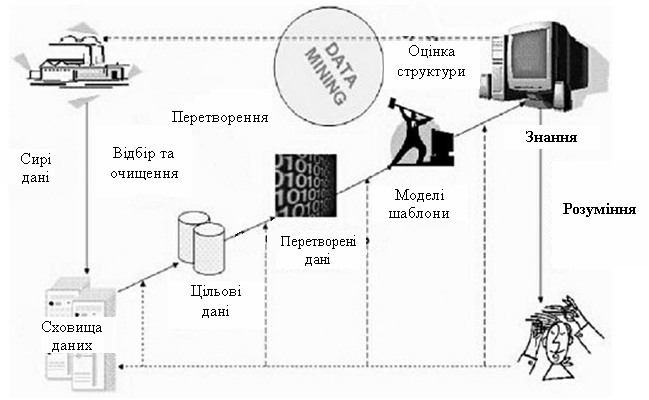
Рис. 2.17. Схема перетворення даних з використанням технології Data Mining
Компанія Microsoft офіційно оголосила про посилення своєї активності у області Data Mining. Спеціальна дослідницька група Microsoft, очолювана Усамой Файядом, і шість запрошених партнерів (компанії Angoss, Datasage, Epiphany, SAS, Silicon Graphics, SPSS) готують сумісний проект по розробці стандарту обміну даними і засобів для інтеграції інструментів Data Mining з базами і сховищами даних.
Data Mining є мультидисциплинарною областю, що виникла і прикладної статистики, що розвивається на базі досягнень, розпізнавання образів, методів штучного інтелекту, теорії баз даних і ін. (рис. 2.19). Звідси велика кількість методів і алгоритмів, реалізованих в різних діючих системах Data Mining. [Дюк В.А. <www.inftech.webservis.ru/it/datamining/ar2.html>]. Багато хто з таких систем інтегрує в собі відразу декілька підходів. Проте, як правило, в кожній системі є якась ключова компоненту, на яку робиться головна ставка.
Можна назвати п'ять стандартних типів закономірностей, що виявляються за допомогою методів Data Mining: асоціація, послідовність, класифікація, кластеризація і прогнозування.
Асоціація має місце в тому випадку, якщо декілька подій пов'язані один з одним. Наприклад, дослідження, проведене в комп'ютерному супермаркеті, може показати, що 55% що купили комп'ютер беруть також і принтер або сканер, а за наявності знижки за такий комплект принтера набувають в 80% випадків. Маючи в своєму розпорядженні відомості про подібну асоціацію, менеджерам легко оцінити, наскільки дієва знижка, що надається.
Якщо існує ланцюжок зв'язаних в часі подій, то говорять про послідовність. Так, наприклад, після покупки удома в 45% випадків протягом місяця отримується і нова кухонна плита, а в межах двох тижнів 60% новоселів обзаводяться холодильником.
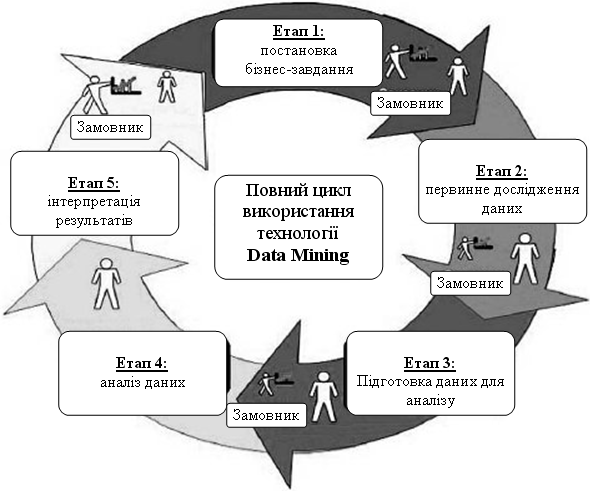
Рис. 2.18. Повний цикл застосування технології Data Mining
За допомогою класифікації виявляються ознаки, що характеризують групу, до якої належить той або інший об'єкт. Це робиться за допомогою аналізу вже класифікованих об'єктів і формулювання деякого набору правил.
Кластеризація відрізняється від класифікації тим, що самі групи наперед не задані. За допомогою кластеризації засобу Data Mining самостійно виділяють різні однорідні групи даних.
Статистичні пакети. Останні версії майже всіх відомих статистичних пакетів включають разом з традиційними статистичними методами також елементи Data Mining. Але основна увага в них приділяється все ж таки класичним методикам - кореляційному, регресійному, чиннику аналізу і іншим.
Недоліком систем цього класу вважають вимогу до спеціальної підготовки користувача. Також відзначають, що могутні сучасні статистичні пакети є дуже "важкоатлетами" для масового застосування у фінансах і бізнесі.
Є ще серйозніший принциповий недолік статистичних пакетів, що обмежує їх застосування в Data Mining. Більшість методів, що входять до складу пакетів, спираються на статистичну парадигму, в якій головними фігурантами служать усереднені характеристики вибірки. А ці характеристики при дослідженні реальних складних життєвих феноменів часто є фіктивними величинами. Це надзвичайна важлива обставина слід обов'язково враховувати при аналізі багатовимірних даних.
Як приклади найбільш могутніх і поширених статистичних пакетів можна назвати SAS (компанія SAS Institute), SPSS (компанія SPSS), STATGRAPHICS (компанія Manugistics), STATISTICA для WINDOWS, STADIA та інші. Ці пакети з успіхом можуть застосовувати невеликі і середні підприємства, а великі багатопрофільні компанії можуть інтегрувати їх в загальну корпоративну мережу.
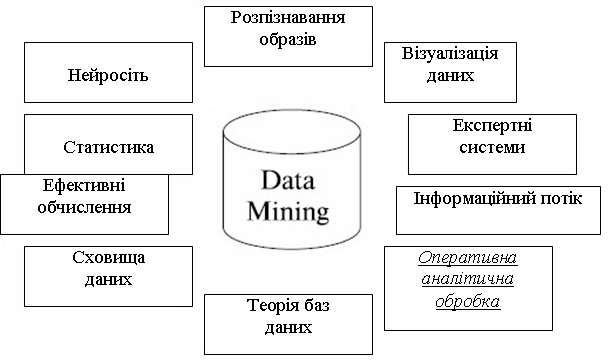
Рис. 2.19. Області застосування технології Data Mining