


www.basegroup.ru
возникает необходимость экспортировать результаты прогноза во внешний файл. Но при прогнозировании мы добавили в результирующую выборку исходные данные. Это те строки таблицы, где значение поля «Шаг прогноза» равен пустому значению. Вызовем для узла разгруппировки обработку фильтрации и укажем в ней условие «Шаг прогноза не пустой». В результате будет получена таблица, готовая для экспорта. Вызовем для этого последнего узла фильтрации мастер экспорта и выберем источник, например, «Microsoft Excel». Далее следует указать экспортируемые поля таблицы. Укажем поля: «Количество», «Шаг прогноза» и «Наименование». В итоге будет сформирован файл Excel с прогнозными значениями количества продаваемого товара на следующие 4 недели.
Такую процедуру можно повторить на остальных группах товара. В результате всех этих действий будет получен сценарий прогнозирования объемов продаж.
Поиск оптимальной наценки
Предоставление скидки покупателям является стимулом для увеличения объемов закупок. Чем больше продается некоторого товара, тем больше прибыль. С другой стороны, чем больше предоставляется скидка, тем меньше наценка на товар, и тем меньше прибыли приносят продажи этого товара. Для нахождения оптимальной скидки необходимо построить модель зависимости спроса от процентной ставки скидки.
В нашем хранилище отсутствуют данные о скидке в процентах и прибыли, зато есть информация, с помощью которой их можно вычислить.
Импортируем в программу из хранилища все факты в разрезе измерений: Дата, Клиент, Товар,
Номер чека.
Применим к узлу обработку «Калькулятор». Назовем выражение «Скидка» и в окно формулы введем выражение соответствующее формуле:
Сумма скидки / (Сумма скидки + Цена).
Вводить выражение можно с помощью мыши, выбирая соответствующие поля в окне со списком столбцов. Затем добавим еще одно выражение, назвав его «Прибыль». В окне формулы необходимо ввести выражение, соответствующее формуле
Сумма наценки – Сумма скидки.
стр. 183 из 192
www.basegroup.ru
В формулах нельзя использовать метки полей, так как они описаны выше, нужно применять имена полей. Эти имена указаны рядом с метками в списке доступных полей. Таким образом формула
Сумма скидки / (Сумма скидки + Цена)
будет написана как
Discount_Sum / (Discount_Sum + Price).
В результате работы обработки в таблицу будет добавлено два поля Скидка и Прибыль.
Будем проверять гипотезу, что спрос зависит от абсолютной цены товара и процента скидки. Так как зависимость спроса от цены и скидки может быть нелинейной, воспользуемся нейронными сетями. Применим эту обработку к узлу с вычисляемыми данными. Укажем поле Скидка и Цена входным, а поле Прибыль – выходным. Остальные поля сделаем неиспользуемыми. Запустим алгоритм, оставив все остальные настройки без изменения. Оценить качество построенной зависимости можно с помощью диаграммы рассеяния. Если прогнозируемое алгоритмом значение прибыли разбросано относительно истинных значений, то необходимо изменить настройки нейросети, например, увеличив число слоев или нейронов в слое или изменив функцию активации.
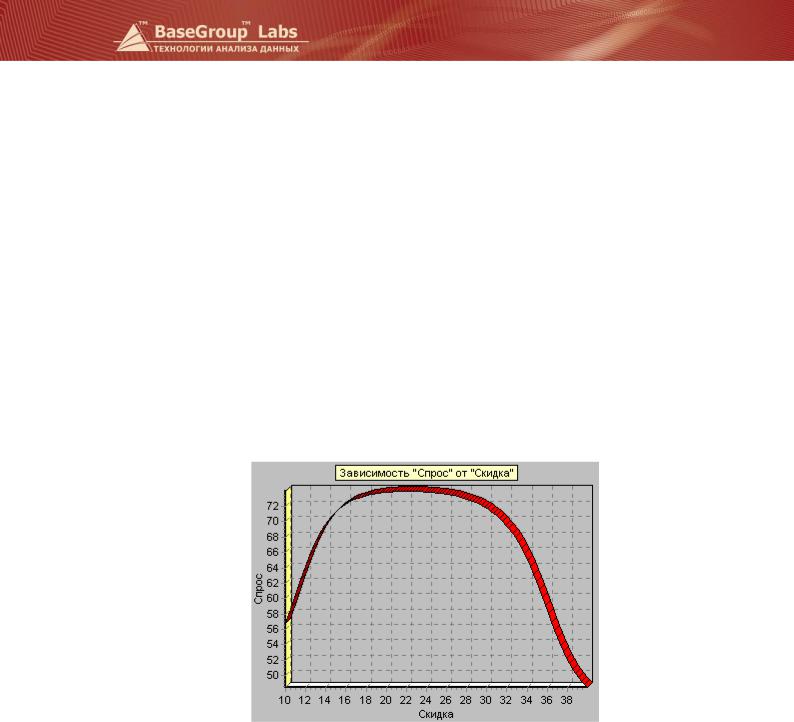
Нас же интересует результат, представленный диаграммой «Что-если».
Эта диаграмма наглядно показывает, при каком значении скидки с заданной ценой товара достигается максимум прибыли.
В результате сценарий будет выглядеть следующим образом.
стр. 184 из 192

www.basegroup.ru
Анализ потребительской корзины
Обычно клиенты покупают не один товар, а несколько. Причем эти товары могут быть каким-то образом взаимосвязаны. Например, человек, приобретающий дверь, скорее всего, купит еще и дверные ручки. А если он приобретает дверь конкретного вида, то и ручки он купит соответствующие этой двери. Зачем нужна такая информация? Например, для размещения товара на прилавках в виде, более удобном для покупателя. Зачем идти в другой конец магазина, чтобы посмотреть, какие ручки подойдут к понравившейся двери? Или другой вариант – покупатель приобрел дверь, но забыл про ручки, тогда продавец, зная такие правила приобретения товара, может сам их предложить.
Информация о товарах, приобретаемых совместно, содержится в нашем хранилище в поле «Номер чека». Найдем правила совместного приобретения товаров с помощью инструмента «Ассоциативные правила».
Импортируем в программу из хранилища количество товара в разрезе номера чека и товара. Применим к этому узлу ассоциативные правила. Полю «Номер чека» выберем назначение «Транзакция», а полю наименование – назначение «Элемент».
Выполним сначала алгоритм, не изменяя других настроек. После его выполнения возможны следующие варианты:
§Найдены только одноэлементные множества. Это факт видно на диаграмме на странице обучения в Мастере. На диаграмме будет отображен только один столбец. В этом случае нужно вернуться на шаг назад и уменьшить минимальную поддержку либо увеличить максимальную поддержку и так до тех пор, пока не будут получены двух и более элементные множества.
§Количество правил равно нулю, что отображается в соответствующем поле на странице обучения Мастера. Тогда нужно вернуться на шаг назад и уменьшить минимальную достоверность либо увеличить максимальную.
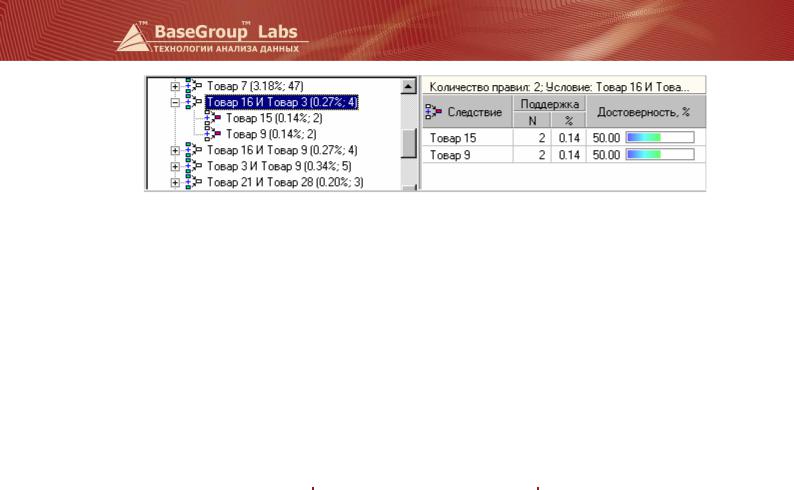
Врезультате будут получены ассоциативные правила, которые можно посмотреть с помощью визуализаторов «Правила», «Популярные наборы», «Дерево правил» и «Что-Если». Например, дерево правил может выглядеть так.
стр. 185 из 192
www.basegroup.ru
Если человек приобрел вместе Товар 16 и Товар 3, то он скорее всего купит еще и Товар 15 с достоверностью 50% и/или Товар 9 с достоверностью 50%.
Аналитическая отчетность
С помощью OLAP-куба можно быстро получать аналитические отчеты на основе данных, содержащихся в хранилище.
Проведем в качестве примера АВС-анализ клиентов. Для этого нам понадобится информация о продажах в разрезе клиентов. Вызовем мастер визуализации для узла «Вычисляемые данные: Скидка; Прибыль», созданный в разделе «Поиск оптимальной наценки». Выберем визуализатор «Куб». В настройках куба укажем, что поле Наименование клиента является измерением, а поле Прибыль –фактом. Разместим измерение в строках. Полученный куб будет выглядеть так:
Наименование |
|
Прибыль |
|
|
|
Клиент 11 |
|
11500 |
|
|
|
Клиент 14 |
|
10700 |
|
|
|
Клиент 2 |
|
12357 |
|
|
|
… |
|
… |
|
|
|
Эта таблица содержит всех клиентов. Чтобы оставить только клиентов группы А, нужно вызвать «Селектор», указать в нем фильтрацию факта Прибыль по измерению Наименование и выбрать «Сумма» в списке функций. В поле Условие выбрать «Доля от общего», а в поле Значение указать 50. После этого в таблице останутся только клиенты, приносящие в сумме 50% прибыли. Это и есть клиенты группы А. Если сделать то же самое, указав значение 80%, то будет получена таблица с клиентами групп А и В.
Аналогичный АВС-анализ можно провести и для товаров, то есть выделить наиболее выгодные товары.
Иногда перед построением куба требуется некоторая предобработка данных. Например, нужно отследить постоянных, новых и утерянных клиентов. Это можно сделать, основываясь на информации о количестве обращений клиентов в месяц. Например, если клиент на протяжении нескольких месяцев не обращался в организацию, то его будем считать утерянным. Если клиент обращается примерно одинаковое число раз каждый месяц, то его можно считать постоянным.
Применим к узлу «Вычисляемые данные: Скидка; Прибыль» преобразование даты и заменим дату покупки месяцем этой даты. Для нового узла выберем визуализатор «Куб». Укажем в нем измерения Дата (Год+Месяц), Наименование, а факт – Номер чека. Для факта сразу выберем функцию агрегации Количество. Разместим Наименование в строках, а Дата (Год+Месяц) – в столбцах. Полученная таблица будет иметь вид.
стр. 186 из 192