

www.basegroup.ru
Отфильтрованные измерения выделяются красным фоном. Выбирать фильтруемые значения можно и для скрытых измерений.
Способы агрегации и отображения фактов
Предусмотрено несколько способов агрегации фактов в кросс-таблице:
§сумма – вычисляется сумма объединяемых фактов;
§минимум – среди всех объединяемых фактов в таблице отображается только минимальный;
§максимум - среди всех объединяемых фактов в таблице отображается только максимальный;
§среднее – вычисляется среднее значение объединяемых фактов;
§количество – в кубе будет отображаться количество объединенных фактов.
Для изменения способа агрегации фактов нужно вызвать окно «Настройка фактов», нажав кнопку
на панели инструментов.
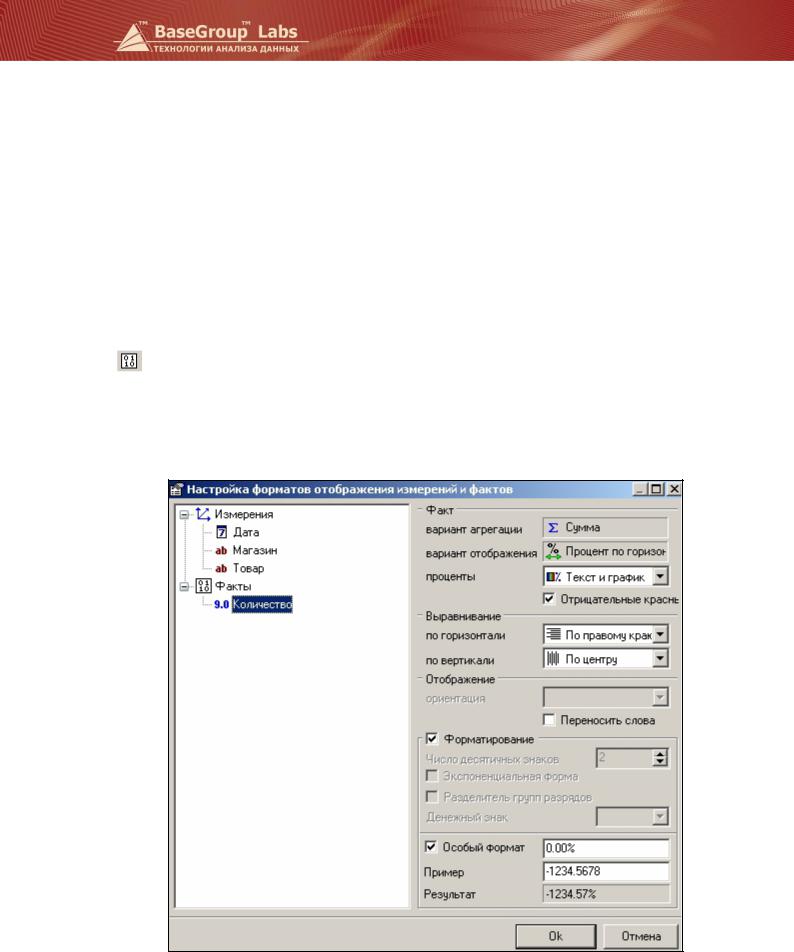
В кубе по умолчанию факты отображаются с двумя знаками после запятой и выровнены по правому краю ячейки. Доступна возможность изменить форматирование ячеек таблицы, вызвав
окно «Настройка форматов» (кнопка  на панели инструментов).
на панели инструментов).
Пример окна на рисунке.
Назначение полей следующее:
стр. 60 из 192
www.basegroup.ru
§Проценты – в случае отображения процентов по горизонтали или вертикали, можно задать способ представления в кубе в виде числа, графика или комбинации числа и графика.
§Отрицательные красным – отображение красным цветом отрицательных значений фактов.
§Выравнивание – определяет выравнивание значений в ячейках по горизонтали и вертикали. Может принимать значения: «По левому краю», «По центру», «По правому краю»;
§Отображение – задает ориентацию меток текста (повороты на 90 и 270 градусов) и опцию переноса по словам при недостатке ширины поля;
§Форматирование – применить особое форматирование или оставить все как есть;
§Число десятичных знаков – определяет число знаков после запятой;
§Экспоненциальная форма – если установлен, то число будет отображаться в экспоненциальной форме. Например, число 153,47 будет выглядеть 1,5347Е+2;
§Разделитель групп разрядов – отображать или не отображать разделитель разрядов, т. е. число может выглядеть так 1289 или так 1,289;
§Денежный знак – можно в конце значения добавить знак денежной единицы;
§Особый формат – позволяет задать формат с помощью строки формата. В поле «Результат» отображается результат применения формата к числу, введенному в поле «Пример».
Селектор – фильтрация данных в кубе
Селектор является мощным средством фильтрации данных в кросс-таблице. Фильтрация может производиться двумя способами:
по значениям фактов;
по значениям измерений путем непосредственного выбора значений из списка или отбора их по условию. Фильтрация задается отдельно по каждому измерению.
Чтобы приступить к работе с селектором, достаточно на панели инструментов нажать на кнопку  Селектор…, после чего будет открыто окно селектора.
Селектор…, после чего будет открыто окно селектора.
В окне селектора слева отображаются поле «Факты» и все доступные измерения.
стр. 61 из 192

www.basegroup.ru
Это пример окна для фильтрации данных по значениям фактов. В этом случае в правой части окна задаются следующие параметры:
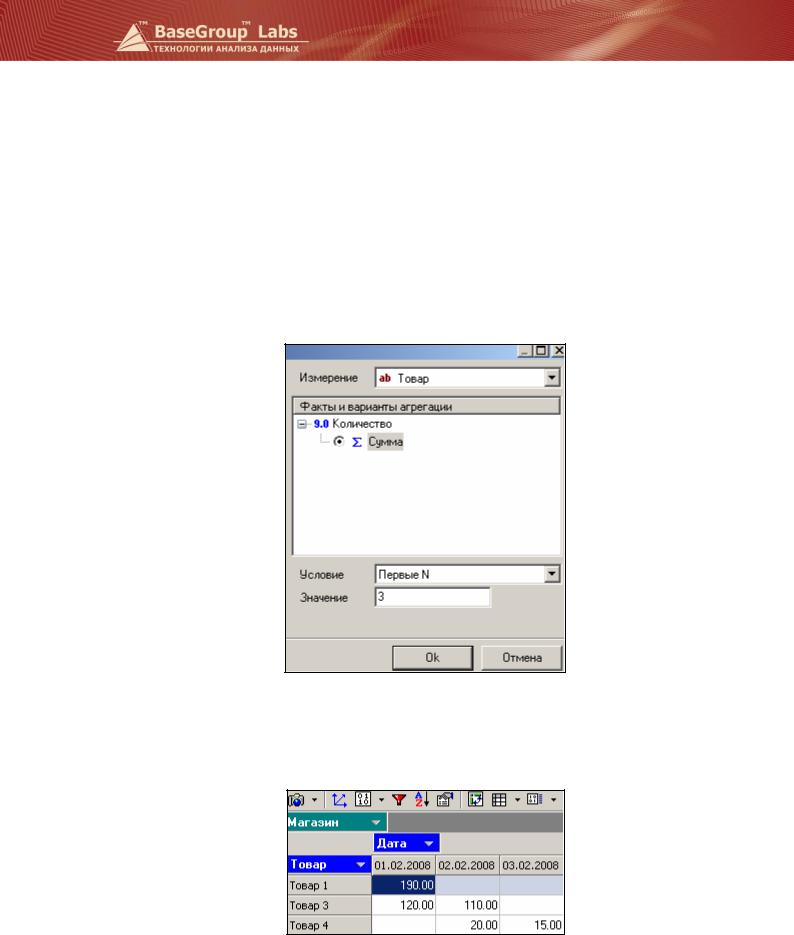
§Измерение. Фильтрация подразумевает, что в таблице останется лишь часть значений некоторого измерения. Это поле как раз и задает измерение, значения которого будут отфильтрованы;
§Факты и вариант агрегации. В кубе может содержаться один и более фактов. Фильтрация будет происходить по значениям выбранного здесь факта. К нему будет применена функция агрегации, в соответствии с которой следует выполнить отбор записей. В результате будут выбраны только те записи, агрегированные значения которых удовлетворяют выбранному условию;
§Условие. Условие отбора записей по значениям выбранного факта.
Поле «Условие» может принимать следующие значения:
§Первые N. Значения измерения сортируются в порядке убывания факта, и выбираются первые N значений измерений. Таким образом, можно, например, находить лидеров продаж – первые 10 наиболее продаваемых товаров, или первые 5 наиболее удачных дней;
§Последние N. Значения измерения сортируются в порядке убывания факта, и выбираются последние N значений измерений. Например, 10 наименее популярных товаров;
§Доля от общего. Значения измерения сортируются в порядке убывания факта. В этой последовательности выбирается столько первых значений измерения, что они в сумме давали заданную долю от общей суммы. Например, можно отобрать клиентов, приносящих 80% прибыли – группа А по АВС классификации;
§Диапазон. Результатом отбора будут записи, для которых значение соответствующего факта лежит в заданном диапазоне;
§Больше. Будут отобраны записи, значение соответствующего факта для которых будет больше указанного значения;
§Больше или равно. Будут отобраны записи, значение соответствующего факта для которых будет больше или равно указанного значения;
стр. 62 из 192
www.basegroup.ru
§Меньше. Будут отобраны записи, значение соответствующего факта для которых будет меньше указанного значения;
§Меньше или равно. Будут отобраны записи, значение соответствующего факта для которых будет меньше или равно указанного значения;
§Равно. Будут отобраны записи, значение соответствующего факта для которых будет равно указанному значению;
§Не равно. Будут отобраны записи, значение соответствующего факта для которых будет не равно указанному значению.
Пример фильтрации по фактам
Пусть нам нужно определить товары, пользующиеся наибольшим спросом. Исходный куб содержит 4 товара. Применим к нему селектор.
При проведении данной операции значок фильтра становится красным  .В результате получим 3 наиболее популярных товаров.
.В результате получим 3 наиболее популярных товаров.
Такую выборку можно получить по любому факту. В данном примере это количество. Поэтому мы наблюдаем наиболее продаваемые товары.
стр. 63 из 192