

www.basegroup.ru
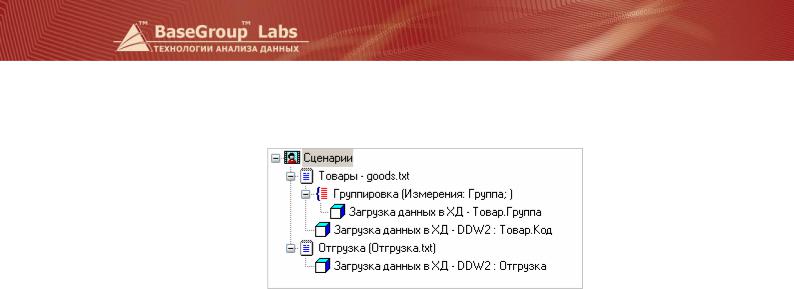
Таким образом, мы создали структуру хранилища и загрузили данные об отгрузках товара. Окончательный сценарий описанных действий, состоящий из 6 узлов, приведен на рисунке.
Автоматическая загрузка данных в хранилище
Информация в хранилище данных должна постоянно обновляться, поэтому этот процесс нуждается в автоматизации. Для этих целей в Deductor включены средства автоматического выполнения сценариев.
В сценарии проекта загрузки данные импортируются из различных источников и экспортируются в измерения и процессы хранилища. Для автоматического обновления хранилища данных имеется возможность выполнить действия по загрузке в пакетном режиме.
Пример
Продолжим пример из предыдущего раздела.
Сохраним созданный сценарий выгрузки данных в хранилище под именем load.d ed в корне диска C:. Теперь создадим ярлык, в котором укажем команду:
"C:\Program Files\BaseGroup\Deductor\Bin\DStudio.exe" C:\load.ded /run
При запуске данного ярлыка будет осуществляться автоматическая загрузка данных в хранилище.
Кроме пакетного выполнения в Deductor Studio, автоматически выполнить сценарий можно при помощи Deductor Server. Подробнее работа с сервером описана в «Руководстве администратора».
Импорт данных из хранилища
Импорт данных из хранилища производится с помощью мастера импорта, в котором необходимо выбрать в качестве типа источника данных Deductor Warehouse.
Для начала нужно выбрать хранилище данных, из которого требуется выполнить импорт. В окне выбора хранилища данных представлены две колонки «Хранилище данных» и «Описание». В колонке «Хранилище данных» указывается имя хранилища, под которым оно зарегистрировано в системе, а в списке «Описание» (это необязательный параметр) – краткая характеристика содержимого хранилища, которая вводилась при его создании.
На следующем шаге необходимо определиться что будем импортировать процесс или измерение. И то и другое отображается в списке доступных объектов Deductor Warehouse.
Импорт процесса
Если интересует процесс, то его нужно выбрать на странице со списком объектов хранилища данных. Информация, относящаяся к какому-либо объекту или бизнес-процессу, представлена в
стр. 45 из 192

www.basegroup.ru
хранилище в виде «снежинки», где в центре расположены таблицы фактов, а «лучами» являются измерения, причем «лучи» могут ссылаться на другие «лучи». Каждая такая структура называется процессом. В общем случае, таких процессов в хранилище содержится несколько. Поэтому каждый раз при обращении к хранилищу необходимо выбрать процесс, из которого должны импортироваться данные.
Далее нужно определить, какие измерения, атрибуты и факты из выбранного на предыдущем шаге процесса должны быть импортированы. Это необходимо потому, что процесс может содержать множество измерений и фактов, а пользователю будут нужны только некоторые из них. Выбор только тех измерений и фактов, которые нужны в данном случае, позволит сэкономить время при импорте данных и избежать появления ненужной информации в выборке.
Все объекты выбранного процесса представлены в виде дерева, где атрибуты, измерения и
факты образуют ветви. Атрибуты обозначены значком  , измерения –
, измерения – , а факты –
, а факты –  . Слева от каждого объекта расположен флажок. Установка флажка позволяет выбрать соответствующий атрибут, измерение или факт процесса для импорта, а сброс флажка, наоборот, исключает их из числа импортируемых. Кроме этого, с измерением могут быть связаны один или несколько атрибутов измерения. В этом случае атрибуты образуют подветвь ветви измерения, где каждый
. Слева от каждого объекта расположен флажок. Установка флажка позволяет выбрать соответствующий атрибут, измерение или факт процесса для импорта, а сброс флажка, наоборот, исключает их из числа импортируемых. Кроме этого, с измерением могут быть связаны один или несколько атрибутов измерения. В этом случае атрибуты образуют подветвь ветви измерения, где каждый
атрибут обозначен значком  .
.
Далее требуется задать срезы, т.е. указать значения измерений и/или атрибутов, выбранных на предыдущем шаге, которые будут импортированы. Этот шаг желателен, потому что количество значений измерения может быть очень большим, а загрузка всех значений нецелесообразна.
Поэтому выбор только тех значений измерения, которые представляют интерес в данном случае, поможет сэкономить время загрузки данных и не будет загромождать полученную выборку. Чтобы задать параметры среза для данного измерения или атрибута, необходимо выделить его в
дереве объектов, выбрать условие и щелкнуть по кнопке выбора значений . В результате откроется диалоговое окно, в котором нужно задать параметры фильтрации.
. В результате откроется диалоговое окно, в котором нужно задать параметры фильтрации.
Список условий содержит несколько значений, основные из которых следующие:
§<пусто> – фильтрация по указанному объекту не производится;
§= – указывается значение, которое нужно импортировать;
§<> – указывается значение, которое не нужно импортировать;
При фильтрации по значению в диалоговом окне отображается список всех значений данного измерения, из которого нужно выбрать единственный вариант.
§в списке – указываются значения, которые входят в список импортируемых;
§вне списка –- указываются значения, которые не входят в список импортируемых.
Вслучае фильтрации по списку в диалоговом окне будет представлен список всех значений данного измерения. Чтобы выбрать значение, достаточно выделить его щелчком мыши (или установить флажки напротив тех значений, которые интересуют).
§содержит – указывается подстрока, которая должна содержаться в импортируемых значениях измерений;
§не содержит – указывается подстрока, которая не должна содержаться в импортируемых значениях измерений;
§начинается на – указывается подстрока, с которой должны начинаться импортируемые значения измерений;
§начинается на – указывается подстрока, с которой не должны начинаться
импортируемые значения измерений;
§заканчивается на – указывается подстрока, на которую должны заканчиваться
импортируемые значения измерений;
§не заканчивается на – указывается подстрока, на которую не должны заканчиваться
импортируемые значения измерений;
стр. 46 из 192

www.basegroup.ru
Для измерений типа вещественное и целое число дополнительно доступны следующие основные фильтры:
§<, <=, >, >= – соответствующие операции сравнения чисел;
§в интервале – выбираются значения, попадающие в заданный числовой интервал;
§вне интервала – выбираются значения за пределами заданного числового интервала;
Для измерений типа дата/время дополнительно доступны следующие основные фильтры:
§в интервале – выбираются записи, для которых измерение лежит в заданном диапазоне дат;
§вне интервала – выбираются записи, для которых измерение не входит в заданный диапазон дат;
§последний – выбираются записи, для которых измерение лежит в указанном промежутке времени (промежуток задается), предшествующем указанной дате;
§не последний –- выбираются все записи, кроме тех, для которых измерение лежит в указанном промежутке времени, предшествующем указанной дате.
На этом же шаге мастера имеется возможность настроить динамические срезы в перечисляемом списке Т ип фильтра. В нем три установки:
§статический фильтр – срез не меняется ни при каких условиях;
§пользовательский фильтр – при каждом выполнении узла импорта пользователю будет выводиться окно, в котором он сможет указать требуемые разрезы по измерению(измерениям);
§фильтр с использованием переменных – значения для формирования срезов будут браться из переменных проекта Deductor или переменных приложения (см. раздел «Использование переменных»).
Последние две настройки позволяют строить динамические отчеты, в которых пользователю предоставляется только интересующая его информация, а конкретные условия фильтрации он выбирает в момент импорта данных, либо условия фильтрации передаются через переменные при пакетном/серверном запуске сценария.
Например, пользователю требуется получать информацию об отгрузках по каждому дилеру. Можно было бы подготовить отдельную ветку сценария и отчеты по каждому дилеру, либо фильтровать по дилеру в кубе. Однако первый вариант не подходит из-за того, что число дилеров может быть очень большим либо постоянно меняться. Тогда пришлось бы каждый раз перестраивать систему отчетов. С помощью динамического фильтра можно эффективно решать подобные проблемы. На этапе импорта данных из хранилища пользователь сам сможет указать, в каком именно разрезе ему нужны данные, и работать только с ними. При этом для всех возможных разрезов готовятся всего один сценарий обработки и одна система отчетов.
Пример
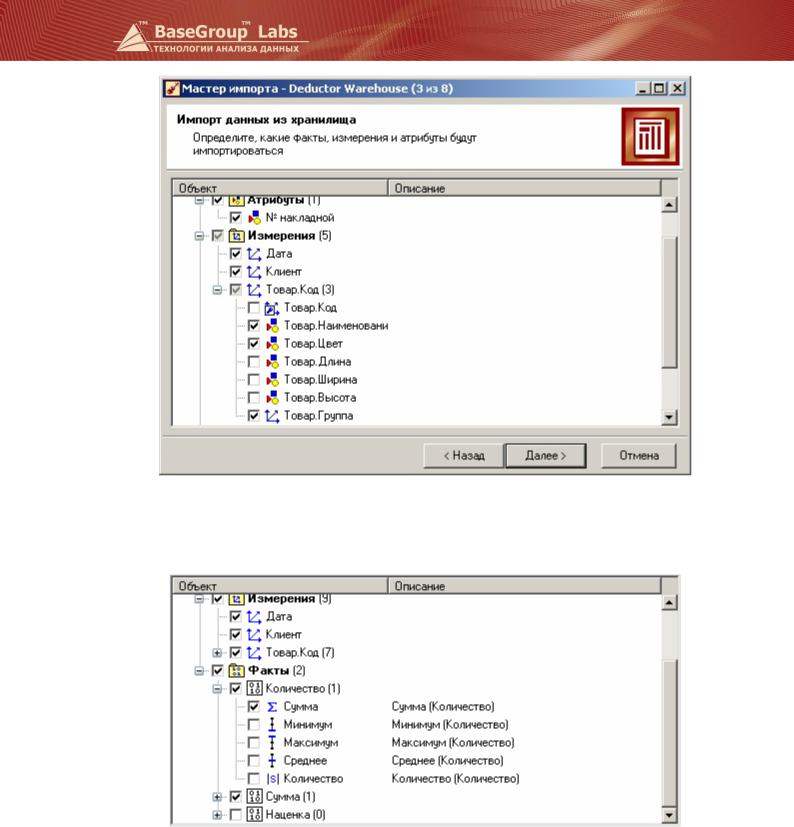
Импортируем из хранилища данные о количестве отгруженного товара в разрезе дат и товаров по клиенту ОАО «ССК», оставив атрибут товара Цвет. Вызовем мастер импорта и выберем источник «Deductor Warehouse». Далее выберем наше хранилище из списка и процесс Отгрузка. Отметим измерения, импортируемые из хранилища, как показано на рисунке (атрибут «№ накладной» импортировать не будем). Обратите внимание, что в измерении Товар.Код имеется возможность выбрать товарную группу (иллюстрация иерархии).
стр. 47 из 192
www.basegroup.ru
Далее укажем импортируемые факты (факт – количество, вариант агрегации – сумма).
На последнем шаге зададим статический фильтр по клиенту.
стр. 48 из 192