


www.basegroup.ru
Кроме того можно добавить в избранное текущий узел, выбрав соответствующее действие из всплывающего панели сценариев или главного меню.
Для перехода к избранному узлу нужно выбрать его из списка на главной панели приложения или из главного меню Избранное.
Пакетная обработка
Предположим, что в построенном дереве сценариев есть узлы, содержащие экспорт данных во внешние файлы. Для экспорта результатов обработки можно открыть файл проекта в Deductor Studio, в дереве сценариев найти и выполнить все узлы экспорта. Тогда данные, представленные таблицами, будут экспортированы во внешние файлы. Это способ экспорта «вручную».
Но можно воспользоваться пакетной обработкой файла проекта. Для этого необходимо выполнить команду вида:
<путь к программе> <путь к файлу проекта> /параметр_запуска /параметры_лога
Например,
"C:\Program Files\BaseGroup\Deductor\Bin\DStudio.exe" C:/project.ded /run
Эту команду можно сохранить и выполнить несколькими равнозначными способами.
Первый – это создать ярлык. Для этого в проводнике нужно нажать правой кнопкой мыши, выбрать пункт Создать и подпункт Ярлык, затем, нажав кнопку Обзор, выбрать путь к Deductor Studio и в конце строки дописать <путь к файлу проекта> /run.
Второй способ – это создать пакетный файл – файл с расширением .bat. В этом файле следует написать всего одну строчку: <путь к программе> <путь к файлу проекта> /параметр_запуска.
Параметр_запуска может принимать два значения:
§run. Этот параметр используется для автоматического экспорта данных из программы.
§teach. Этот параметр используется для переобучения моделей, используемых в сценарии. Обычно однажды построенная модель используется в дальнейшем без изменений. Но иногда она перестает давать хорошие результаты на новых данных. Тогда и следует воспользоваться пакетной обработкой с этим параметром.
Допустим, мы создали первым способом ярлык и назвали его Export. После его запуска файл проекта открывается в Deductor Studio, автоматически обнаруживаются все узлы с экспортом данных и выполняются все ветви сценария, содержащие такие узлы. После обработки всех узлов экспорта Deductor Studio закрывается.
В Deductor есть возможность управлять пакетной обработкой при создании сценария. Для этого у каждого узла предусмотрены два флага: «Выполнить» и «Переобучить» – доступные через пункт всплывающего меню Статус паке тной обработки. Если флажок «Выполнить» сброшен, то при запуске в пакетном режиме с параметром run узел и все его потомки исключаются из процесса выполнения. При установленном флаге узел выполняется в нормальном режиме. Сброшенный флаг «Переобучить» указывает системе, что при запуске с параметром teach переобучать узел не требуется. При установленном флаге узел будет переобучен. По умолчанию для вновь создаваемых узлов оба флага установлены, т.е. в пакетном режиме узел может и выполняться и переобучаться.
стр. 28 из 192

www.basegroup.ru
Параметры_лога предназначены для управления лог-файлом пакетной обработки. Они могут принимать следующие значения:
§/log – включить подробный режим лог-файла; в логе будет сохраняться информация о времени начала и окончания обработки каждого узла.
§/logfile=<Имя файла> – указывает имя лог-файла.
§/logmode[=overwrite] – определяет режим работы с лог-файлом, если указать =overwrite, то используется режим перезаписи лог-файла, в противном случае записи добавляются в конец существующего лог-файла.
Если в командной строке не указаны параметры управления лог-файлом, то используются настройки, сделанные в окне «Настройка», пункт главного меню Сервис ► Настройка.
Выполнить сценарии и переобучить модели можно еще двумя способами: воспользоваться Deductor Studio как OLE сервером или использовать Deductor Server. Для этого требуется программирование, поэтому применение Deductor в таких режимах описано в Руководстве разработчика.
стр. 29 из 192
www.basegroup.ru
Архитектура Deductor Warehouse –
многомерное хранилище данных
Многомерное представление данных
Deductor Warehouse 6 – многомерное хранилище данных, аккумулирующее всю необходимую для анализа предметной области информацию.
Начиная с пятой версии Deductor Warehouse, вся информация в хранилище хранится в структурах типа «снежинка», где в центре расположены таблицы фактов, а «лучами» являются измерения, причем измерение может ссылаться на другие измерения.
Группа товара
|
|
|
|
Товар |
|
Поставщик |
|
|
|
|
|
Количество Сумма к оплате Наценка 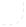
Клиент
Категория
Такая архитектура хранилища наиболее адекватна задачам анализа данных, т.к. аналитик на практике оперирует многомерными понятиями. Каждая «снежинка» называется процессом и описывает определенное действие, например, продажи товара, отгрузки, поступления денежных средств и прочее. В Deductor Warehouse 6 может одновременно храниться множество процессов, имеющие общие измерения, например, Товар, фигурирующий в Поступления и в Отгрузка.
Замечание
Отличие Deductor Warehouse версии 5 от версии 6 главным образом заключается во внутренней структуре хранения данных. Если в 5-й версии все данные процессов хранились в одной таблице, а данные измерений – в трех таблицах, то в 6-ой версии реализована полноценная ROLAP-модель (для каждого измерения и каждого процесса создается отдельная таблица). Достоинством 6-ой версии является значительно возросшая производительность. В то же время, любое серьезное изменение структуры хранилища в новой версии требует проведения операций по добавлению/удалению таблиц и столбцов.
стр. 30 из 192
www.basegroup.ru
Отгрузка
|
Номер счета |
|
|
|
Атрибуты |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Дата |
|
|
|
|
Количество |
|
|
|
|
|
|
|
|
|
|
|
Товар |
|
Группа товара |
|
|
|
Сумма к |
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
оплате |
|
|
|
|
|
Наценка |
Клиент |
|
Категория |
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
Поставщик |
|
|
|
|
|
|
|
|
|
|
Процесс |
|
Факты |
|
Измерения |
|
|
|
|
|
Измерения могут быть как простыми списками, например, Клиент, так и содержать дополнительные столбцы, называемые атрибутами измерений. Например, измерение Товар может состоять из Наименование товара - собственно измерение (первичный ключ) и Вес, Объем и прочее – атрибуты данного измерения.
Измерение может ссылаться на другое измерение, в свою очередь следующее измерение тоже ссылаться на измерение и так далее. Таким способом организуется иерархия измерений. Поддержку иерархий обеспечивает схема «снежинка». В Deductor Warehouse 6 поддерживаются только сбалансированные иерархии. Сбалансированной называется иерархия, где все ветви иерархии опускаются до одного уровня, и логическим «родителем» каждого элемента является уровень непосредственно над элементом. Например, последним уровнем иерархии Контрагенты может быть только клиент, и каждый клиент обязательно относится к одной из категорий клиентов. В несбалансированной иерархии количество уровней может быть разным, и конечный элемент иерархии может быть на любом из уровней.
Пример сбалансированной иерархии:
Контрагенты
Оптовая компания
Строительный комбинат
РязаньСтрой
Розничная компания
Магазин N1
Магазин N2
Категория |
Клиенты |
стр. 31 из 192