

www.basegroup.ru
В результате будет получена таблица следующего содержания:
Кубы в хранилище данных
В Deductor Warehouse кроме импорта из процесса/измерения имеется возможность «доставать» информацию из так называемых кубов, которые представляют собой заранее настроенные срезы процесса. Они «обсчитываются» заранее и хранятся в отдельных таблицах, поэтому операция импорта из куба выполняется значительно быстрее, чем непосредственно из процесса. Кубы полезны, когда в хранилище миллионы записей, а время отклика на запрос критично и нужно его минимизировать. В этом случае выгодно настроить срез в виде куба. Недостатком подхода является то, что при любом добавлении данных в процесс куб приходится заново «пересчитывать», что требует определенного времени. Тем не менее, если эти регламентные процедуры проводятся, скажем, в ночное время, то особой проблемы это не вызывает.
Пример
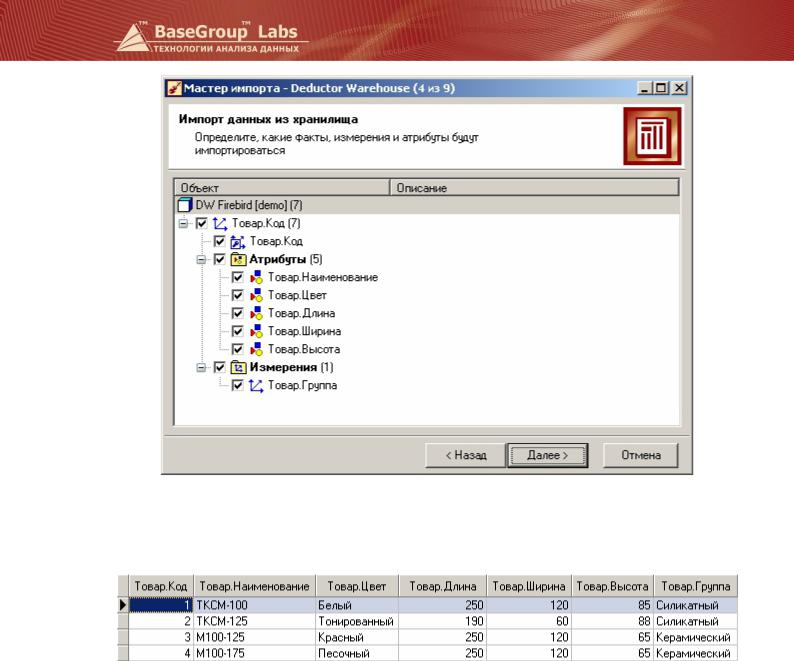
Настроим куб, в котором будет храниться информация об отгрузках по клиентам за последнюю неделю. Откроем «Редактор метаданных», войдем в режим редактирования и добавим куб. Шаги по его созданию аналогичны шагам импорта из процесса. Выберем измерения Клиент и Дата, все доступные факты и по измерению Дата настроим статический фильтр с условием «последний» и значением «неделя от имеющихся данных».
стр. 50 из 192
www.basegroup.ru
Дадим кубу название Отгрузка за неделю. В редакторе для него стал доступен специфичная опция в виде флага Автоматиче ское обновление. Поднятый флаг говорит о том, что при попадании новых данных в процесс куб будет автоматически пересчитываться, при этом в поле «Время последнего обновления» будет заноситься дата и время последнего обновления.
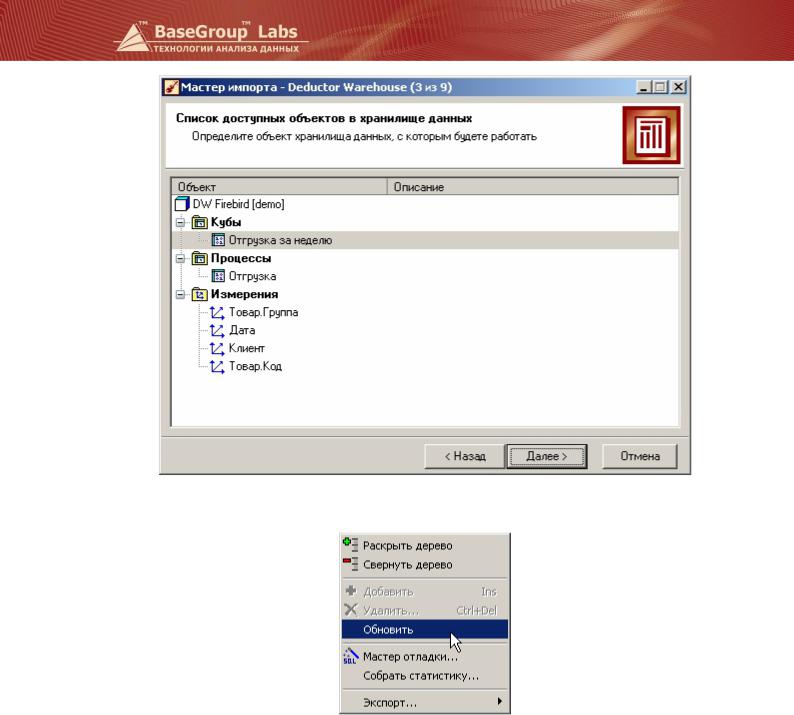
Теперь куб готов к работе. В сценарии при вызове мастера импорта из хранилища помимо процесса и измерения появится возможность выбрать куб.
стр. 51 из 192
www.basegroup.ru
Имеется возможность принудительно перестроить куб. Для этого в Редакторе метаданных нужно встать на нужный объект и в контекстном меню нажать кнопку Обновить.
стр. 52 из 192
www.basegroup.ru
Виртуальное хранилище Virtual Warehouse
В случае отказа от традиционного хранилища данных альтернативой является применение
виртуального хранилища данных – Virtual Warehouse 5.
Отличие здесь в том, что данные из учетных систем не переносятся в специальную базу данных, а извлекаются и преобразуются к требуемому виду непосредственно при выполнении аналитических запросов к учетной базе данных. Пользователь работает с Virtual Warehouse через такой же семантический слой, как и в случае с традиционным хранилищем, т.е. он оперирует многомерными понятиями, хотя обращается к обычной реляционной базе данных, не ориентированной на аналитическую обработку.
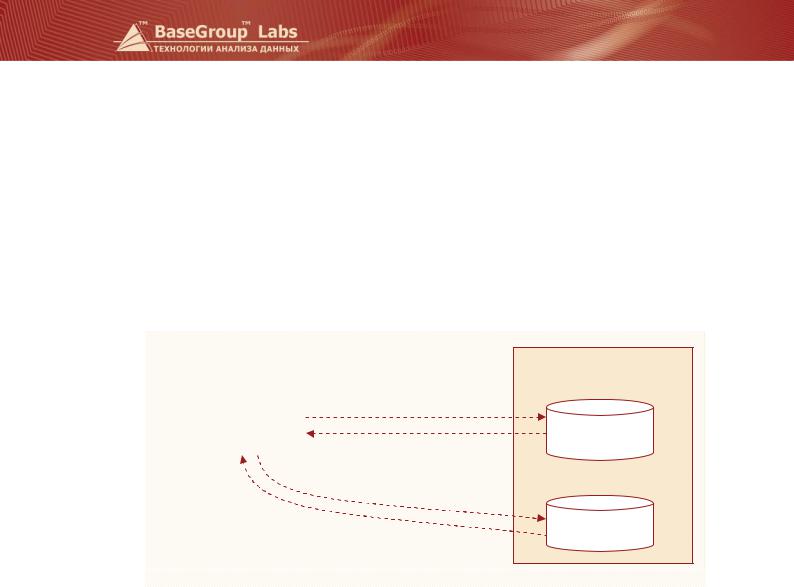
Виртуальное хранилище данных – это логически единый источник информации, включающий в себя базу данных с анализируемыми сведениями и разработанный для нее семантический слой, хранящийся отдельно.
|
Виртуальное хранилище |
|
|
данных |
|
Deductor |
1 – Мастер импорта |
|
Метаданные |
||
Studio |
||
|
2 – SQL-запрос |
3 – SQL-запрос
База данных
4 – выборка
Работа с настроенным виртуальным хранилищем происходит следующим образом. Cначала с помощью Мастера импорта в Deductor Studio пользователь задает информацию, которую он хочет получить из хранилища данных. Система самостоятельно «за кулисами» формирует SQL запрос к базе данных. Мастер импорта как бы помогает «перевести» то, что хочет получить аналитик (который рассуждает в терминах измерения, факт, процесс) на язык SQL. Дальше этот SQL-запрос выполняется (идет обращение к базе данных), подписываются нужным образом поля, производятся другие вспомогательные операции, и результат становится доступен пользователю, который «видит» данные через семантический слой виртуального хранилища данных.
Достоинства Virtual Warehouse:
§Минимизация дискового пространства.
§Пользователь оперирует данными на семантическом уровне.
§Быстрота настройки и запуска.
§Работа с текущими, детализированными данными.
Недостатки Virtual Warehouse:
§Увеличивается время обработки запросов.
§Время обработки запросов к виртуальному хранилищу данных может значительно превышать соответствующие показатели для традиционного хранилища. Структуры оперативных баз данных, рассчитанные на интенсивное обновление одиночных записей, в высокой степени нормализованы. Для выполнения же аналитического запроса требуется объединение большого числа таблиц, что также приводит к снижению быстродействия.
стр. 53 из 192
www.basegroup.ru
§Увеличивается нагрузка на учетные системы, т.к. база данных должна обеспечивать как текущую обработку транзакция, так и выполнение ресурсоемких аналитических запросов.
§Требуется постоянная доступность всех источников данных.
§Временная недоступность хотя бы одного из источников может привести либо к невыполнению аналитических запросов, либо к неверным результатам.
§Отсутствие единого непротиворечивого взгляда на объект управления. Это случается при наличии нескольких учетных систем, когда информация между ними обновляется асинхронно.
Deductor Studio имеет встроенную реализацию виртуального хранилища данных – Virtual Warehouse 5. Для аналитика работа с таким хранилищем в плане пользовательского интерфейса абсолютно идентична работе с традиционным хранилищем. Исключена только возможность загрузки информации в виртуальное хранилище данных.
Проектирование семантического слоя Virtual Warehouse относится скорее к задаче подключения к источнику данных и требует квалификации администратора базы данных и знания языка SQLзапросов. Эта работа должна выполняться специалистом с соответствующей подготовкой. Вопросы настройки Virtual Warehouse подробно освещены в специальном руководстве по настройке виртуального хранилища данных, поставляемым с системой.
Примечание
Возможность работы с Virtual Warehouse имеется только в Deductor Enterprise.
стр. 54 из 192