


www.basegroup.ru
Очистка данных
Если анализируемые данные не соответствуют определенным критериям качества, то их предварительная обработка становится необходимым шагом для обеспечения удовлетворительного результата анализа. Необходимость в предварительной обработке возникает независимо от того, какие алгоритмы и технологии используются. Более того, эта задача может представлять самостоятельную ценность в областях, не имеющих непосредственное отношение к анализу данных. Очевидно, что исходные («сырые») данные чаще всего нуждаются в очистке.
Задач, решаемых на этапе очистки данных множество: аномалии, пропуски, шумы и прочие. Ниже описанные механизмы решения задач очистки данных, реализованные в Deductor.
Парциальная обработка
В процессе парциальной обработки восстанавливаются пропущенные данные, редактируются аномальные значения, проводится спектральная обработка. В Deductor Studio при этом используются алгоритмы, в которых каждое поле анализируемого набора обрабатывается независимо от остальных полей, то есть данные обрабатываются по частям. По этой причине такая предобработка получила название парциальной. В числе процедур предобработки данных, реализованных в Deductor Studio, входят сглаживание, удаление шумов, редактирование аномальных значений, заполнение пропусков в рядах данных.
Заполнение пропусков
Назначение
Часто бывает так, что в столбце некоторые данные отсутствуют в силу каких-либо причин (данные неизвестны, либо их забыли внести и т.п.). Раньше из-за этого пришлось бы убрать из обработки все строки, которые содержат пропущенные данные. Чтобы этого не происходило, в программе предусмотрено два способа заполнения пропущенных данных.
§Аппроксимация – пропущенные данные восстанавливаются методом аппроксимации.
§Максимальное правдоподобие – алгоритм подставляет наиболее вероятные значения вместо пропущенных данных.
Принцип работы
Метод аппроксимации используется только для упорядоченных данных, чаще всего это временные ряды. Этот метод использует последовательный рекуррентный фильтр второго порядка (фильтр Калмана). Входные данные последовательно подаются на вход фильтра, и если очередное значение ряда отсутствует, оно заменяется значением, которое экстраполируется фильтром.
Метод максимального правдоподобия рекомендуется использовать на неупорядоченных данных. При использовании этого метода строится плотность распределения вероятностей, и отсутствующие данные заменяются значением, соответствующим ее максимуму.
Пример
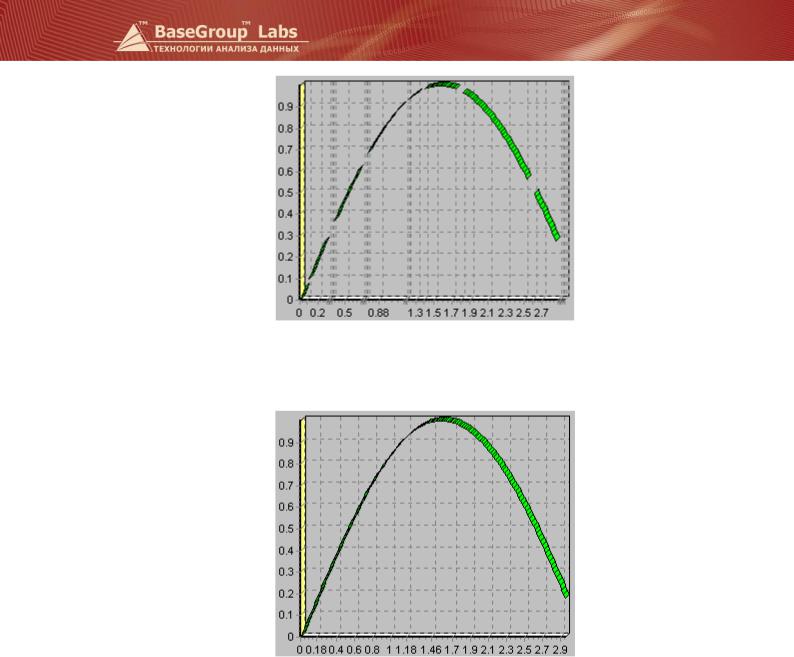
На рисунке представлены упорядоченные данные с пропусками.
стр. 69 из 192
www.basegroup.ru
После применения алгоритма аппроксимации эти данные выглядят так:
Редактирование аномалий
Назначение
Аномалии – это отклонения от нормального (ожидаемого) поведения чего-либо. Это может быть, например, резкое отклонение величины от ее ожидаемого значения.
Автоматическое редактирование аномальных значений осуществляется с использованием методов робастной фильтрации, в основе которых лежит использование робастных статистических оценок, таких, например, как медиана. При этом можно задать эмпирически подобранный критерий того, что считать аномалией. Например, задание в качестве степени подавления аномальных данных значения «слабая» означает наиболее терпимое отношение к величине допустимых выбросов.
Настройки
Для применения алгоритма удаления аномалий необходимо указать поле таблицы, к которому его нужно применить (которое содержит аномалии), и указать степень подавления аномальных данных – малую, среднюю или большую.
стр. 70 из 192
www.basegroup.ru
Пример
На рисунке приведен пример величины с аномалиями.
После применения алгоритма удаления аномалий та же величина представляется следующим образом:
Здесь была использована большая степень подавления аномалий.
Сглаживание
Для сглаживания рядов данных в программе используются два алгоритма.
Первый способ сглаживания – это низкочастотная фильтрация с использованием быстрого преобразования Фурье. При этом задается верхнее значение полосы пропускаемых частот, т.е. отсекается все, что выше данного порога. Высокочастотная составляющая временного ряда соответствует резко изменяющимся данным, а низкочастотная – плавно изменяющимся.
стр. 71 из 192
www.basegroup.ru
При подавлении шумов на основе анализа распределения составляющих Фурье спектра на выход фильтра пропускаются спектральные составляющие, превышающие некоторый порог, рассчитанный по эмпирическим формулам в соответствии с заданным критерием степени вычитания шума. Чем больше требуется сгладить данные, тем меньше должно быть значение полосы. Однако слишком узкая полоса может привести к потере полезной информации. Следует заметить, что этот алгоритм наиболее эффективен, если анализируемые данные являются суммой полезного сигнала и белого шума.
Второй способ сглаживания – это вейвлет-преобразование. Если выбран данный метод, то необходимо задать глубину разложения и порядок вейвлета. Глубина разложения определяет «масштаб» отсеиваемых деталей: чем больше эта величина, тем более «крупные» детали в исходных данных будут отброшены. При достаточно больших значениях параметра (порядка 7-9) выполняется не только очистка данных от шума, но и их сглаживание («обрезаются» резкие выбросы). Использование слишком больших значений глубины разложения может привести к потере полезной информации из-за слишком большой степени «огрубления» данных. Порядок вейвлета определяет гладкость восстановленного ряда данных: чем меньше значение параметра, тем ярче будут выражены «выбросы», и, наоборот, при больших значения параметра «выбросы» будут сглажены.
Пример
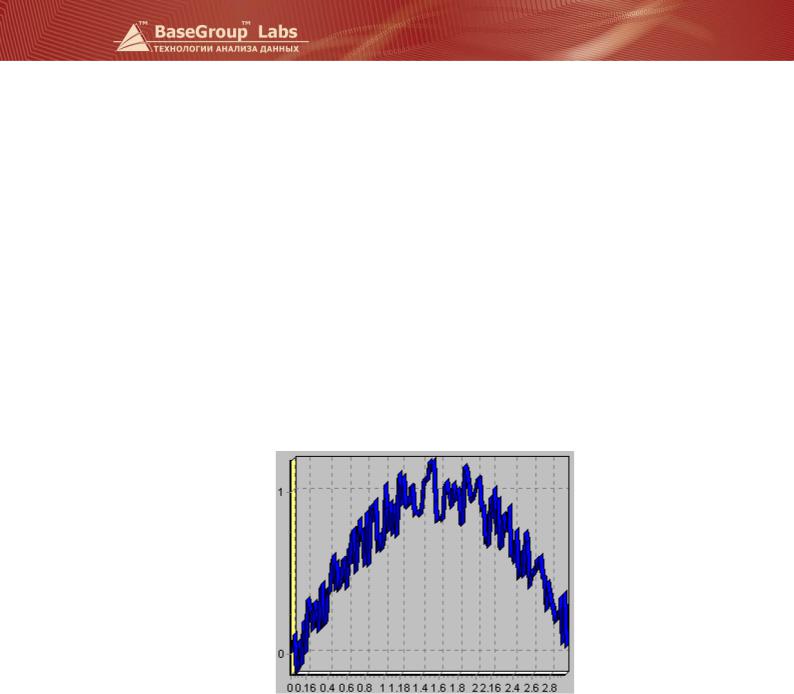
На рисунке показан пример данных с шумом.
На рисунке диаграмма после применения сглаживания с полосой пропускания равной 15.
стр. 72 из 192