

www.basegroup.ru
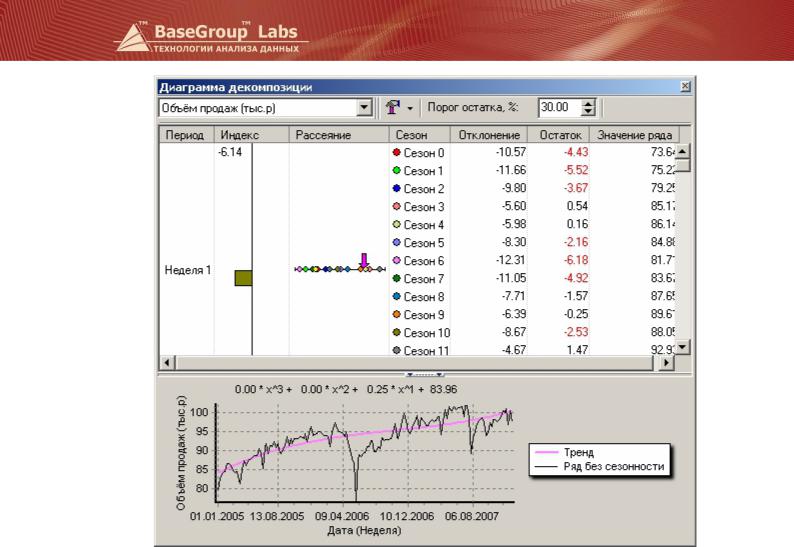
Остаток – величина, показывающая разность между значением отклонения и сезонным индексом в определённом временном интервале. В столбце Остаток красным цветом выделяются значения, превышающие значение сезонного индекса на величину большую порога остатка, соответственно, при изменении значения сезонного индекса изменяется и количество значений, выделенных красным.
На полученных в результате декомпозиции данных может быть построен прогноз.
Пользовательские модели
В процессе анализа данных встречаются такие ситуации, когда сложные модели, основанные на линейной регрессии и нейронных сетях, не могут описать предметную область. Например, в тех случаях, когда объем исходной выборки мал либо ее качество недостаточно для того, чтобы обучить нейронную сеть. Кроме того, иногда заранее известны модели некоторых процессов, т.е. описывающие их формулы и оценки коэффициентов. Например, в задачах оценки рисков существуют несколько хорошо известных моделей, в которые эксперту требуется лишь подставить коэффициенты, описывающие конкретную ситуацию. Для того чтобы дать аналитику возможность самому строить модели, основанные на экспертных оценках, в Deductor включен обработчик «Пользовательские модели».
Пользовательская модель позволяет на основании исходных данных и формул, указанных аналитиком, построить произвольную модель и работать с ней так же, как с моделями на основе, скажем, нейросетей. Примерами такой модели может служить модель прогноза на основе авторегрессии с коэффициентами, задаваемыми экспертом либо прогноз на основании скользящего среднего.
стр. 137 из 192

www.basegroup.ru
При создании пользовательской модели нужно пройти, в основном, те же шаги, что и при настройке других моделей Deductor.
Нормализация значений полей
Для полей, подаваемых на входы и выход дерева решений, настройки нормализации недоступны. Можно лишь посмотреть параметры нормализации, используемые по умолчанию, и гистограмму распределения выборки (описание в разделе по нейросети).
Задание модели
Задание формулы, по которой рассчитывается модель, производится в окне Калькулятора. В Deductor предусмотрены несколько стандартных моделей, включая скользящее среднее, авторегрессию, ARMA, ARIMA и др., которые можно использовать на этом этапе. Для этих моделей достаточно указать необходимые коэффициенты. Для того чтобы ввести в Калькуляторе
формулу одной из стандартных моделей, следует с помощью кнопки  Функция вызвать окно выбора функции. В разделе «Модели» будут представлены стандартные модели с описанием применения, формул и требуемых коэффициентов. Здесь нужно выделить название нужной модели и добавить ее в окно Калькулятора, нажав кнопку Ok. Теперь в формулу модели следует добавить нужные коэффициенты, и на этом создание модели закончено.
Функция вызвать окно выбора функции. В разделе «Модели» будут представлены стандартные модели с описанием применения, формул и требуемых коэффициентов. Здесь нужно выделить название нужной модели и добавить ее в окно Калькулятора, нажав кнопку Ok. Теперь в формулу модели следует добавить нужные коэффициенты, и на этом создание модели закончено.
Всписке доступных функций имеется большой набор стандартных математических, статистических, строковых и прочих функций. Любую из этих функций, а также стандартные математические операции можно использовать при построении пользовательской модели.
Вокне Калькулятор можно задавать формулы не только для полей, назначение у которых является выходным, но и добавлять новые поля. Разница состоит в том, что для выходных полей будут доступны визуализаторы группы Data Mining, предназначенные для оценки качества модели, – диаграмма рассеяния и таблица сопряженности. Создание модели с использованием выходных полей аналогично обучению нейросети с учителем, есть эталонные значения выходов
иесть выходы, рассчитанные моделью. Чем они ближе, тем лучше модель описывает исходную выборку данных. Диаграмма рассеяния и таблица сопряженности позволяют оценить степень близости эталонных и рассчитанных выходов, а, следовательно, качество модели. При добавлении же новых полей эталонных выходов нет, есть только рассчитанные моделью, и оценка качества модели с помощью подобных инструментов невозможна.
Визуализация
Для пользовательских моделей доступны три вида визуализаторов из группы Data Mining: диаграмма рассеяния, «Что-если» и таблица сопряженности. Первый из них позволяет оценить качество построенной модели по тому, насколько точно она описывает имеющиеся данные, если выходное полу является непрерывным. Второй дает возможность анализировать модель по принципу «что будет, если» и позволяет исследовать ее поведение при подаче на вход тех или иных данных. С помощью таблицы сопряженности можно сравнить значения дискретных выходных полей, рассчитанные моделью, с выходными значениями полей исходной выборки и определить, насколько точно выходы модели соответствуют эталонным значениям.
Пример
В качестве примера рассмотрим построение прогноза объемов продаж на основании короткого временного ряда. Пусть задан следующий временной ряд объемов продаж товара.
стр. 138 из 192

www.basegroup.ru
Дата |
|
Продажи |
|
|
|
|
|
01.01.04 |
|
118 |
|
|
|
|
|
01.02.04 |
|
129 |
|
|
|
|
|
01.03.04 |
|
143 |
|
|
|
|
|
01.04.04 |
|
136 |
|
|
|
|
|
01.05.04 |
|
145 |
|
|
|
|
|
01.06.04 |
|
138 |
|
|
|
|
|
01.07.04 |
|
142 |
|
|
|
|
|
Необходимо построить прогноз продаж на следующий месяц. Объем выборки очень мал, и построить качественный прогноз по ней нельзя. Тем не менее, даже не самый лучший прогноз зачастую бывает лучше, чем ничего. Воспользуемся для прогнозирования моделью скользящего среднего. Для начала преобразуем данные скользящим окном, указав глубину погружения 3. Таким образом, мы будем строить прогноз на основании данных за последние три месяца. На этом шаге получим следующие результаты:
Дата |
|
Продажи-3 |
|
Продажи-2 |
|
Продажи-1 |
|
Продажи |
|
|
|
|
|
|
|
|
|
|
|
01.03.2004 |
|
118 |
|
129 |
|
143 |
|
136 |
|
|
|
|
|
|
|
|
|
|
|
01.04.2004 |
|
129 |
|
143 |
|
136 |
|
145 |
|
|
|
|
|
|
|
|
|
|
|
01.05.2004 |
|
143 |
|
136 |
|
145 |
|
138 |
|
|
|
|
|
|
|
|
|
|
|
01.06.2004 |
|
136 |
|
145 |
|
138 |
|
142 |
|
|
|
|
|
|
|
|
|
|
|
Теперь построим пользовательскую модель. В качестве формулы, по которой будет рассчитываться модель, укажем следующую: Продажи = MOVINGAVERAGE(COL2B1;COL2B2;COL2B3).
Диаграмма рассеяния и диаграмма модели показаны на следующем рисунке.
стр. 139 из 192